背景
Redis是使用请求/响应协议的TCP服务器,所以说通常的执行流程如下:
- 客户端发送请求,同时监听对应的socket,等待服务端响应,一般是一个阻塞的状态
- 服务端将结果发送给客户端,客户端获取到结果
整个流程如图:
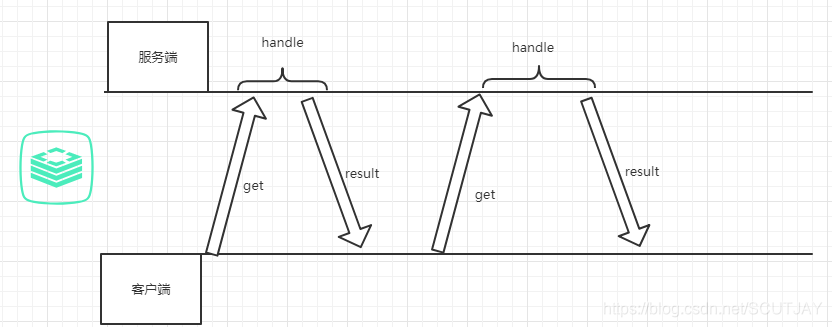
由官方提供的数据来看,Redis每秒可以进行100000+次查询,但是这只是查询的性能,在实际操作中,还需要进行TCP报文的打包和发送,假设这个过程耗时0.5秒,就算Redis查询再快,一秒内最多也就只能处理两个请求。
所以说,PipeLine是一种批量处理的机制,就是为了减少TCP连接次数,最大程度地发挥Redis的查询性能。
虽然mset,mget等也支持批量处理,但是也只有这两种,像del这样是无法批量进行的,而放在pipeline中可以实现
性能对比
/*:
* 向redis中插入10000组数据,对比使用Pipeline和不使用Pipeline的性能对比
*/
public void test(Jedis jedis)
throws InterruptedException {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
jedis.set(String.valueOf(i), String.valueOf(i));
}
long end = System.currentTimeMillis();
System.out.println("time is:" + (end - start));
Pipeline pipe = jedis.pipelined(); // 创建一个pipeline对象
long start_pipe = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
pipe.set(String.valueOf(i), String.valueOf(i));
}
pipe.sync(); // 获取所有的response,其实这一步就是批量发送
long end_pipe = System.currentTimeMillis();
System.out.println("pipe time is:" + (end_pipe - start_pipe));
}
输出:
time is:947
pipe time is:34
可以看出,差距还是很明显的
适用场景
如果系统对数据可靠性完整性要求比较高,比如说每次发送都要确保这次发送的成功,这种情况不适合用Pipeline,因为PipeLine的发送是不适合的,因为Pipeline的发送是不保证全部成功,可能有部分发送失败。
所以Pipeline更适用于那种,容忍小部分操作丢失,对实时性要求不高的场景,比如说群发信息。
注意事项
- pipeline是在内存中的,所以pipeline最好不要设置得太大。
- 因为Redis是单线程的,如果一次pipeline中的操作太多,可能会阻塞后续请求,所以要控制pipeline中处理的命令数量
- pipeline的执行不是原子操作,只是去服务端中逐条执行,如果需要保证pipeline操作的原子性,可以启动redis中的简单事务:multi,exec
