ссылка: https: //www.zhihu.com/question/352256403/answer/878523206
Источник: знаю почти
защищены автором. Коммерческая перепечатка пожалуйста , свяжитесь с автором авторизована, некоммерческая перепечаткой пожалуйста , укажи источник.
Основное название, поздравление, вы думаете, глубоко ряд важных вопросов, как с открытым исходным кодом для энтузиастов техник + промежуточный слой данных, попробуйте ответить на несколько вопросов о теме Господа:
- Когда мне нужно промежуточное программное обеспечение данных, промежуточное программное обеспечение может сделать
- Принцип промежуточных данных, которые промежуточный слой данные с открытым исходным кодом
- Почему внутренний с открытым исходным кодом, и в основном перестал обновлять
- Какие данные рекомендуется использовать промежуточное программное обеспечение, каковы преимущества
Во-первых, когда вам нужно промежуточное программное обеспечение данных, промежуточное программное обеспечение может сделать
Как название говорит Господь, как развитие бизнеса, таблица базы данных MySQL, Oracle растет, через год или два, 2 миллиона или даже миллиарды записей таблицы будет появляться (как правило, считается простым таблица более сложная, когда MySQL миллионы десятки миллионов раз, Oracle десятки миллионов раз, будет сложный запросом или эксплутационное изменения проблемой), на этот раз может привести к сложным запросам медленно, медленно вставлять и изменять данные , DDL исполнение слишком медленно приводит к изменяющие тип столбца таблицы не могут быть изменены или добавлены в индекс или добавить поля, и так далее. Как это сделать? На этот раз мы сделали несколько подходов:
- Таблица истории: Раскол история времени таблица из, уменьшить объем данных, ранее более распространенный, по сути, представляет собой особый вид расщепленных уровней, бизнес-навязчивый
- Вертикальное разделение: колонны, разделяется на широкие столбцы таблицы несколько сот множество столбцов (то есть меньшее количество данных на запись) таблицы, не уменьшая количество записей, но уменьшить количество данных всей таблицы и индекс размера
- Разделение уровней: по одному или некоторые из хеш-значений столбцов, чтобы равномерно разделить библиотеку данных или множество той же таблицы, таким образом, непосредственно уменьшить объем данных в одной базе данных одной таблицы, такие, как раскол 1024 делится на подтаблицы, это может уменьшить количество данных в одной таблице на три порядка, оригинальный один сто миллионов таблицу, теперь 100000 одиночных данных таблицы, делать сложные операции на одной таблице может быть очень быстро вверх. Недостаток заключается в том, что первоначально нужно только работать таблицу, вы должны знать, чтобы работать в этой таблице в настоящее время до операции, такие как таблицы пользователя, таблица делится на UID: Оригинальный SQL1: * Выберите из пользователей, где UID = 1025, а теперь должны знать идентификатор пользователя 1025, то знайте, 1025% 1024 == 1, SQL становится SQL2: выберите * от users_0001 где UID = 1025, также смотрит на инвазивного типа бизнеса. Как бизнес может стать прозрачным, что требует промежуточного ПО, чтобы помочь нам положить SQL1 автоматически становится SQL2, что делает наши точки, независимо от библиотеки, независимо от таблицы деления, разделите количество коды похожи, не слишком много модификации ,
- Раздельное чтения и записи: например, как в MySQL TPS / КПТ уже высоки, и тысячи тысяч, и сделал 3 раза по сравнению с основным, мы надеемся, что эти четыре примера можно разделить часть давления, особенно при чтении и записи меньше в случае, если чтение каждого давления одинаково, вы можете уменьшить давление главной библиотеки читать, писать и внимание, чтобы получить основную библиотеку. На этот раз также требует запроса данных для промежуточного программного обеспечения маршрутизируется другой библиотека.
