HBase隶属于hadoop生态系统,它参考了谷歌的BigTable建模,实现的编程语言为 Java, 建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。它仅能通过主键(row key)和主键的range来检索数据,主要用来存储非结构化和半结构化的松散数据。与hadoop一样,HBase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。HBase数据库中的表一般有这样的特点:
- 大:一个表可以有上亿行,上百万列
- 面向列: 面向列(族)的存储和权限控制,列(族)独立检索
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
体系架构:
Client的主要功能:
- 使用HBase的RPC机制与HMaster和HRegionServer进行通信
- 对于管理类操作,Client与HMaster进行RPC
- 对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper功能:
- 保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
- 实时监控Region server的上线和下线信息,并实时通知给Master
- 存储所有Region的寻址入口和HBase的table元数据
HMaster功能:
- 管理HRegionServer,实现其负载均衡
- 管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上
- 监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态)
HRegionServer功能:
- Region server维护Master分配给它的region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region
小结:
·client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低
·HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化
数据模型:
-
Table: 与传统关系型数据库类似,HBase以表(Table)的方式组织数据,应用程序将数据存入HBase表中
-
Row: HBase表中的行通过 RowKey 进行唯一标识,不论是数字还是字符串,最终都会转换成字段数据进行存储;HBase表中的行是按RowKey字典顺序排列
-
Column Family: HBase表由行和列共同组织,同时引入列族的概念,它将一列或多列组织在一起,HBase的列必须属于某一个列族,在创建表时只需指定表名和至少一个列族
-
Cell: 行和列的交叉点称为单元格,单元格的内容就是列的值,以二进制形式存储,同时它是版本化的
-
version: 每个cell的值可保存数据的多个版本(到底支持几个版本可在建表时指定),按时间顺序倒序排列,时间戳是64位的整数,可在写入数据时赋值,也可由RegionServer自动赋值
注意:
- HBase没有数据类型,任何列值都被转换成字符串进行存储与关系型数据库在创建表时需明确包含的列及类型不同,HBase表的每一行可以有不同的列
- 相同RowKey的插入操作被认为是同一行的操作。即相同RowKey的二次写入操作,第二次可被可为是对该行某些列的更新操作
- 列由列族和列名连接而成, 分隔符是冒号,如d:Name(d:列族名,Name:列名)
小结:
- HBase不支持条件查询和Order by等查询,读取记录只能按Row key(及其range)或全表扫描
- 在表创建时只需声明表名和至少一个列族名,每个Column Family为一个存储单元
- 设计一个HBase表在实际应用中强烈建议使用单列族
- Column不用创建表时定义即可以动态新增,同一Column Family的Columns会群聚在一个存储单元上,并依Column key排序,因此设计时应将具有相同I/O特性的Column设计在一个Column Family上以提高性能。注意:这个列是可以增加和删除的,这和我们的传统数据库很大的区别。所以他适合非结构化数据
- HBase通过row和column确定一份数据,这份数据的值可能有多个版本,不同版本的值按照时间倒序排序,即最新的数据排在最前面,查询时默认返回最新版本。
- Timestamp默认为系统当前时间(精确到毫秒),也可以在写入数据时指定该值
·每个单元格值通过4个键唯一索引,tableName+RowKey+ColumnKey+Timestamp=>value - 存储类型
- TableName 是字符串
- RowKey 和 ColumnName 是二进制值(Java 类型 byte[])
- Timestamp 是一个 64 位整数(Java 类型 long)
- value 是一个字节数组(Java类型 byte[])
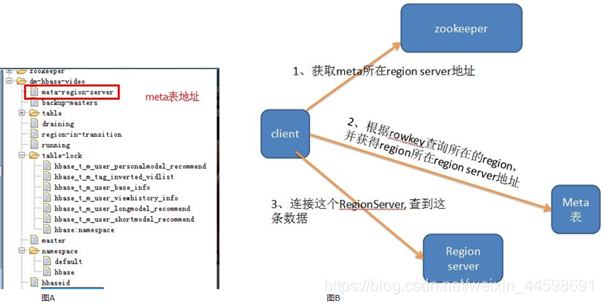
HBase寻址,Client访问用户数据时如何找到某个row key所在的region?
0.94- 版本,Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,如下图: 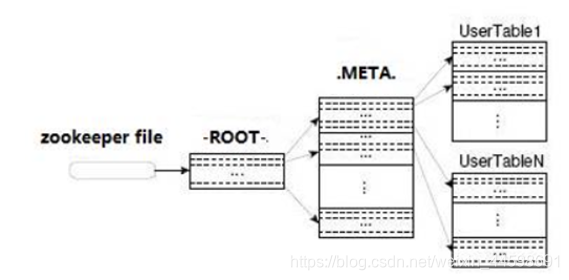
0.96+版本删除了root 表,改为zookeeper里面的文件,如下图 A, 以读为例,寻址示意图如B: