1 SQLContext的使用
Spark1.x中Spark SQL的入口:SQLContext
The entry point into all functionality in Spark SQL is the SQLContext class, or one of its descendants. To create a basic SQLContext, all you need is a SparkContext.
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
1.1 编程
1)在pom.xml中添加依赖
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
</properties>
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- sparksql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>2)SQLContextApp.scala
package com.lihaogn.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* SQLContext的使用
*/
object SQLContextApp {
def main(args: Array[String]): Unit = {
val path=args(0)
// 1) 创建相应的Context
val sparkConf =new SparkConf()
val sc=new SparkContext(sparkConf)
val sqlContext=new SQLContext(sc)
// 2) 相关的处理:json
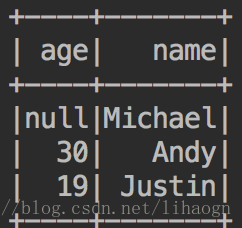
val people=sqlContext.read.format("json").load(path)
people.printSchema()
people.show()
// 3) 关闭资源
sc.stop()
}
}
3)提交运行
spark-submit \
--name SQLContextApp \
--class com.lihaogn.spark.SQLContextApp \
--master local[2] \
/Users/Mac/my_lib/sql-1.0.jar \
/Users/Mac/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json4)结果

2 HiveContext的使用
In addition to the basic SQLContext, you can also create a HiveContext, which provides a superset of the functionality provided by the basic SQLContext. Additional features include the ability to write queries using the more complete HiveQL parser, access to Hive UDFs, and the ability to read data from Hive tables. To use a HiveContext, you do not need to have an existing Hive setup, and all of the data sources available to a SQLContext are still available.
Spark1.x中Spark SQL的入口:HiveContext
2.1 编程
1)pom.xml 添加依赖
<!-- 使用hiveContext需要的依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>2)HiveContextApp.scala
package com.lihaogn.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
/**
* HiveContext的使用
* 使用时需要通过 --jars 将MySQL驱动包传递到classpath
*/
object HiveContextApp {
def main(args: Array[String]): Unit = {
// 1) 创建相应的Context
val sparkConf =new SparkConf()
val sc=new SparkContext(sparkConf)
val hiveContext=new HiveContext(sc)
// 2) 相关的处理:载入表
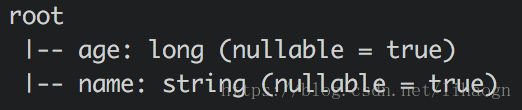
hiveContext.table("student").show
// 3) 关闭资源
sc.stop()
}
}
3)编译
mvn clean package -DskipTests4)提交运行
spark-submit \
--name HiveContextApp \
--class com.lihaogn.spark.HiveContextApp \
--master local[2] \
--jars /Users/Mac/software/mysql-connector-java-5.1.27-bin.jar \
/Users/Mac/my_lib/sql-1.0.jar5)结果
3 SparkSession的使用
Spark2.x中Spark SQL的入口:SparkSession
The entry point into all functionality in Spark is the SparkSession class. To create a basic SparkSession, just use SparkSession.builder():
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._3.1 编程
1)SparkSessionApp.scala
package com.lihaogn.spark
import org.apache.spark.sql.SparkSession
/**
* SparkSession的使用
*/
object SparkSessionApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkSessionApp").master("local[2]").getOrCreate()
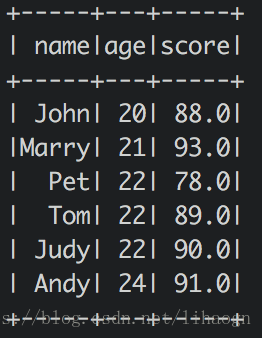
val people = spark.read.json("/Users/Mac/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json")
people.show()
spark.stop()
}
}
2)运行结果