一、Beats 轻量型数据采集器
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。

二、实现logstash结合filebeat采集kafka系统日志
架构图:
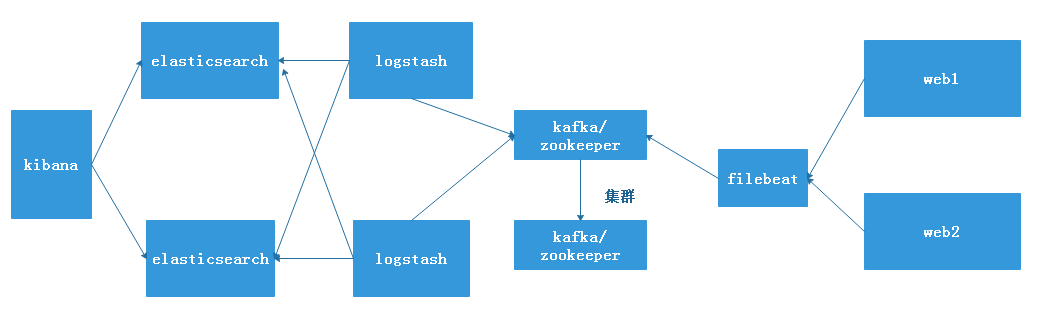
环境准备:
A主机:elasticsearch主机,IP地址:192.168.7.100
B主机:logstash主机:IP地址:192.168.7.102
C主机:filebeat主机, IP地址:192.168.7.103
D主机:kafka/zookeeper IP地址:192.168.7.104
E主机:kafka/zookeeper IP地址:192.168.7.105
1、官网下载filebeat并安装filebeat包
官方下载地址:https://www.elastic.co/cn/downloads/past-releases#filebeat
官方文档:https://www.elastic.co/guide/en/beats/filebeat/6.8/filebeat-configuration.html
1、官网下载安装filebeat包
[root@filebate ~]# yum install filebeat-6.8.1-x86_64.rpm -y
2、修改filebeat配置文件,将filebeat收集的日志存放在kafka中
[root@filebate tmp]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
- /var/log/messages
fields:
host: "192.168.7.103"
type: "filebeat-syslog-7-103"
app: "syslog"
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch: #注释掉此行
# Array of hosts to connect to.
#hosts: ["192.168.7.100:9200"] # 注释掉此行
