Spark 安装可参考文章:CentOS 7.6 安装 Spark 1.6.1
一、运行环境
CentOS 7.6
Hadoop 2.6.0
jdk 1.7.0_75
Scala 2.10.7
Spark 1.6.1
二、二度好友算法
2.1 问题描述
好友推荐功能简单的说是这样一个需求:
预测某两个人是否认识,并推荐为好友,并且某两个非好友的用户,他们的共同好友越多,那么他们越可能认识。
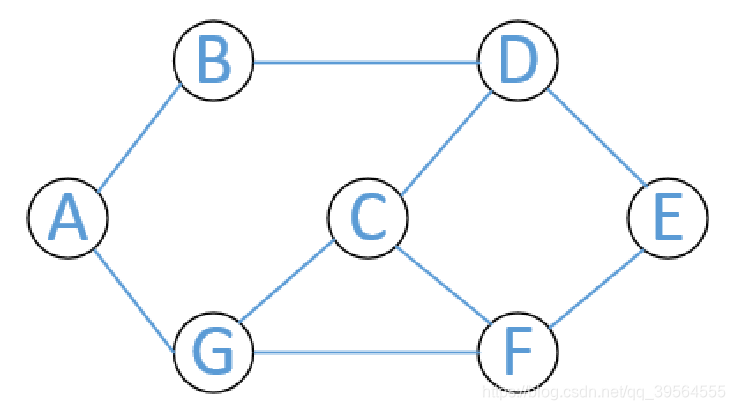
以QQ好友举例,顶点A、B、C到G分别是QQ用户,两顶点之间的边表示两顶点代表的用户之间相互关注。比如,B、G有共同好友A,应该推荐B、G认识,而D、F有两个共同好友C、E,那么更加应该推荐D、F认识。
2.2 输入数据
1 2,3,4,5,6,7,8
2 1,3,4,5,7
3 1,2
4 1,2,6
5 1,2
6 1,4
7 1,2
8 1
2.3 算法讲解
1. Map操作
对输入数据的每一行进行 map 操作,生成直接好友键值对和间接好友键值对
例如:3 1,2
生成直接好友键值对 (3,[1,-1]) (3,[2,-1])
生成间接好友键值对 (1,[2,3]) (2,[1,3]) ,其中 (1,[2,3]) 表示 1 和 2 为间接好友,通过 3 认识。
2. Reduce操作
对每一个用户生成一个 Map<Long,List> ,保存推荐的好友和共同好友列表
2.4 程序代码
vi FriendRecommendation.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object FriendRecommendation {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("FriendRecommendation").setMaster("local")
val sc = new SparkContext(sparkConf)
val input = "hdfs://Namenode:9000//friend2.txt"
val output = "hdfs://Namenode:9000//friends2"
val records = sc.textFile(input)
val pairs = records.flatMap(line => {
val tokens = line.split(" ")//用空格隔开
val person = tokens(0).toLong
val friends = tokens(1).split(",").map(_.toLong).toList
val mapperOutput = friends.map(directFriend => (person, (directFriend, -1.toLong)))
val result = for {
fi <- friends
fj <- friends
possibleFriend1 = (fj, person)
possibleFriend2 = (fi, person)
if (fi != fj)
} yield {
(fi, possibleFriend1) :: (fj, possibleFriend2) :: List()
}
mapperOutput ::: result.flatten
//flatten可以把嵌套的结构展开.
//scala> List(List(1,2),List(3,4)).flatten
//res0: List[Int] = List(1, 2, 3, 4)
})
// note that groupByKey() provides an expensive solution
// [you must have enough memory/RAM to hold all values for
// a given key -- otherwise you might get OOM error], but
// combineByKey() and reduceByKey() will give a better
// scale-out performance
val grouped = pairs.groupByKey()
val result = grouped.mapValues(values => {
val mutualFriends = new collection.mutable.HashMap[Long, List[Long]].empty
values.foreach(t2 => {
val toUser = t2._1
val mutualFriend = t2._2
val alreadyFriend = (mutualFriend == -1)
if (mutualFriends.contains(toUser)) {
if (alreadyFriend) {
mutualFriends.put(toUser, List.empty)
} else if (mutualFriends.get(toUser).isDefined && mutualFriends.get(toUser).get.size > 0 && !mutualFriends.get(toUser).get.contains(mutualFriend)) {
val existingList = mutualFriends.get(toUser).get
mutualFriends.put(toUser, (mutualFriend :: existingList))
}
} else {
if (alreadyFriend) {
mutualFriends.put(toUser, List.empty)
} else {
mutualFriends.put(toUser, List(mutualFriend))
}
}
})
mutualFriends.filter(!_._2.isEmpty).toMap
})
result.saveAsTextFile(output)
// formatting and printing it to console for debugging purposes...
result.foreach(f => {
val friends = if (f._2.isEmpty) "" else {
val items = f._2.map(tuple => (tuple._1, ":" + tuple._2.size)).toSeq.sortBy(_._2).reverse.map(g => "" + g._1 + " " + g._2)
items.toList.mkString(", ")
}
println(s"${f._1}: ${friends}")
})
// done
sc.stop();
}
}
三、程序运行
# 在 FriendRecommendation.scala 文件目录下创建 临时文件夹 tmp 存放中间文件
mkdir tmp
cd tmp
# 编译
scalac -cp /home/spark/spark-1.6/lib/spark-assembly-1.6.1-hadoop2.6.0.jar ../FriendRecommendation.scala
# 打包 jar 包
echo Main-class: FriendRecommendation > manifest.txt
jar cvfm FriendRecommendation.jar manifest.txt *
# 提交运行
/home/spark/spark-1.6/bin/spark-submit --class "FriendRecommendation" --master local[4] FriendRecommendation.jar
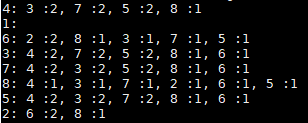
# 用户id: 推荐好友:共同好友数量, 推荐好友:共同好友数量……
4: 3 :2, 7 :2, 5 :2, 8 :1
1:
6: 2 :2, 8 :1, 3 :1, 7 :1, 5 :1
3: 4 :2, 7 :2, 5 :2, 8 :1, 6 :1
7: 4 :2, 3 :2, 5 :2, 8 :1, 6 :1
8: 4 :1, 3 :1, 7 :1, 2 :1, 6 :1, 5 :1
5: 4 :2, 3 :2, 7 :2, 8 :1, 6 :1
2: 6 :2, 8 :1
参考文章:【1】Examples | Apache Spark
【2】Quick Start - Spark 2.4.4 Documentation
【3】Spark 好友推荐解决方案
【4】Spark实现之 好友推荐
