Установка модуля
Windows
Установка SCRAPY нужно устанавливать в зависимости от окружающей среды, скрученной, скрученными и нужно установить C ++ зависеть от окружения
Когда пункт установить Scrapy если скрученной ошибку
Витая в https://www.lfd.uci.edu/~gohlke/pythonlibs/ скачать соответствующую версию (версии cp36 имени python3.6 файл)

Затем введите CMD в директорию, где установить выполнение Twisted Twisted пип плюс имя файла
Последнее исполнение пункта установить Scrapy
Рекомендации по установке Ubuntu
Не следует использовать программный пакет питона-scrapyUbuntu при условии, что они, как правило, слишком стары и медленная скорость, не может догнать последнюю Scrapy
Для Ubuntu (или на основе Ubuntu) Scrapy, установленных в системе, вам необходимо установить эти зависимости
Sudo APT-получить установку питона-DEV питон-пип libxml2-DEV libxslt1-DEV zlib1g-DEV libffi-DEV libssl-DEV
Если вы хотите установить Scrapy на Python3, вы также должны заголовки развития Python3
Sudo APT-получить установку python3-DEV
В virtualenv, вы можете использовать пункт установить Scrapy: пип установить Scrapy
Простой в использовании
Новый проект
SCRAPY startproject project_name
Написать рептилии
Первый способ: создать единый файл
Создайте класс, который должен наследовать класс scrapy.Spider, необходимо определить три свойства
Имя: паук должен быть уникальным и
start_urls: первоначальный список URL
синтаксический анализ (сам, ответ) Метод: URL вызываются после каждого завершения первоначального
Синтаксический анализ функции для выполнения двух функций
1, разобрать ответ, и вернуть пакет на объект элемента объекта
2, необходимо извлечь новый URL-адрес загрузки, создайте новый запрос и возвращает его
Выполнение одного командного файла SCRAPY runspider demo.py
Второй подход: Создать команду
SCRAPY genspider рептилии доменное имя
Запуск рептилии
Список SCRAPY для просмотра файлов, которые могут быть запущены рептилии
SCRAPY имя ползать рептилии (значение имени атрибута)
Отслеживание ссылок
Создайте переменный класс PAGE_NUM ползет для хранения номера текущей страницы, информации, извлекаемая синтаксический анализ функции, а затем добавляет 1 к переменной page__num от объекта через гусеничный, следующую конфигурацию URL, а затем создает и возвращает объект scrapy.Request
Если ответ меньше, чем извлекать информацию, мы должны судить последнюю страницу, конец функции синтаксического анализа непосредственно вернуться
Defined трубопровод пункт
синтаксический анализ функции после разбора информации нам нужно, эта информация может быть упакована в словаре объект или объект scray.Item, а затем вернуться
Этот объект будет передан в трубопровод элемента, который выполняет несколько компонентов путем последовательной ее обработки. Каждый элемент воздуховод в сборе представляет собой простой способ для достижения класса Python
Они получают и принять меры по пункту, и определить, является ли элемент должен продолжать через трубопровод отбрасывается и не обрабатываются или
Типичное использование элемента трубы:
Очистка HTML данных
Убедитесь в том, что данные были удалены (проверить, содержат ли элементы определенных полей)
Проверьте наличие дубликатов (и удалять их)
Товар был искателем сохранение данных
Написать Pipeline
