.Net сделан раньше с некоторыми автоматизированными роботами, слушать Даниилу сказать, используя питон рептилия легче писать, не в силах контролировать себя, что нашли время, чтобы попробовать один, используя Python обходы Baidu Street View изображение.
Эти два дня, Ухань, канцлер Германии Ангела Меркель приветствует великого человека, и кисть Ухань реки Янцзы мост в Ухань реки Янцзы мост сегодня, к примеру, с помощью образа улицы Python ползет позицию.

анализ улица Baidu URL
Http на основе захвата пакетов инструмент, вы можете легко добраться до данных запроса HTTP при просмотре улиц Baidu. Как показано ниже, то есть положение точки изображения ломтиком Янцзы мост Улица:

URL запроса, соответствующий срез:
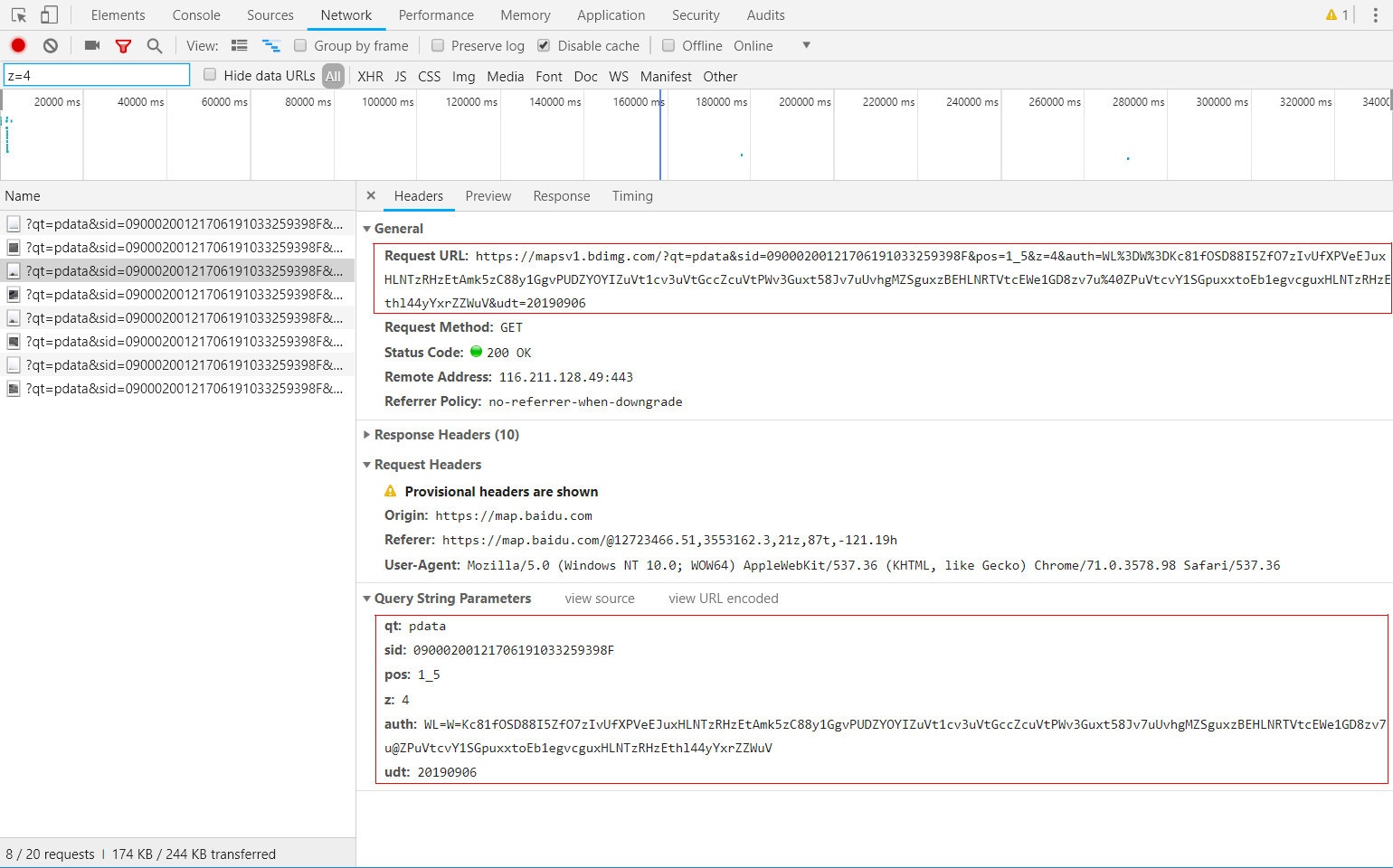
Подробный анализ запроса URL, и после испытаний моделирования можно суммировать следующим образом предварительные выводы
Несколько ключевых параметры, необходимые для ломтиков запроса изображений были:
① с.и.д.: от имени конкретного бита уличных аттракционов;
② поз: представительные координаты ломтиков на срезе ФПГ полного панорамного изображения;
③ г: Street представитель изображения уровня среза.
Просмотр улицы одного изображения для получения позиции среза может несколько уровней, на разных уровнях, различное количество срезов; ломтики, используя координату номера строки и номер столбца следует отличать.
Baidu ясно больше, чем правило среза Streetscape изображений, вы можете использовать код, чтобы открыть линию и.
Исходный код Python
Требования: захватить одноразовую 10 последовательных секций информации на всех уровнях полно достопримечательностей.
