Redis Pipelining
可以实现请求/响应服务器,以便即使客户端尚未读取旧响应,它也能够处理新请求。这样就可以将多个命令发送到服务器而无需等待回复,最后只需一步即可读取回复。
这被称为流水线技术,并且是几十年来广泛使用的技术。例如,许多POP3协议实现已经支持此功能,大大加快了从服务器下载新电子邮件的过程。
Redis从很早就开始支持流水线操作,因此无论您运行什么版本,都可以使用Redis进行流水线操作
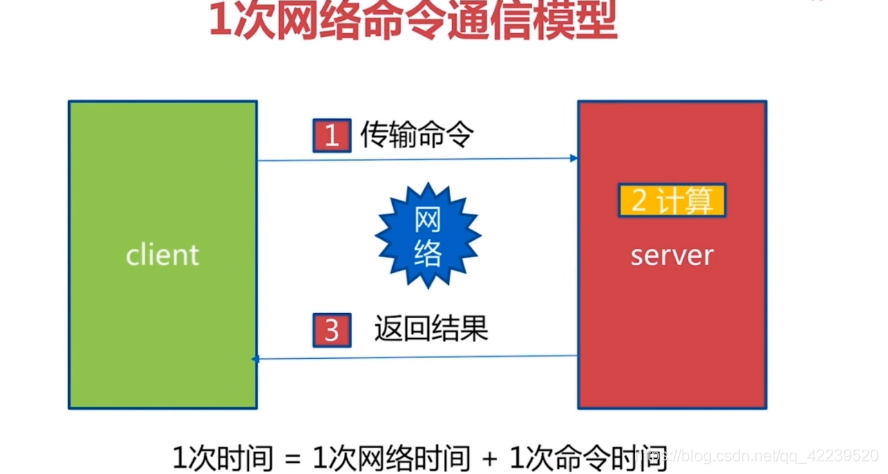
单条指令:
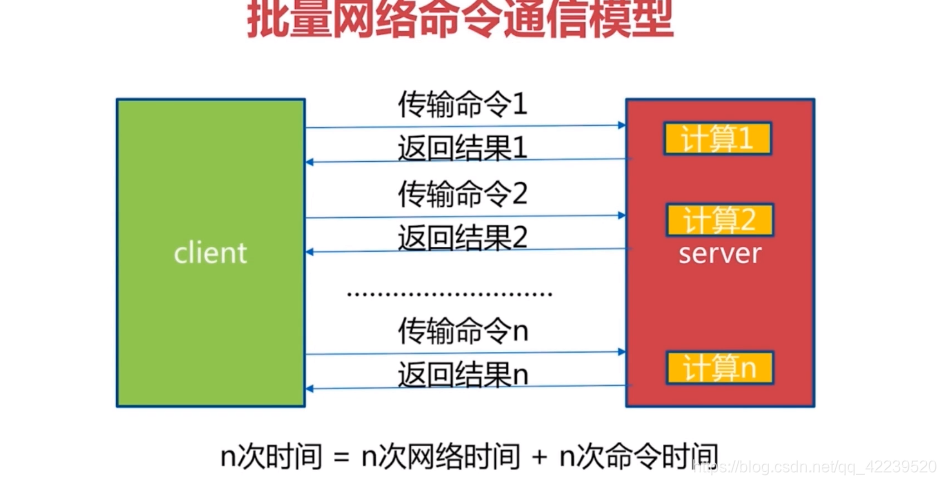
多条指令
流水线技术不仅仅是为了减少由于往返时间而导致的延迟成本的一种方式,它实际上大大提高了您在给定Redis服务器中每秒可执行的总操作量
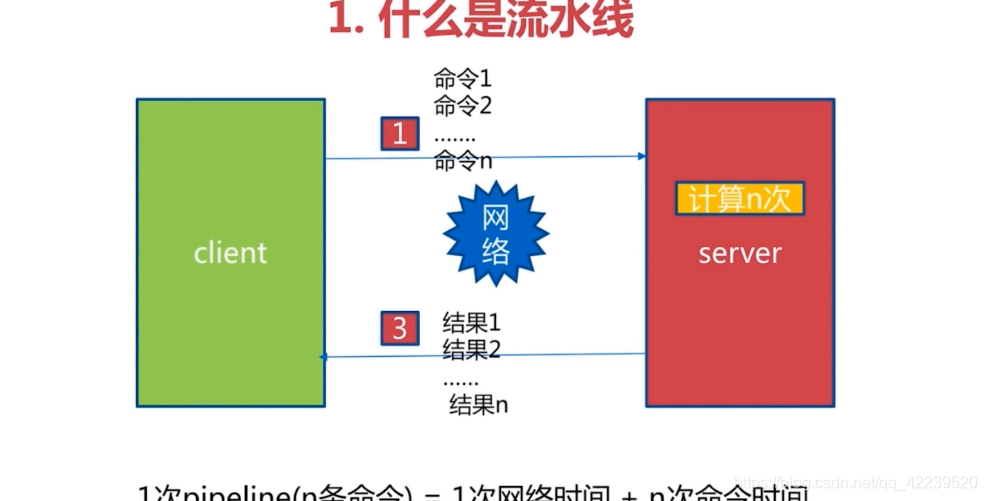
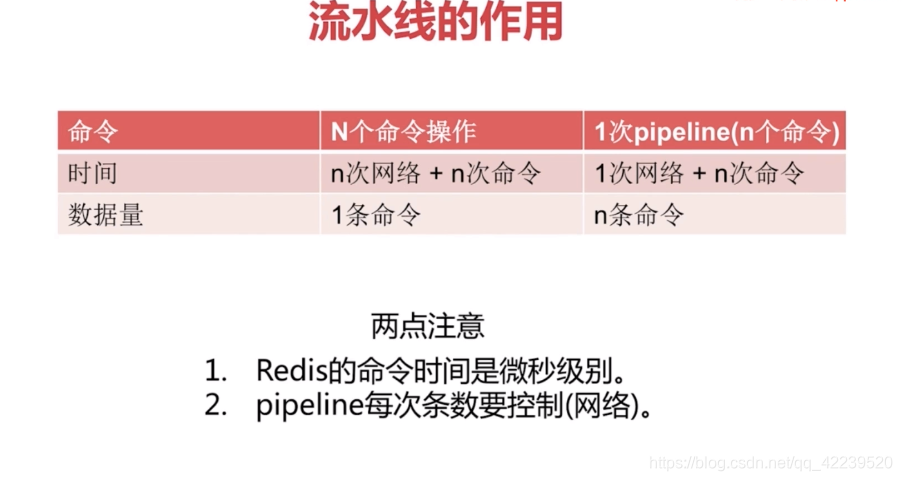
原始:
def raw():
start = time.time()
for x in range(100):
redis.lpush("user:xx:message", 'message:%s'%x)
redis.rpush('user:yy:message','haha%s'%x)
end = time.time()
print('耗时%0.2fs' % (end - start)) #耗时8.35s 使用pipeline:
def PipeLine():
with redis.pipeline() as p:
start = time.time()
for x in range(100):
p.lpush("user:xx:message", 'message:%s' % x).rpush('user:yy:message','haha%s'%x)
end = time.time()
print('耗时%0.2fs' % (end - start)) #耗时 0.25s建议:
1. 注意每次pipeline携带的数据量
2. pipeline每次只能作用在一个Redis节点上