# Выполнить Защиту open_ паук (самость, паук) в начале рептилий
# Reptile закрыт при выполнении Защиты close_ паука (я, паук)
# Из перевода элемента из процесса и возврат обработанного элемента четкости process_ элемента (сам, пункт, паук)
Для активации этого компонента трубопровода, необходимо добавить его в ITEM_PIPELINES настройки, заданные в файле настроек
В этом устройстве определяет порядок, в котором они работают целые значения присвоен класс: в порядке от нижнего значения к более высокому значению
Определенный элемент
Класс товара обеспечивает Scrapy
items.py редактировать файлы в директории проекта
Мы ввели класс Item определен в гусеничном, структура данных из экземпляра с помощью его
Запуск процесса
поток данных
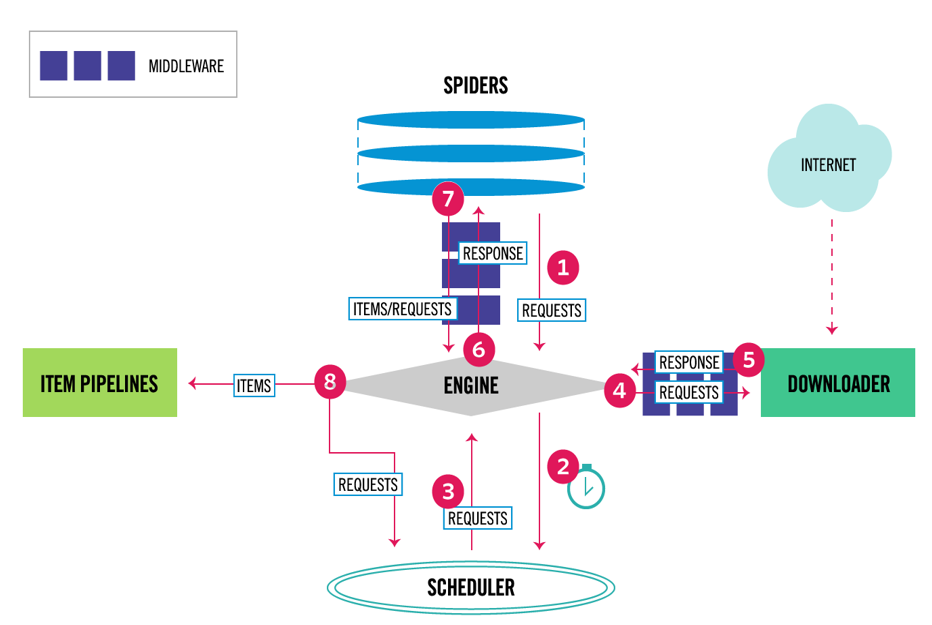
Во-первых, получить первоначальный запрос от рептилий
Модуль планирования в запрос, то запрос на следующем приобретение требует ползания
Планирования модуля запроса для возврата к двигателю требуется ползать
Двигатель посылает запрос на загрузку, на загрузку последовательности через все промежуточные
После того, как страница будет завершена, загрузка возвращает ответ, содержащий данные страницы, а затем последовательно через все загруженный промежуточный слой
Двигатель получает ответ от загрузчика, а затем отправлен в разборе рептилия, рептилия последовательно через все промежуточные
Рептилиям обрабатывать полученную ответ, а затем разбор элемент генерирует новый запрос отправляется в двигатель
Двигатель имеет хороший обработанный элемент компонент трубопровода, генерирует новый запрос в модуль планирования хорошего, и запрашивает следующий запрос
Повторы процесса до тех пор, пока есть не запрос на планировщик
пакет
Данные пауки Искатели обработки, необходимые для извлечения или другого ответа на запрос выборки
Поток данных между всеми компонентами двигателя двигатель двигателя отвечает за систему управления и запуска событий, когда происходят определенные действия
Планировщик планировщик получает запрос запроса очереди Епдиеего
загрузить двигатель отвечает за отправку запроса по запросу на скачивание
трубопроводы данных элемента труба, ответственная за паук возвращается для хранения
Промежуточное
Скачать Middleware
Загрузка промежуточный слой расположен между конкретным двигателем и крючками загрузчиком которого обработкой запроса передается от двигателя к загрузчику, а загрузка поступают в двигатель в ответ на
Используйте Downloader, чтобы сделать следующее промежуточное программное обеспечение
Перед отправкой запроса, чтобы загрузить программу для обработки запроса (т.е. перед SCRAPY посылает запрос на сайт)
Перед тем, как ответ посылают рептилий
Непосредственно послать новый запрос, вместо передачи принятого ответа на паук
Ответ не получить передается на веб-странице гусеничного
Спокойно отказаться от некоторых запросов
Рептилия Middleware
Промежуточный находятся в определенном гусеничном крючке между двигателем и гусеничным, и способны обрабатывать входящие запросов ответа и передают из пункта
Используйте следующие рептилии промежуточному
После обработки элемента или запроса обратного вызова рептилии
Обработка start_requests
Аномальные рептилии погрузо
errback, а не вызывать ответ на запрос обратного вызова на основе содержания
Событийный сеть
Витая SCRAPY написана, фреймворк Twisted Python является популярным событийным. Он использует неблокируемый (также называемый асинхронным) код параллелизм