output.kafka: # 写入到kafka主机内
hosts: ["192.168.7.104:9092","192.168.7.105:9092"] # 写入kafka的IP地址
topic: "filebeat-systemlog-7-103"
partition.round_robin:
reachable_only: true
required_acks: 1 # 本地写入完成
compression: gzip # 开启压缩
max_message_bytes: 1000000 # 消息最大值
3、启动filebeat服务
[root@filebate tmp]# systemctl start filebeat [root@filebate tmp]# systemctl status filebeat [root@filebate tmp]# ps -ef |grep filebeat root 5464 1 0 23:11 ? 00:00:00 /usr/share/filebeat/bin/filebeat -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat root 5488 1299 0 23:33 pts/0 00:00:00 grep --color=auto filebeat
2、在kafka集群主机上进行测试
1、测试kafka集群主机是否已经写入数据
[root@web1 ~]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.7.104:2181 192.168.7.105:2181 __consumer_offsets connect-test filebeat-systemlog-7-103 filebeat-systemlog-7-108 hello kafka-nginx-access-log-7-101 kafka-syslog-log-7-101 logstash [root@tomcat-web2 ~]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.7.104:2181 192.168.7.105:2181 __consumer_offsets connect-test filebeat-systemlog-7-103 filebeat-systemlog-7-108 hello kafka-nginx-access-log-7-101 kafka-syslog-log-7-101 logstash
3、修改logstash主机的配置文件
1、在/etc/logstash/conf.d目录下创建一个配置文件,采集kafka的日志
[root@logstash conf.d]# vim kafa-to-es.conf
input {
kafka {
topics => "filebeat-systemlog-7-103" # 与filebeat的配置文件对应
bootstrap_servers => "192.168.7.105:9092" # 与filebeat集群主机的leader主机IP地址对应
codec => "json"
}}
output {
if [fields][app] == "syslog" { # app类型要与filebeat主机的app对用。
elasticsearch {
hosts => ["192.168.7.100:9200"] # 转发到elasticsearch服务器上
index => "filebeat-syslog-7-103-%{+YYYY.MM.dd}"
}}
}
2、重新启动logstash服务
# systemctl restart logstash
3、在head插件上查看是否有日志收集到,此时已经收集到日志
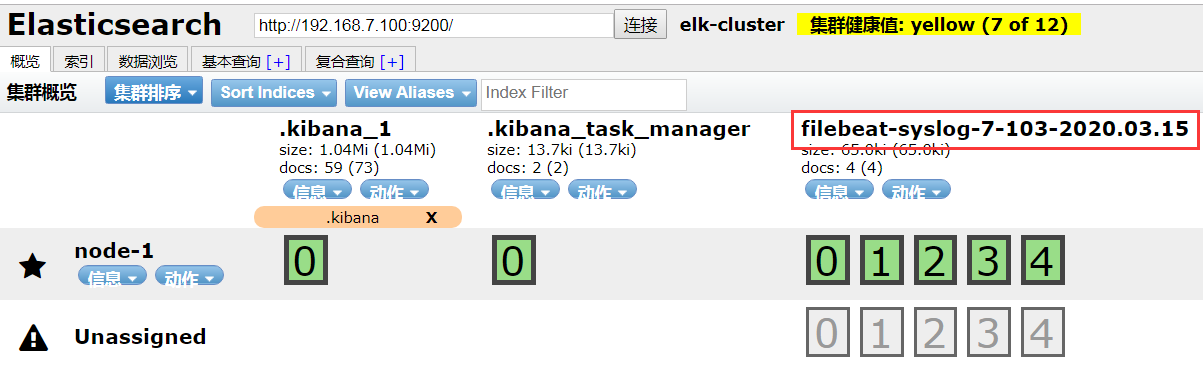
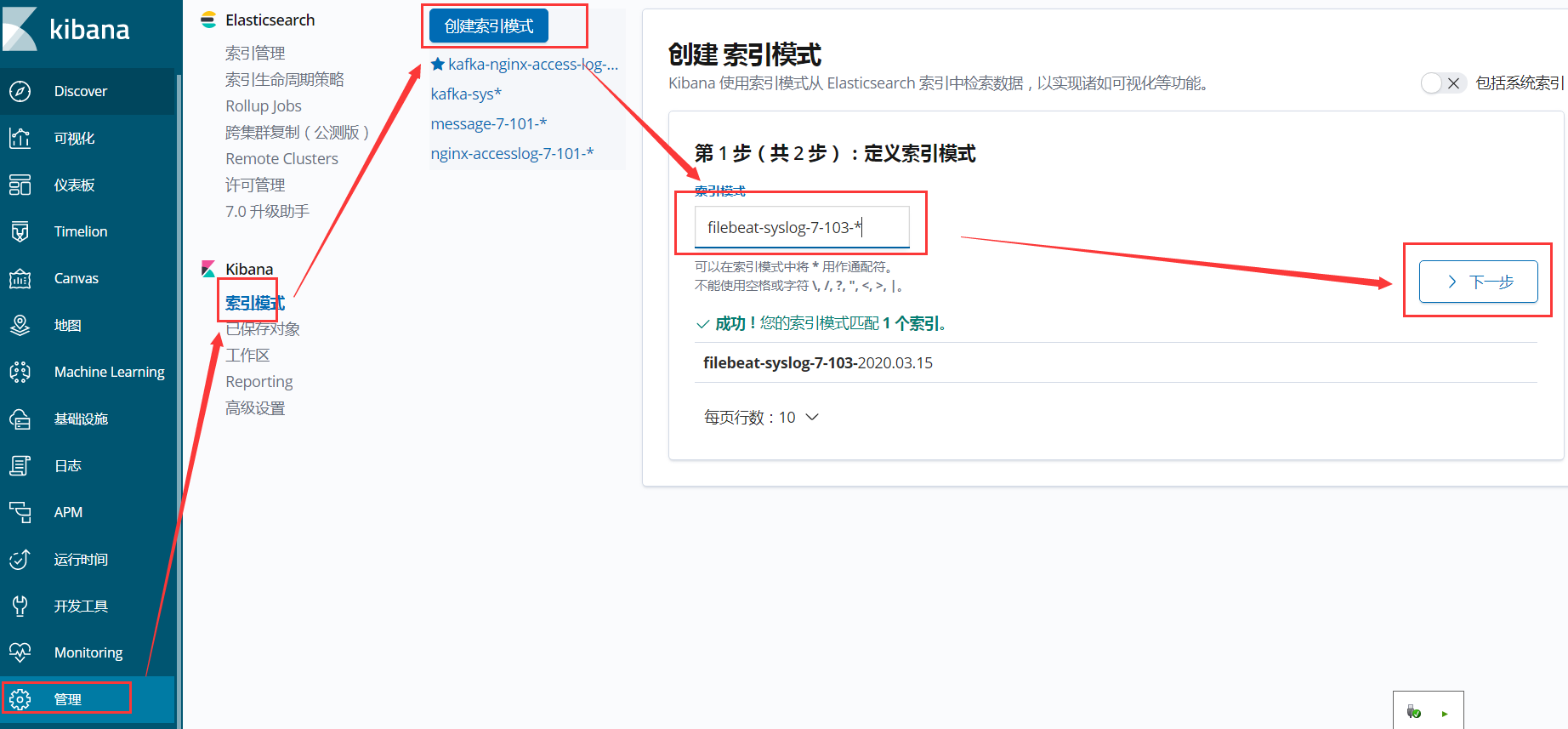
4、在kibana主机上创建索引
1、创建索引
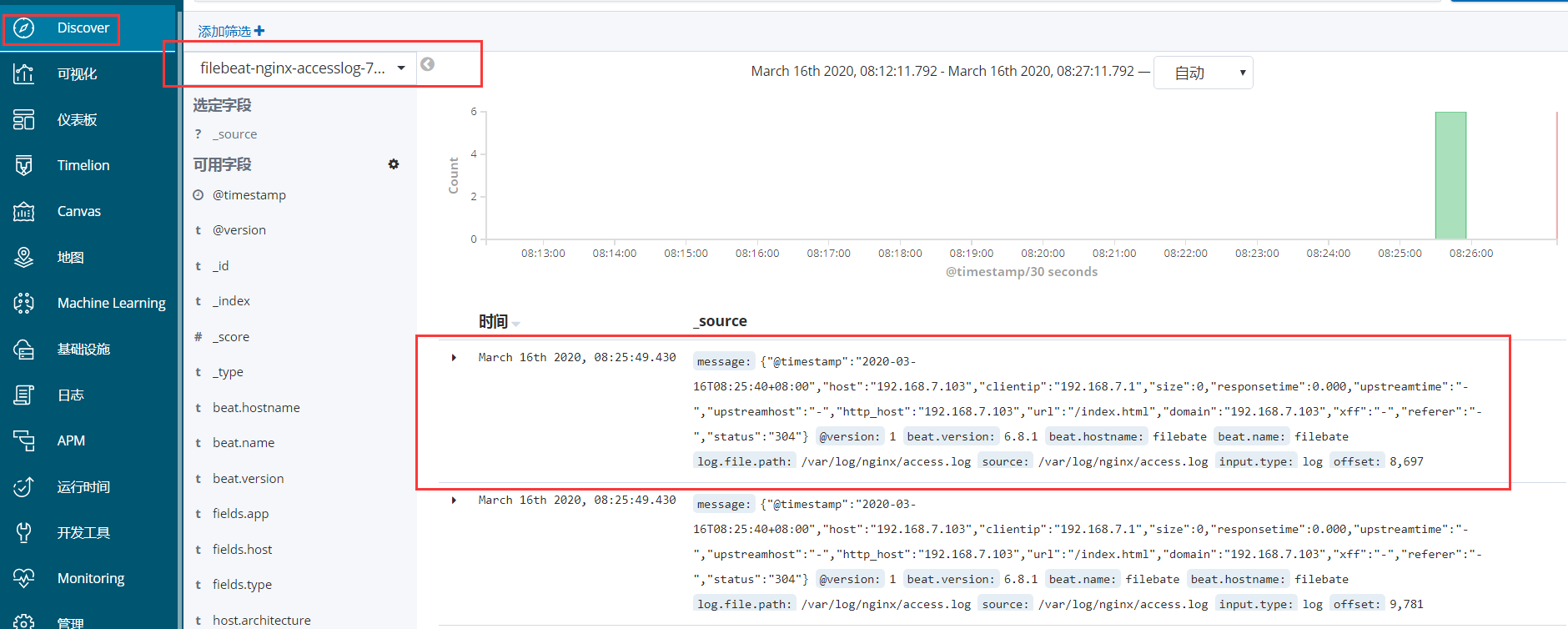
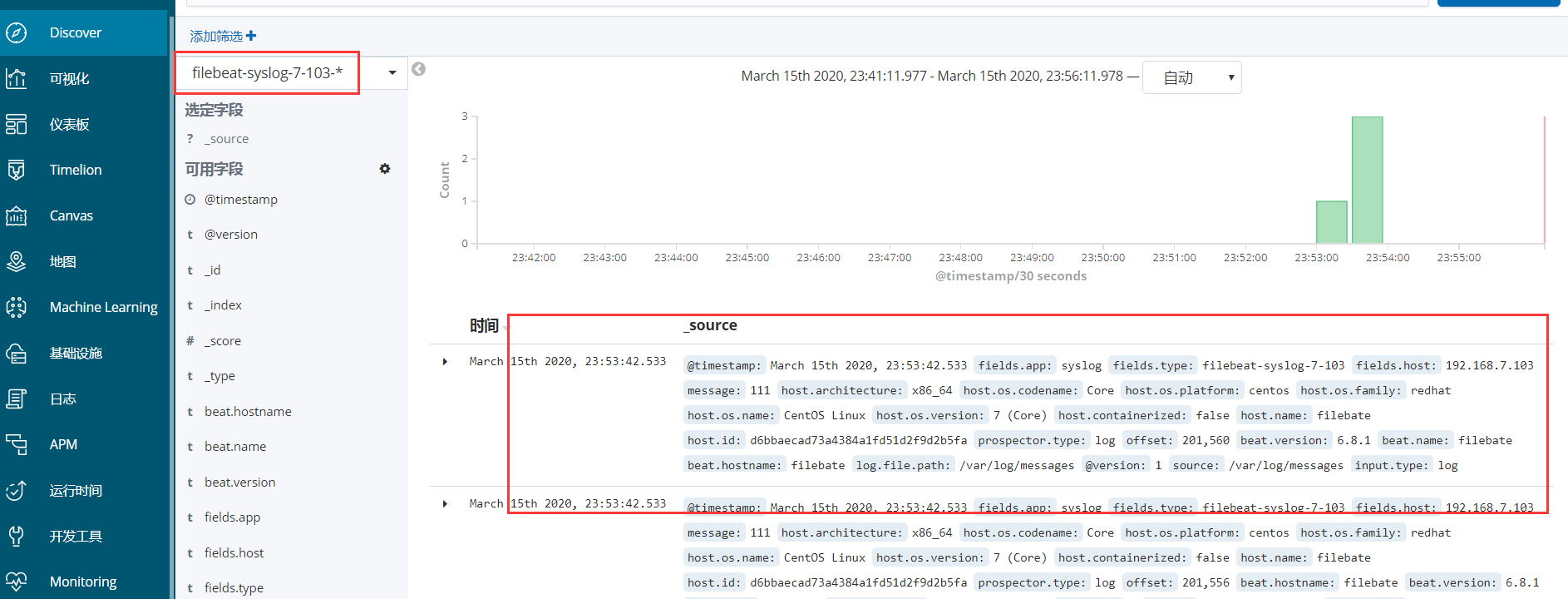
2、此时就在discover选项中可以看到日志信息
三、logstash结合filebeat收集kafka系统日志及nginx日志
1、filebeat收集系统日志和nginx日志写入到kafka
1、源码编译安装nginx,这里就不再细讲了
2、修改filebeat配置文件,收集系统日志和nginx日志,写入到kafka中
[root@filebate tmp]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
fields:
host: "192.168.7.103"
type: "filebeat-syslog-7-103"
app: "syslog"
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
host: "192.168.7.103"
type: "filebeat-nginx-accesslog-7-103"
app: "nginx"
output.kafka: # 在最后一行开始添加
hosts: ["192.168.7.104:9092","192.168.7.105:9092"] #kafka集群的IP地址
topic: "filebeat-systemlog-7-103"
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000
重新启动fielbeat服务
#systemctl restart filebeat
3、查看关键的配置信息
[root@filebate tmp]# grep -v "#" /etc/filebeat/filebeat.yml |grep -v "^$"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
fields:
host: "192.168.7.103"
type: "filebeat-syslog-7-103"
app: "syslog"
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
host: "192.168.7.103"
type: "filebeat-nginx-accesslog-7-103"
app: "nginx"
filebeat.config.modules: #默认存在
path: ${path.config}/modules.d/*.yml #默认存在
reload.enabled: false # 默认存在
setup.template.settings: #默认存在
index.number_of_shards: 3 #默认存在
setup.kibana: #默认存在
processors: #默认存在
- add_host_metadata: ~ #默认存在
- add_cloud_metadata: ~ #默认存在
output.kafka: #在最后一行开始添加
hosts: ["192.168.7.104:9092","192.168.7.105:9092"]
topic: "filebeat-systemlog-7-103"
partition.round_robin:
reachable_only: true
required_acks: 1
compression: gzip
max_message_bytes: 1000000
2、测试kafka集群主机
1、查看此时已经有nginx和系统日志数据已经写入
[root@web1 ~]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.7.104:2181 192.168.7.105:2181 __consumer_offsets connect-test filebeat-systemlog-7-103 filebeat-systemlog-7-108 hello kafka-nginx-access-log-7-101 kafka-syslog-log-7-101 logstash [root@tomcat-web2 ~]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.7.104:2181 192.168.7.105:2181 __consumer_offsets connect-test filebeat-systemlog-7-103 filebeat-systemlog-7-108 hello kafka-nginx-access-log-7-101 kafka-syslog-log-7-101 logstash
