一开始用插件得到代码(参考之前写的katalon recorder插件),然后登录豆瓣,发现死都得不到username框。
后面得知它是用了iframe标签,而selenium是得不到的。必须要切换才行
直接参考两处:
selenium登录豆瓣:https://blog.csdn.net/qq_43391383/article/details/86770046
selenium遇上iframe:https://zhuanlan.zhihu.com/p/31147045


以下是我的代码:
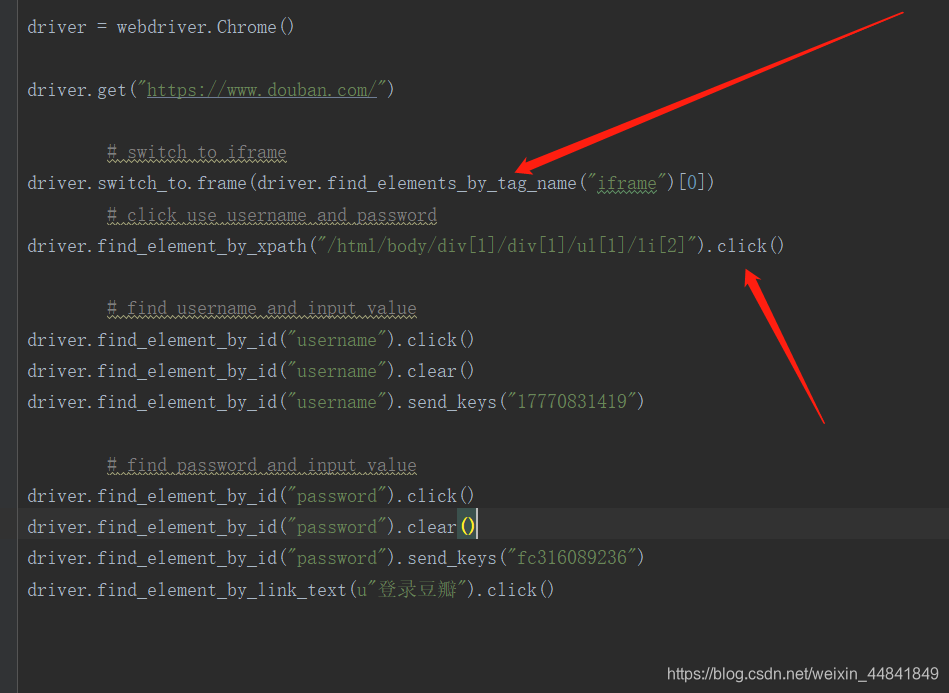
from selenium import webdriver
# Navigate to url
driver = webdriver.Chrome()
driver.get("https://www.douban.com/")
# switch to iframe
driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0])
# click use username and password
driver.find_element_by_xpath("/html/body/div[1]/div[1]/ul[1]/li[2]").click()
# find username and input value
driver.find_element_by_id("username").click()
driver.find_element_by_id("username").clear()
driver.find_element_by_id("username").send_keys("17770831419")
# find password and input value
driver.find_element_by_id("password").click()
driver.find_element_by_id("password").clear()
driver.find_element_by_id("password").send_keys("fc316089236")
driver.find_element_by_link_text(u"登录豆瓣").click()
这就完了么??并没有!
一定记住:切到iframe中之后一定要再切出来!
driver.switch_to.default_content()
要不然你的page_source不是你想得到的东西!!!!!!!!!!!!!
要用xpath得到想要的东西?
不要用这个driver.find_element_by_xpath()
试了,得不到。
用这个
from lxml.html import etree
page= etree.HTML(driver.page_source)
print(page.xpath('//div[@class="text"]/a/text()'))
用etree把这个page_source变成一个可用xpath定位的element
end
。。。。。。。。。。。。。。。。。。。。。。。。。。。。
最后
解释下我的这两处
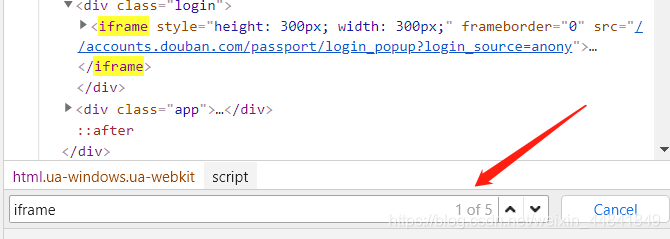
我搜索了iframe标签,发现它没有id name。于是我只能用tag,由于它是第一个
所以这里用【0】
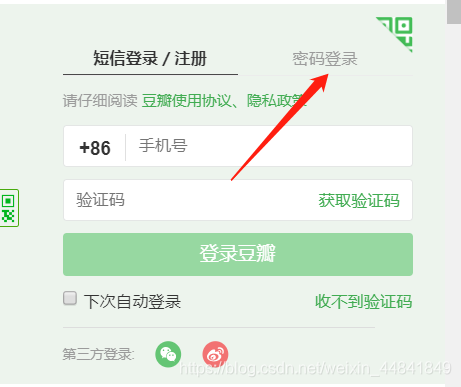
第二处是:
switch to iframe之后我还要点击:
selenium找不到元素的几种可能:
https://blog.csdn.net/zbj18314469395/article/details/83415427