Если наше дело к необходимости снижения давления в одной базе данных одной таблице, или отдельным читать и писать, но не большой R & команду D, собственный этот кусок накопления технологии не достаточно, чтобы развивать свой собственный код, чтобы получить некоторую промежуточную задачу слоя, в качестве основной задачи Мол, мы должны рассмотреть вопрос о введении в данном промежуточном программном обеспечении. Почему отечественный большое поле данных промежуточного ПО с открытым исходным кодом, количество данных не достаточно небольшие компании, или технология не достаточно, не нужно разрабатывать свои собственные промежуточное программное обеспечение, количество позже, если вы используете простую сцену, использование технологии с открытым исходным кодом является наиболее экономичным решением. Крупные компании имеют возможность получить промежуточное программное обеспечение данных, теперь мы знаем, что это является частью открытого источника наизнанку, особенно в последние годы, так же, как есть первичный ответ сказать, как мы занимаемся в распределенной базе данных, распределенных максимальная емкость базы данных намного больше, чем традиционные реляционные базы данных MySQL / Oracle, следует рассматривать как часть функции промежуточного лечения в базу данных, и эти компании менее озабочены эти проблемы. С другой стороны, некоторые данные промежуточного слоя, в облачной системе, становятся частью РДС внутри закрытого источника.
Во-вторых, реализация принципа промежуточного данных, какие данные промежуточного слоя с открытым исходным кодом
Проще говоря, есть два принципа:
- Режимы клиента JDBC: как банка пакет библиотеки промежуточного слоя или тому подобное, например, схематическая фигура, только прямые ссылки в проекте, суб-библиотеке суб-таблицы настроены правила, с промежуточным слоем из источника данных, упаковка JDBC, то есть, каждый раз, время вызова, JDBC классы обертки автоматически заменяются в хорошем SQL, а затем вызвать фактический JDBC и SQL, чтобы завершить операцию. Однако, так как одной библиотеке и требует прямого стола оператора, так что будут какие-то ограничения для SQL, должны принести определенные суб-библиотека условий суб-таблицы, полимеризация не может быть слишком сложной операции.
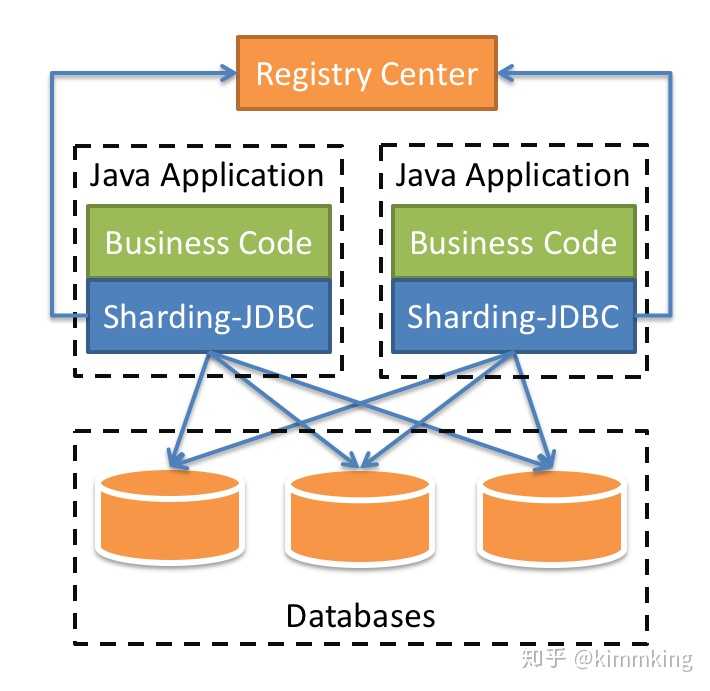
- Режим Proxy Proxy:
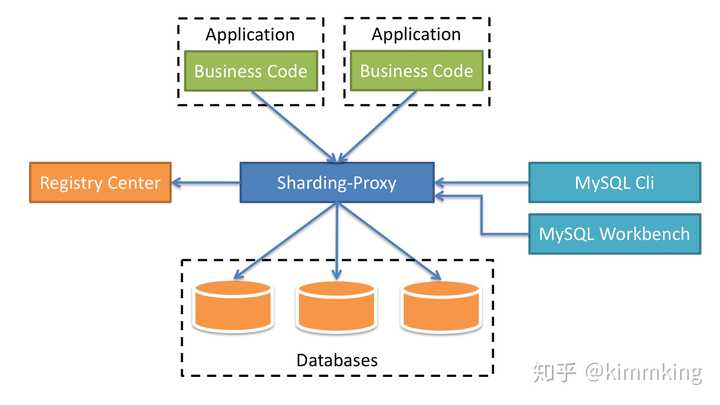
В начале основной с открытым исходным кодом промежуточного на следующем рисунке:
Цитируется по: HTTPS: // blog.csdn.net/w89282419 6 / Статья Эта статья / Детали / 82660415
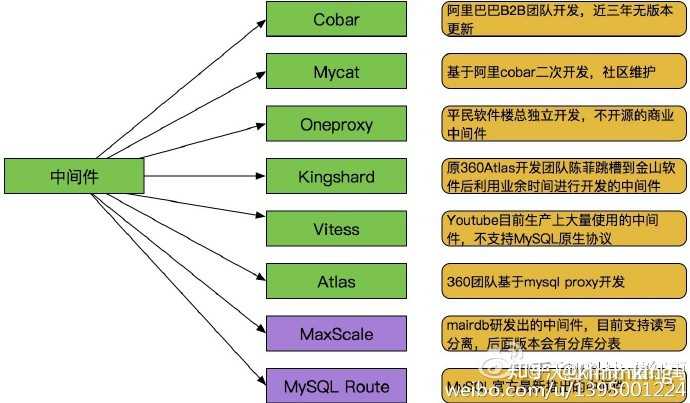
- Cobar: Alibaba B2B разработки реляционных распределенных систем управления почти 3000 экземпляров MySQL. Али выдержала испытание, причины отменялись из авторов кобара не были сохранены, и Али также разработала tddl альтернативной Cobar.
