Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。本节将对 RDD 的基本概念及与 RDD 相关的概念做基本介绍,以及在Spark RDD的基础上的简单使用。
1.RDD的基本概念
RDD 是Spark提供的最重要的一种抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,然后以函数式操作集合的方式进行各种并行的操作。
简单的来说,就是把RDD理解为一个分布式的对象集合,本质上是一种 只读的分区记录集合。
每个RDD 可以分成对个分区,每个分区就是一个数据集片段。一个RDD的可以保存到集群中的不同结点上,从而可以在集群中的不同节点上进行同时并行的计算。
RDD的分区和工作节点的分布关系如下:

2.使用RDD读取hdfs的文件,并调用spark算子进行wordcount的程序运算
注意:本程序在pycharm的环境下进行运行和使用,如果没有配置好的朋友,请配置好了pycharm后再往后查看。
from pyspark import SparkContext,SparkConf
conf = SparkConf().setAppName('spark_rdd test')
sc = SparkContext(conf=conf)
# word count
text_file = sc.textFile("你的路径/test.txt")
context = text_file.flatMap(lambda line:line.split(' ').map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y))
count.saveAsTextFile("output")
3.使用spark算子过滤元素,并对数据生成(x,x)的元组,再调用action算子输出到本地
conf = SparkConf().setAppName('spark_rdd text')
sc = SparkContext(conf=conf)
data = [4, 5, 7, 9, 3]
distData = sc.parallelize(data, numSlices=10)
def my_add(l):
result = False
if l>5:
result = True
return result
def my_add2(l):
return (l,l)
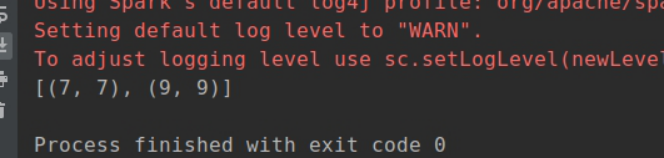
result = distData.filter(my_add).map(my_add2).collect()
print(result)
运行结果:
4.初始化RDD对象,并赋值[1,10]的集合,求出这个集合的所有元素的和
conf = SparkConf().setAppName('spark_rdd test')
sc = SparkContext(conf=conf)
rdd = sc.parallelize(rang(1,10))
m = rdd.reduce(lambda a,b:a+b)
print(m)
结果:

5.Spark SQL的简单使用
5.1读取people.json文件
from pyspark improt SparkContext
from pyspark import SQLContext
sc = SparkContext('local', 'my pyspark')
spark = SQLContext(sc)
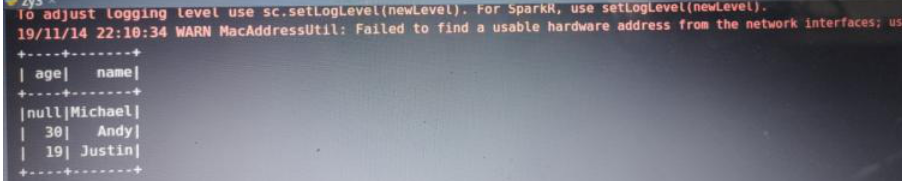
df = spark.read.json('你的spark路径/examples/src/main/resources/people.json')
df.show()
结果:
5.2 调用createDataFream和pyspark.Row创建DataFrame对象并输出该文件的格式和内容
from pyspark improt SparkContext
from pyspark import SQLContext
rdd = sc.parallelize(
[
Row(name='Michael',age=20),
Row(name='Andy',age=20),
Row(name='Just',age=20)
])
df1 = spark.createDataFrame(rdd)
df1.show()
5.3 从上面生成的DataFrame对象中按照age的字段进行筛选出大于20的数据
from pyspark improt SparkContext
from pyspark import SQLContext
rdd = sc.parallelize(
[
Row(name='Michael',age=20),
Row(name='Andy',age=20),
Row(name='Just',age=20)
])
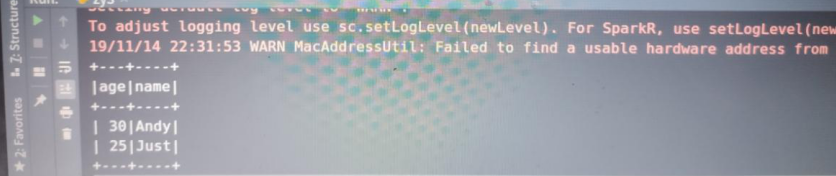
df1 = spark.createDataFrame(rdd)
df1.fillter(df1['age']>20).show()
结果:
5.4 按“age”字段进行组合统计
from pyspark improt SparkContext
from pyspark import SQLContext
rdd = sc.parallelize(
[
Row(name='Michael',age=20),
Row(name='Andy',age=20),
Row(name='Just',age=20)
])
df1 = spark.createDataFrame(rdd)
df1.groupBy('age').count().show()
结果:
6.Spark Steaming的使用
6.1 创建一个StreamContext对象并以5秒作为监听数据流
from pyspark improt SparkContext,SparkConf
from pyspark.streaming import StreamingContext
conf = SparkConf().setAppName('spark-stream').setMaster('local[2]')
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc,5)
6.2 使用Streaming 监听一个文件的流入,并执行wordcount程序
from pyspark import SQLContext
from pyspark import SparkConf,SparkContext
from pyspark.streaming import StreamingContext
conf = SparkConf().setAppName('spark-streaming').setMaster('local[2]')
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 5)
lines = ssc.textFileStream('file:///home/ouguangji/桌面') #你自己设定的目录
counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word:(word,1)).\
reduceByKey(lambda a,b:a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
这样就开启了Streaming,然后 我们只需要cp 文件 到你设定的目录下,就会对这个文件执行wordcount程序并输出到print中。
结果:



今天的学习就到这里啦!
当你的才华还撑不起你的野心的时候,
你就应该静下心来学习;
当你的能力还驾驭不了你的目标时,
就应该沉下心来,历练.
