
Аннотация: БЕРТ хороший эффект и потому , что два основных преимущества для широкого спектра, поэтому важным этапом в области НЛП. Реальный проект в основном используется для выполнения задач классификации БЕРТА текста, на самом деле, играть текстовую метку. Поскольку оригинальный экологический БЕРТ перед тренировкой модель легко несколько сотен или даже на размер гигабитной скорости поезда модели очень медленно, для BERT модельного ряда очень недружелюбно. Benpian исследования в настоящее время больше огня BERT последние производные продукты АЛЬБЕРТ БЕРТ осуществляется онлайн сервис. методы снижения параметров ALBERT для уменьшения потребления памяти и , таким образом , в конечном счете , повысить скорость BERT обучения, и являются одними из лучших в основных тестах, можно охарактеризовать как быстро бегать, но и хорошо работать. Надежда будет представлять интерес требовать BERT линии немного меньше партнеров помощи.
Каталог
01 Обоснование проекта
02 от BERT Альберту
03 миль Шаг Один: Xianpao модель через
более чем 04 практики классификации задач
сводном
фона 01 Проект
оригинальной экологической BERT модели предварительного обучения легко несколько сотен или даже на размер гигабитной, скорость обучения самого замедлять для модельного ряда очень недружелюбно. Для достижения задачи БЕРТА модельного ряда, на самом деле, это то , как быстро хорошая модель обучения, Проект исследования в настоящее время ультра огонь BERT последних производных продуктов АЛЬБЕРТ может решить вышеуказанные проблемы.
АЛЬБЕРТ бумага: предлагаемый «Альберта Lite БЕРТ Для Само- Руководил Learningof Language Представление» , чтобы прибыть. Увеличение размера модели предварительного обучения в нормальных условиях может улучшить модель производительности в последующих задач, но из - за «/ память ограничений GPU TPU, длительное время обучения и неожиданные модели дегенератов» и другие вопросы, авторы предложили АЛЬБЕРТ модель.
Бумага Загрузка:
HTTPS: // arxiv.org/pdf/1909.1194 2.pdf
АЛЬБЕРТ популярное понимание , что меньшее количество параметров Bert облегченная модель. АЛЬБЕРТ БЕРТ является последними производными продуктами, хотя легкий, но не обесценить эффект, в основных тестах являются один из лучших.
БЕРТ от 02 до ALBERT
появляется фон 1. ALBERT
с глубины обучения взорвано области компьютерного зрения, способ повышения эффективности модели простейшего и наиболее эффективного способ увеличения глубины сети. Под фигурой , чтобы сфотографировать классификации задач, например, можно рассматривать как сеть продолжает увеличивать количество слоев, влияние модели будет большое обновление:
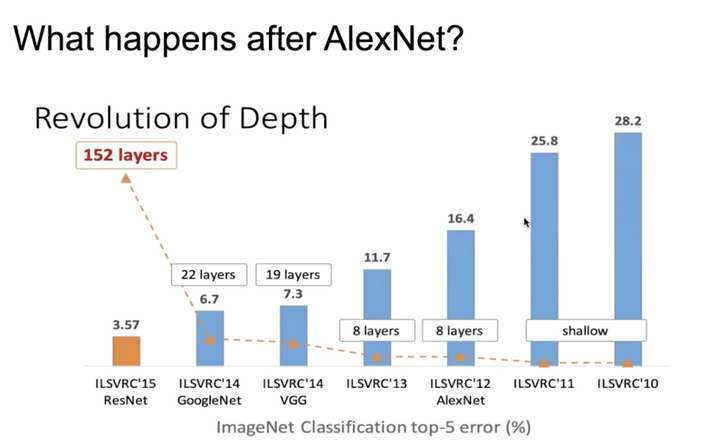 Сеть модель для усиления эффекта увеличения количества слоев на фиг.
Сеть модель для усиления эффекта увеличения количества слоев на фиг.