- MyCAT:社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,目前已经有一些公司在使用MyCAT。总体来说支持度比 较高,也会一直维护下去,
- OneProxy:数据库界大牛,前支付宝数据库团队领导楼总开发,基于mysql官方 的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件, 楼总舍去了一些功能点,专注在性能和稳定性上。有朋友测试过说在 高并发下很稳定。
- Vitess:这个中间件是Youtube生产在使用的,但是架构很复杂。 与以往中间件不同,使用Vitess应用改动比较大要 使用他提供语言的API接口,我们可以借鉴他其中的一些设计思想。
- Kingshard:Kingshard是前360Atlas中间件开发团队的陈菲利用业务时间 用go语言开发的,目前参与开发的人员有3个左右, 目前来看还不是成熟可以使用的产品,需要在不断完善。
- Atlas:360团队基于mysql proxy 把lua用C改写。原有版本是支持分表, 目前已经放出了分库分表版本。在网上看到一些朋友经常说在高并 发下会经常挂掉,如果大家要使用需要提前做好测试。
- MaxScale与MySQL Route:这两个中间件都算是官方的吧,MaxScale是mariadb (MySQL原作者维护的一个版本)研发的,目前版本不支持分库分表。MySQL Route是现在MySQL 官方Oracle公司发布出来的一个中间件。
- ShardingSphere,后起之秀,源于当当网架构部的ShardingJDBC框架。
上面都是提到了分布分表和读写分离的中间件,其实还有一些专注于分布式事务的、数据复制传输的等等,比如fescar,canal、outter等等。
其实淘宝早期开源了TDDL,淘宝分布式数据中间层,但是只开源了客户端jdbc模式,没有开源proxy代理模式。
三、为什么都是国内开源的,并且大都停止了更新
国内的开源,部分是大公司主导的技术影响力输出,部分是个人的兴趣之作贡献给社区,总而言之是没有直接的显著回报的。也就是说,这一块一直没有一个稳定可行的商业模式来支持,所以一直以来,大公司实际上也看不上,因为赚不了钱,而没有回报的事情就无法长久,所以自然就停止了更新。对于个别有云服务的公司,这一块技术发展好了,其实可以并到云里提供数据服务,或者进一步的发展成为分布式数据库,这样可以变现了,那就闭源,所以,现在活跃的开源数据中间件,已经不多了,下面就推荐一个活跃的项目。
四、推荐使用什么数据中间件--ShardingSphere
推荐使用近期加入Apache基金会的第一款数据中间件,也是国人开发的,ShardingSphere项目。可以直接在这个项目的github commits记录看到,非常活跃,每天都有提交记录,issue也一直在持续维护。为什么还活得这么好呢?因为有张亮团队的专职在开发、维护和推广。
详细文档和代码参见:
ShardingSphereshardingsphere.apache.org apache/incubator-shardingspheregithub.com
apache/incubator-shardingspheregithub.com
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
稍后我推荐ShardingSphere项目的两个主要PMC,@张亮 和 @曹昊,来关注一下这个问题。