I. Введение
Рептилия является использование большого количества кода, который будет загружен с веб-фронтального код, используя программу, которая, в общем, общих целей, для которых:
1, использование бизнес-анализа: многие крупные компании будут в дополнение к данным с использованием поисковых систем для анализа и обработки данных, например, чтобы понять динамику цен местного жилья второй стороны в Гуанчжоу будет цена на сайте жилищного агентства пойти ползать местный список в квадратных метрах
2, тренажер: машинное обучение требует много данных, хотя есть много бесплатных библиотек в сети может обеспечить обучение, учебные материалов для частей машины, но они нуждаются в относительно новых, поэтому необходимо подняться принимать данные в режиме реального времени
3, практика гусеничный технологии: Многие веб-обходчик на самом деле не коммерческая цель, но программисты использовали на практике с
4, другие программы, такие как: поисковые системы, такие процедуры должны также использовать технологию гусеничной для выполнения своей функции
Общие Интернет, особенно большие страницы, будет механизм анти-рептилии, причина в следующем:
1, пресмыкающиеся занимают много ресурсов сервера, что приводит к увеличению эксплуатационных расходов на интернет-компаний, и будет влиять на нормальное использование пользователя
2, часть деловой информации является ценной, не хочет быть коммерческими конкуренты принимают использовать, например, обзоры ресторанов или перечисления на
Ниже то, что я вижу на веб-сканерам и анти рептилии краткого введения, я чувствую себя довольно хорошо
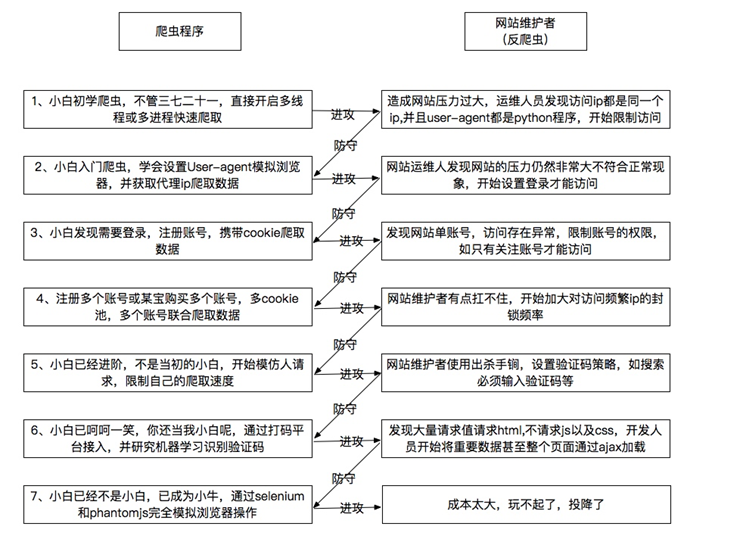
Многие сайты, основанные на опыте пользователя, не требует от пользователей войти в систему, но не нужно вводить код проверки и т.п., является более распространенным, чтобы сделать преобразование нерегулярный передний и ID, чтобы вы ползать трудности, то в зависимости от состояния браузера IP блокировать