Же ситуация происходит на BERT, таких, как сеть становится глубже, шире эффект лифтинга модель получается:
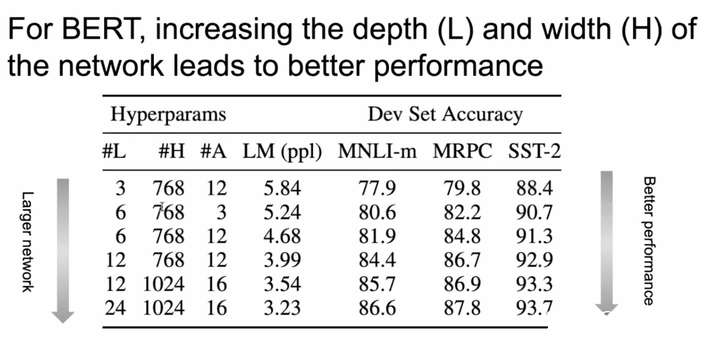 Фиг.2 БЕРТЫ модель, как сеть становится шире эффект глубины заключается в повышении
Фиг.2 БЕРТЫ модель, как сеть становится шире эффект глубины заключается в повышении
Но сеть становится глубже округлились принести существенную проблему: Параметр взрыва. Здесь количество масштабных моделей параметров BERT выглядят различные параметры изменения «жир» дорога:
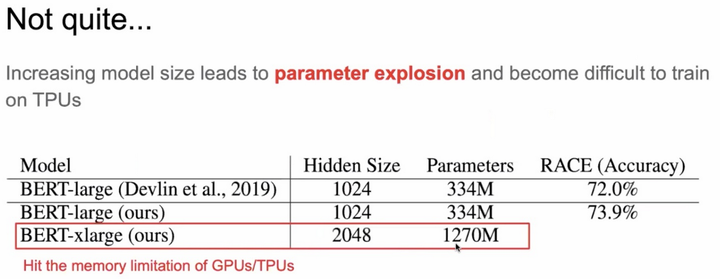 Рисунок 3 Параметры BERT взрыв
Рисунок 3 Параметры BERT взрыв
Как это сделать, так БЕРТ не так «жир», но эффект все равно хорошо научные исследования фокус в том , как один из Берт линии приоритетов. Также АЛЬБЕРТ делать.
2. БЕРТ «жир» Где
хотите BERT тоньше, прежде всего знать «мясо» длинный где. БЕРТ с использованием трансформатора в качестве признака экстрактор, который является источником параметров BERT. Перед рекламной индустрии в той интересной серии 4: Комментарии от поддержки роли в C-разрядный полусыром Transformer очень глубокий анализ трансформатора, малые партнеры , которые заинтересованы может оглянуться назад.
Трансформатор основного источник блоков параметров: первый модуль , блок отображения маркеров вложения параметра составляет более 20%, второй блок внимания к слою с обратной связью и передним слоем, в FFN, параметр составляет более 80%.
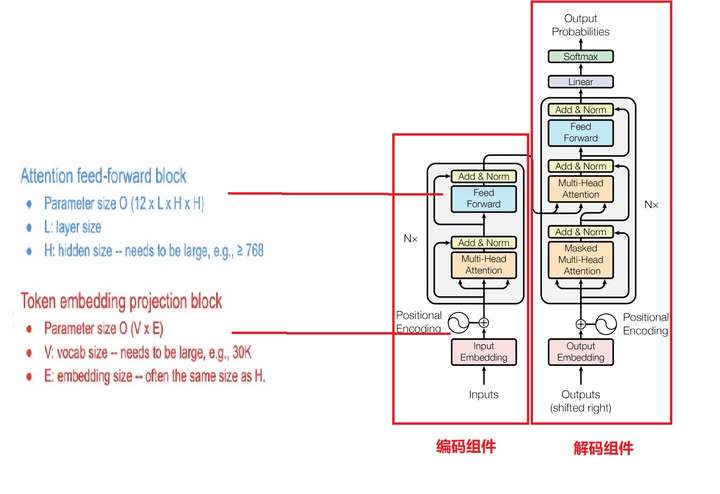 Схема конфигурации фиг. 4 параметров трансформатора источника и BERT
Схема конфигурации фиг. 4 параметров трансформатора источника и BERT
3. ALBERT оптимизации стратегии
Стратегия Во- первых, вложение параметров факторизационные (факторизованных вложение параметризация)
БЕРТ отображается один горячий вектор к высокой размерности пространства словами, параметр представляет собой количество O (VXH), ALBERT факторизационной используется первый вариант один горячий вектор слово отображается в низком пространстве (размер E), а затем отображается обратно к высокому-мерном пространстве (размер Н), так что параметры , используемые только O (VXE + EXH), если Е << когда количество параметров Н будет уменьшено много. Вот несколько уменьшить параметра BERT маркер вложения первую часть сказанного, это в некоторой степени.
