Spark SQL is a Spark module for structured data processing.
1)为什么需要SQL
- 事实上的标准
- 易学易用
- 受众面大
2)特点
1) Integrated
Seamlessly mix SQL queries with Spark programs.
Spark SQL lets you query structured data inside Spark programs, using either SQL or a familiar DataFrame API. Usable in Java, Scala, Python and R.2) Uniform Data Access
Connect to any data source the same way.
DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources.
3)Hive Integration
Run SQL or HiveQL queries on existing warehouses.
Spark SQL supports the HiveQL syntax as well as Hive SerDes and UDFs, allowing you to access existing Hive warehouses.
4)Standard Connectivity
Connect through JDBC or ODBC.
A server mode provides industry standard JDBC and ODBC connectivity for business intelligence tools.
5)Performance & Scalability
Spark SQL includes a cost-based optimizer, columnar storage and code generation to make queries fast. At the same time, it scales to thousands of nodes and multi hour queries using the Spark engine, which provides full mid-query fault tolerance. Don’t worry about using a different engine for historical data.
应用并不局限于SQL
访问hive、json、parquet等文件的数据
SQL只是spark SQL的一个功能而已
提供了SQL、dataframe、dataset的API
3)愿景
- write less code
- read less data
- let the optimizer do the hard work
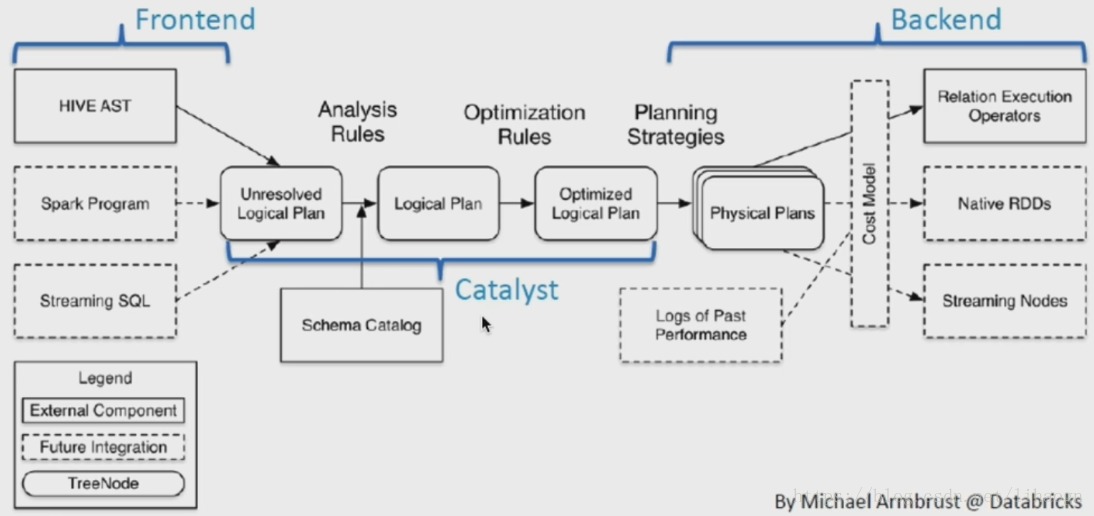
4)架构