Во-вторых, основные шаги рептилии
Рептилии много способов, но в принципе не может избежать этих шагов
1、找寻URL:每个网页都有个URL,爬虫首先要知道这个网页的URL才能去抓取这个网页的资料,URL里面最重要的就是它里面的ID,像是豆瓣里面,盗梦空间的ID为3541415,蝴蝶效应为1292343,阿凡达为1652587,所有如果我们写程序将ID0-9999999的页面全部爬取完,就可以获得所有豆瓣上的资料,但其实里面大部分的ID都是没有内容的页面,这会大幅度降低我们爬虫的效率,另外一种方式是利用前端代码里面的URL找寻目标,一般来说,像是淘宝首页,会有许多的URL可以抓取,而进入商品网页后又有相关商品的URL可以抓取,利用这种方式可以高效的抓取URL,但缺点是抓不全,而且容易陷入循环,抓取重复的URL。
下图为搜狐新闻的网页,利用查看可以很快的看到新闻URL的位置
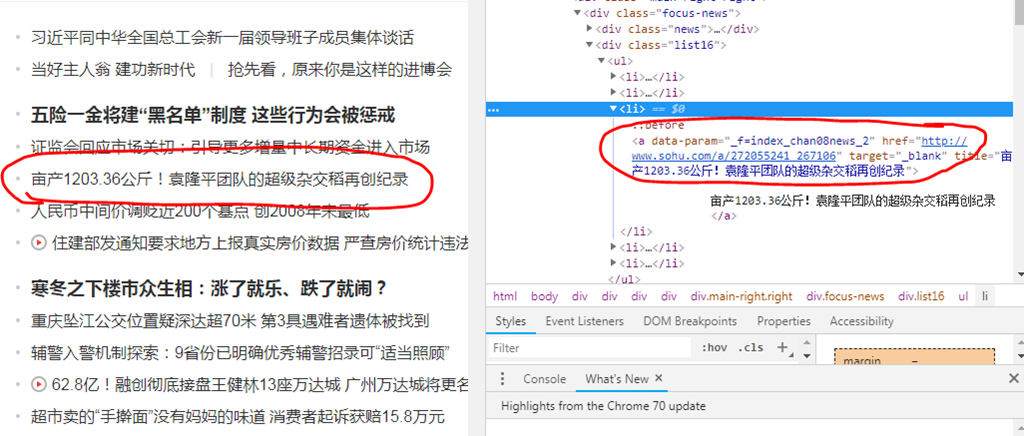
利用复制下几个新闻链接的XPATH,可以发现其规律,再利用XPATH去抓这些URL,这边由于搜狐在前端有加了反爬虫的机制,所以比较难一次爬全,需要多尝试几种XPATH才能获得首页所有的新闻链接,下面的代码可以帮助获取首页部分的新闻URL位置
def link_list(): url = 'http://news.sohu.com/' data = requests.get(url).text s = etree.HTML(data) links = s.xpath('/html/body/div[1]/div[5]/div[1]/div/div[2]/div/div/ul/li/a/@href')
2、下载页面:利用URL找寻到页面后,将页面下载下来,python可以用requests组件来执行这个动作
url = 'http://news.sohu.com/' data = requests.get(url).text
3、提取有用数据:由于网页前端含有大量的HTML标注代码,并且还包含了大量我们不需要的东西,像是我要获取房屋的均价,我只需要房屋的价钱跟面积就可以了,剩下的那些介绍我都不需要,这就需要利用一些组件来提取数据了,python里比较常见的是beautifulsoup跟lxml,下面是利用lxml来解析HTML再提取文章的标题 (需要先找到标题的XPATH)
s = etree.HTML(data) titles = s.xpath('/html/body/div[1]/div[5]/div[1]/div/div[2]/div/div/ul/li/a/text()')
4、储存数据:将数据提取出来当然是要找地方储存,我是储存在txt档里,当然也可以用其他格式储存,下面是将搜狐的URL用for循环跑了一遍,并将新闻的内容提取出来储存在txt里面以供使用
for link in links: content = requests.get(link).text s = etree.HTML(content) words = s.xpath('//*[@id="mp-editor"]/p/text()') print(words) f = open('news2.txt','a') for word in words: f = open('news2.txt','a') f.write(word) f.write("\n") f.write("---------------------------------------") f.close()
以下为抓取到的新闻标题与内容,只截取了部分,可以看到已经是纯文字了,而且是我们要的新闻内容

由于搜狐也是有前端反爬虫的保护,所以一开始在抓取内容的时候容易漏抓部分的内容,但多观察几篇的代码就可以找出它变化的规律,将所有的规律写入就可以提高抓取的完整度。

转载于:https://www.cnblogs.com/yenpaul/p/9968015.html