Причины могут быть уменьшены на величину факторинга параметры являются контекстно - независимый маркер вложение преобразуется в плотную один горячий вектор вектором. FFN и вторая часть внимания в качестве скрытого слоя является контекстно-зависимым, содержит больше информации. Таким образом, делая менее чем Н Е посредстве одного докрасна вектора слова , чтобы пройти через матрицу вложения низкоразмерной, затем отображается обратно в высокой размерности матрицы вложения это возможно. Красный прямоугольник показывает разложение частей:
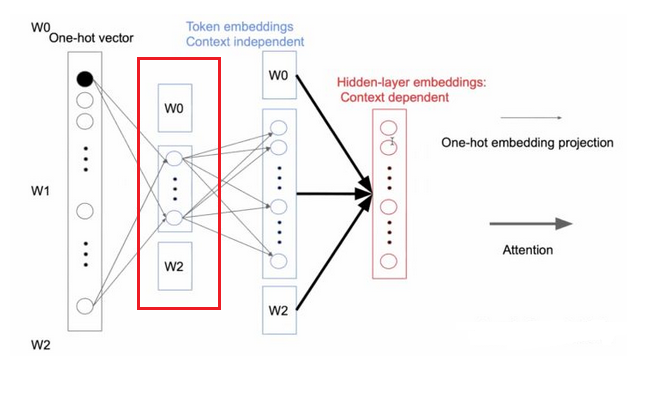 Фиг.5 факторизационные параметры, чтобы уменьшить количество
Фиг.5 факторизационные параметры, чтобы уменьшить количество
Просмотр маркеров вложения факторизационной эффект: общий уменьшенное 17% от параметров модели, а только эффект уменьшения модели менее чем на 1%.
 Фиг.6 факторизационные параметры, чтобы уменьшить эффект от суммы
Фиг.6 факторизационные параметры, чтобы уменьшить эффект от суммы
Параметры (совместное использование параметров кросс-слой) между двумя стратегиями, общие слои
слоями трансформаторные параметрического анализа показали сходные визуальные параметры каждого слоя, больше внимания выделяется в [ЦБС] на маркер и по диагонали , так что вы можете использовать кросс-слойной схему разделения параметров.
Вообще говоря, параметр кросс-слой , соответствующий общей структуру кодера Transformer есть два варианта: один общий модуль параметров внимания, а другие параметры сетевого уровня FFN упреждение нейронные совместно. Конкретные результаты , как показано ниже:
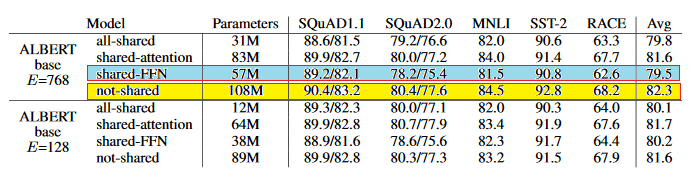 7, используя общие параметры на модели параметра и эффект количество
7, используя общие параметры на модели параметра и эффект количество
Когда маломерная пространство отображается на Е = 768, и сравнение не разделяют параметры общие параметры FFN слой можно увидеть, параметр уменьшается почти на 50%, что является в основном за счет эффекта модели приводит к снижению. Общие параметры внимания слоя меньше влияния на результатах модели.
Стратегия Три, строить самообучение задача - предсказание связного предложения
(Next Приговор Prediction) миссия через трансформацию NSP, предварительно тренировочную миссию по улучшению расширенного непрерывного обучения предложения.
Рекламная индустрия в этих интересных сериях 3: НЛП звезда BERT ключ объяснил модель BERT, которая относится к Bert выдающихся достижений в последние года поля NLP мастера самой инновации в основном модель случайной экранированного языка Маска LM и следующее предложение предсказать предсказания следующего предложения. Заинтересованные партнеры могут вернуться на следующий немного лучше смотреть.
Сама NSP задача является бинарной задачей классификации, цель состоит в том, чтобы предсказать два предложения , являются ли последовательными заявлениями. NSP фактически содержит две подзадачи, которые являются предметом прогнозирования и прогнозирования непротиворечивость отношений. NSP задача выбора один и тот же документ в двух последовательных предложениях в качестве положительного образца, выбрать другое предложение в качестве документа отрицательных образцов. Поскольку из различных документов, разница может быть очень большой. Для того , чтобы повысить способность модели предсказывать непрерывное предложение, АЛЬБЕРТ предложил новый SOP задачи (SenteceOrder Prediction), положительный режим выборки приобретения и ту же NSP, заявление будет порядком отрицательных образцов положительные проб обратных.