3、在logstash提取kafka日志到elasticsearch主机
1、在logstash主机的/etc/logstash/conf.d目录下创建一个采集kafka日志的文件
input {
kafka {
topics => "filebeat-systemlog-7-103"
bootstrap_servers => "192.168.7.104:9092" # 采集kafka一个主机的信息
codec => "json"
}
}
output {
if [fields][app] == "syslog" { # app类型与filebeat主机的要一致
elasticsearch {
hosts => ["192.168.7.100:9200"] #系统日志转到elasticsearch主机上
index => "filebeat-syslog-7-103-%{+YYYY.MM.dd}"
}}
if [fields][app] == "nginx" { # app类型要与filebeat主机的要一致
elasticsearch {
hosts => ["192.168.7.100:9200"] # 转到elasticsearch主机上
index => "filebeat-nginx-accesslog-7-103-%{+YYYY.MM.dd}"
}}
}
2、重新启动logstash服务
# systemctl restart logstash
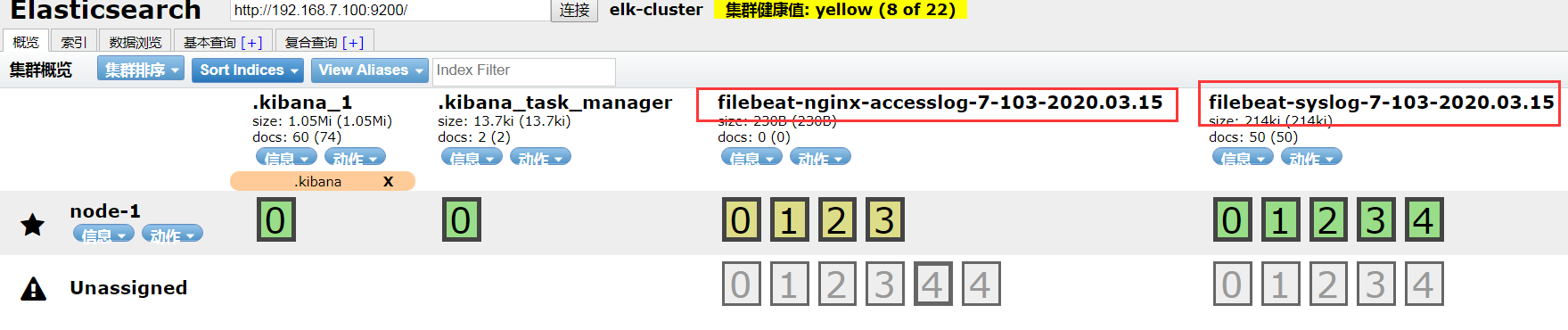
3、在head插件里查询此时已经收集到的两个日志的名称
4、 在kibana主机上创建索引
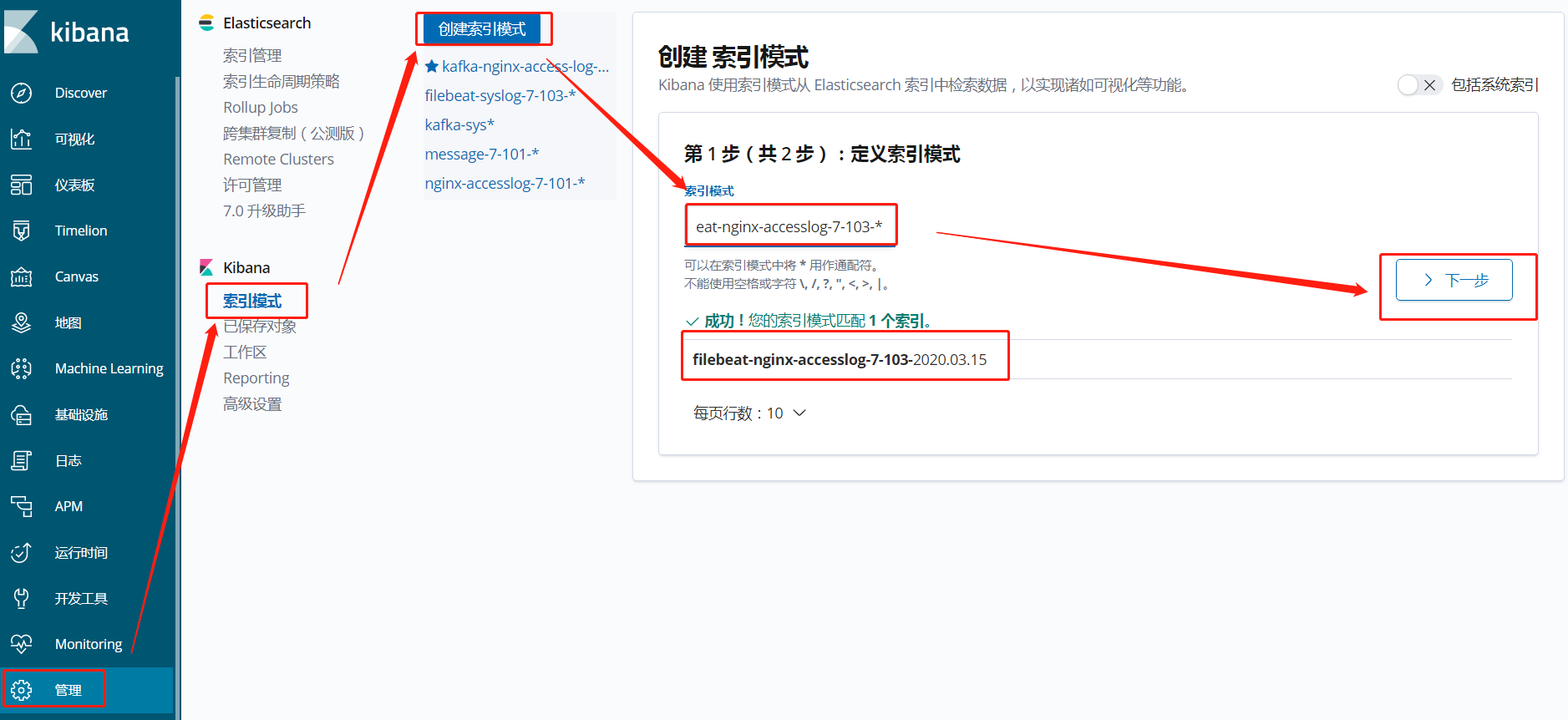
1、在kibana网页上创建索引
2、在discover查询创建的索引信息