Источник следующим образом:
import urllib2
import threading
from optparse import OptionParser
# from bs4 import BeautifulSoup
import sys
import re
import urlparse
import Queue
import hashlib
import os
def download(url, path, name):
conn = urllib2.urlopen(url)
if not os.path.exists(path):
os.makedirs(path)
f = open(path + name, 'wb')
f.write(conn.read())
f.close()
fp = open("E:\\Workspaces\\Python\\panolist.txt", "r")
for line in fp.readlines():
line = (lambda x: x[1:-2])(line)
# url = line
for zoom in range(1, 6):
row_max = 0
col_max = 0
row_max = pow(2, zoom - 2) if zoom > 1 else 1
col_max = pow(2, zoom - 1)
for row in range(row_max):
for col in range(col_max):
z = str(zoom)
y = str(row)
x = str(col)
print(y + "_" + x)
url = line + "&pos=" + y + "_" + x + "&z=" + z
path = "E:\\Workspaces\\Python\\pano\\" + url.split('&')[1].split('=')[1] + "\\" + z + "\\"
name = y + "_" + x + ".jpg"
print url
print name
download(url, path, name)
fp.close()
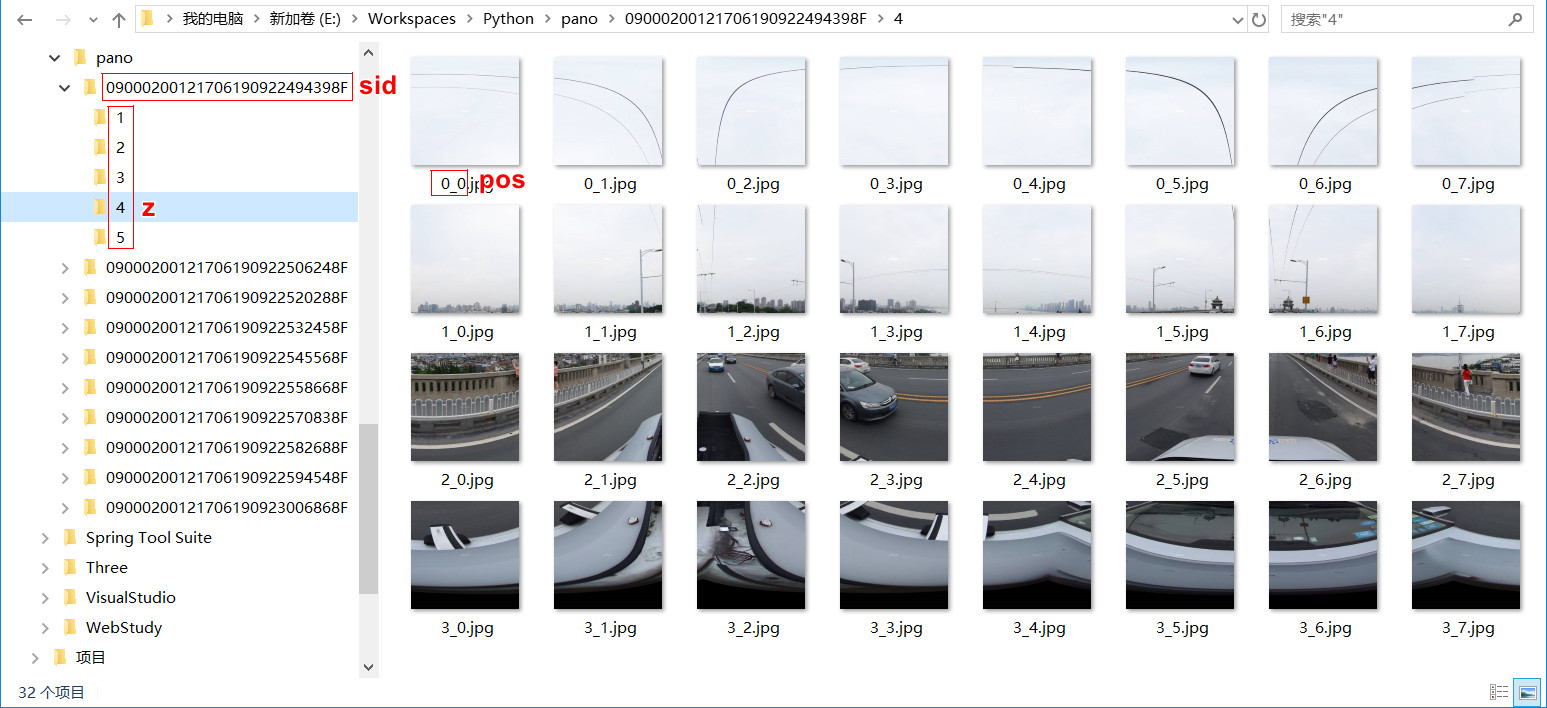
抓取结果如下,按上述分析的规则进行本地化存储,可以看到各级别下,所有的切片拼接起来,刚好是一张完整的全景图。
小结
① Python这门语言真的是蛮便捷,安装和配置都十分方便,也有很多IDE都支持,我初次使用,遇上问题就随手查Python语言手册,基本上半天完成该代码示例。
② 在爬虫程序方面,Python相关资源十分丰富,是爬虫开发的一把利器。
上述代码简要的实现了批量抓取百度街景影像切片数据,大量使用的话,建议继续处理一下,加上模拟浏览器访问的处理,否则很容易被服务方直接侦测到来自网络爬虫的资源请求,而导致封堵。
附 python爬虫入门(一)urllib和urllib2 https://www.cnblogs.com/derek1184405959/p/8448875.html