СОП и показывает эффект NSP , как показано ниже:
 Фиг.8 СОП и показать эффект NSP
Фиг.8 СОП и показать эффект NSP
Как видно из рисунка задача не может быть предсказана типа ПНБ SOP задачи, можно предсказать задачу СОП NSP. В целом модель также превосходит эффект задачи СОП задача NSP.
Стратегия 4, чтобы удалить Dropout
Dropout главным образом для предотвращения чрезмерного облегать, но фактическая MLM вообще не легко по-фитинга. Выпадение также могут быть удалены с тем, чтобы эффективно увеличить меньше промежуточную переменную во время тренировки использования модели памяти.
 На фигуре 9 отсева эффекты Эффект
На фигуре 9 отсева эффекты Эффект
Другие стратегии: ширина и глубина воздействия на сетевой модели эффект
1. глубины сети будет глубже , тем лучше
контрастность АЛЬБЕРТ можно найти на различных глубинах , в сущности: С углублением слоев, моделировать влияние различных задач NLP есть определенное обновление. Но эта ситуация не является абсолютной, но уменьшит эффект некоторых задач.
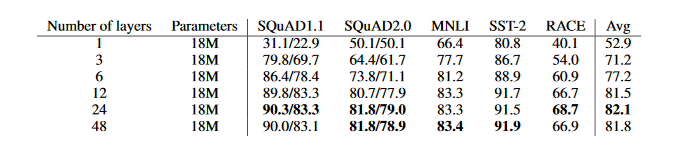 Влияние глубины сети 10 по фиг.
Влияние глубины сети 10 по фиг.
2. если ширина широкой сети лучше
глубины модели контраста , где влияние различных сетей ширины АЛЬБЕРТ-больших моделей можно найти 3: Эффект подобной ширины и глубины модели, с увеличением ширины сетевой модели является то , что влияние различных задач НЛП есть определенные обновления. Некоторые задачи будут эффектом присутствия упадка.
 Влияние сети 11 ширины фиг
Влияние сети 11 ширины фиг
В целом, суть заключается в использовании параметров технологии сокращения Альберта, чтобы уменьшить потребление памяти и, таким образом, в конечном счете, повысить скорость BERT подготовки, главным образом, чтобы оптимизировать следующие аспекты:
- По факторингу и параметра обмена между слоями, чтобы уменьшить число параметров модели для улучшения параметра эффективности;
- По СОПАМ альтернативной NSP, возможность повышения преемственности обучения предложения, чтобы повысить способность самостоятельно поднадзорное обучение задач;
- Можно сэкономить много за счет устранения отсев временных переменных, модель эффективно повысить эффективность использования памяти процесса обучения, повышения эффективности модели, уменьшив размер обучающих данных.
03 Miles Первый шаг: начать и через модель ,
так как фактический главный проект должен определить китайцев, это в основном использование АЛЬБЕРТ китайской версии ALBERT_zh, GitHub проекта Адрес: HTTPS: // github.com/brightmart/a lbert_zh .
Я помню , не видел картину очень интересно, может быть описание хорошо мои чувств в данный момент:
 12 по фиг. Шаг Модель Xianpao
12 по фиг. Шаг Модель Xianpao
Для меня это своего рода «изма - х», тогда регресса модели первого шага всегда начало и через него, как и для оптимизации отложила. Она проходит через не только улучшить уверенность в себе, самый практический эффект в том , что мы можем быстро реализовать проект по линии. Потому что мне нужно завершить Задачу текста классификации, так что по вышеуказанному адресу для загрузки GitHub проекта, на кластерном прыжок к следующему albert_zh каталогу, выполните команду ш run_classifier_lcqmc.sh может быть запущенно. Поскольку проект не является классификационным предложением задачи, только отношений подобной задача приговора суда, поэтому начало и через эту задачу, то последние в соответствии с кодом задачи для изменения на линии.
run_classifier_lcqmc.sh сценарий обычно делится на два блока, первая часть представляет собой модель работает подготовительную работу, второй блок является модель работает. Ниже приводится модель, которая включает в себя сбор данных, модель предварительно подготовленные параметры модели , связанные с оборудованием и тому подобное.
 13 Модель работает под управлением Подготовка
13 Модель работает под управлением Подготовка
Второй блок отвечает за запуск модели, в основном питон команды для запуска программы и связанные с ним параметры, необходимые для настройки.
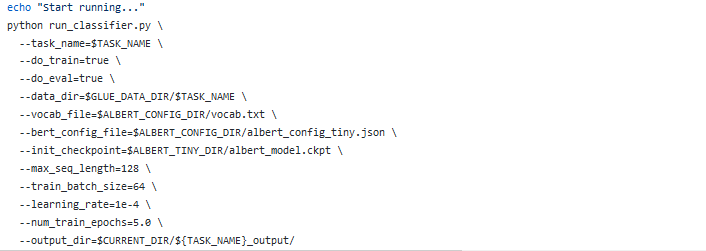 14 диаграмма модели
14 диаграмма модели
Под образом, акцент здесь сказал задаче приговаривают отношения судьи , как запустить успешный ALBERT_zh сам обеспечивает. Это демо является реальным и нашим китайским проектом этой классификации задачи очень схожие задачи, вот через трансформацию этого сценария и выполнение кода , чтобы завершить наш фактический проект текста классификации.
Более 04 практика классификации задач
проектов реконструкции GitHub по следующему адресу: HTTPS: // github.com/wilsonlsm006 / albert_zh .
Оригинальный проект вилки вниз, и здесь я добавил два файла run_classifier_multiclass.sh и run_classifier_multiclass.py. Это сценарий , задачи и код для выполнения текстовой классификации. В самом деле, принцип трансформации является относительно простым, есть примерно на следующем.
Формат данных для определения задачи приговаривают отношения проекта был первоначально предусматривались: идентификатор, text_a, text_b, этикетки , задача состоит в том, чтобы определить , на самом деле эти два слова в конце концов , нет никакой связи. Положительные образцы, например, следующий:
TEXT_A: Джеки одобрение легендарного ножа , что весела?
text_b: Джеки были другие легенды также говорят это?
метка: 1
отрицательный образец может быть таким:
TEXT_A: Jackie одобрение легендарного ножа , что весело?
text_b: Чэнду, который видит , самое забавное?
метка: 0
В силу сказанного выше двух примеров положительных и отрицательных образцов , мы должны понять , что отношения между задачей приговора суда, по сути, имеют контролируемую изучение задач классификации. В основном мы делаем фактический проект текста классификации Берта, выявляя слово принадлежит к какому тег , соответствующим указанным выше задач является на самом деле только text_a, этикеткой. Так же типа задачи, фокус политики , чтобы изменить код , чтобы там text_b отдела анализа кода. Конкретные сценарии и модификация кода есть над двумя документами, есть маленькие партнеры необходимость и изыскивает. Следует отметить , что исходный файл данных TSV формат, вот мой формат CSV, ввод данных немного отличается от других моделей не шелохнулся.
Резюме
фактических потребности проекта линии BERT нужно сделать быстрее и лучше модель обучения, поэтому на основе исследований с использованием текущей BERT последних производных продуктов АЛЬБЕРТ. АЛЬБЕРТ через факторинг и долю параметры между слоями , чтобы уменьшить число параметров модели для повышения эффективности параметров; замена СОП на NOP, способность улучшить непрерывность обучения предложения , чтобы повысить способность самостоятельно контролируемого задач обучения; может сэкономить много пути устранения отсева временных переменным, модель эффективно повысить эффективность использования памяти процесса обучения, повышение эффективности модели, уменьшив размер обучающих данных. Последнее предложение в проекте , чтобы определить взаимосвязь между задачей преобразованной в тексте классификационной задачу наших реальных проектов для реальных потребностей бизнеса. Можно сказать , чтобы иметь теорию, помогают маленькие партнеры понимают , почему АЛЬБЕРТ обучения быстрее, результаты были хорошими. Есть также практично, если вам нужно сделать , чтобы использовать АЛЬБЕРТ текст классификации задачи непосредственно с преобразованием моих хороших сценариев и кода и работает на линии.
Статьи как этот тип маленьких партнеров может сосредоточиться на своем микро-номер канала общественности: данные по приемистости. Любые сухой я сначала буду выпущен в общедоступном номере микро-канал, также известный почти в синхронизации, заголовках, Джейн книгах, CSDN платформах. Маленькие партнеры также приветствуют больше обменов. Если у вас есть вопросы, я всегда могу Q микро письмо общественности в ряде Казахстана.
