相关文章:
LSTM 01:理解LSTM网络及训练方法
LSTM 02:如何为LSTMs准备数据
LSTM 03:如何使用Keras编写LSTMs
LSTM 04:4种序列预测模型及Keras实现
LSTM 05:如何开发 Vanilla LSTMs 和 Stacked LSTMs
LSTM 06:如何用Keras开发CNN LSTM
LSTM 07:如何用Keras开发 Encoder-Decoder LSTM
本文介绍4了个序列预测模型,以及如何在Keras中实现它们。内容如下:
- 这4个序列预测模型以及在Keras中实现。
- 将4个序列预测模型应用到常见的序列预测问题的示例。
- 在应用序列预测模型时容易陷入的陷阱及如何避免。
文章目录
5 序列预测模型
5.1 序列预测
LSTM通过学习一个函数(f(…))来工作,该函数将输入序列值(X)映射为序列值(y)。
y(t) = f(X(t))
学习的映射函数是静态的,可以将其视为接受输入变量并使用内部变量的程序。 内部变量由网络维护的内部状态表示,并在输入序列的每个值上累积或累积。 可以使用不同数量的输入或输出定义静态映射功能。 了解这一重要细节是本课程的重点。
5.2 序列预测模型
在本节中,将回顾序列预测的4个主要模型。我们将使用以下术语:
- X:序列值输入;
- u:隐藏状态值;
- y:序列值输出;
每个模型都将使用术语、图片和Keras中的示例代码进行解释。 着重研究序列预测问题的不同类型如何映射到不同模型类型。 不要太着迷于Keras示例的细节,因为整章都致力于解释更复杂的模型类型。
5.2.1 One-to-One Model
一个一对一模型(f(…))对一个输入值(X(t))产生一个输出(y(t))。

例如:
y(1) = f(X(1))
y(2) = f(X(2))
y(3) = f(X(3))
...
第一个时间步的内部状态为零;从这一点开始,内部状态( internal state)在之前的时间步上累积。
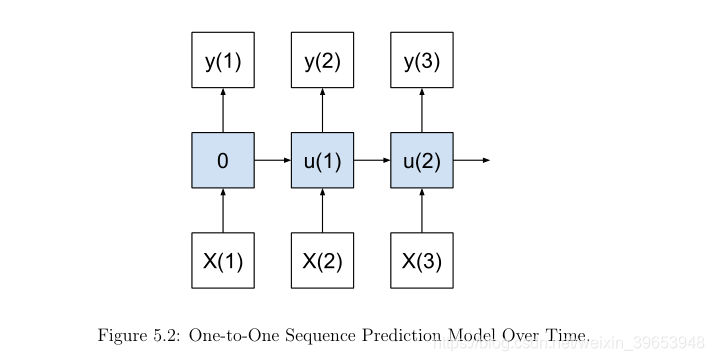
该模型适用于以一个时间步长为输入,预测一个时间步长的序列预测问题。例如:
- 预测时间序列中的下一个实际值。
- 预测句子中的下一个单词。
这种LSTM模型的效果很差,因为它无法跨输入或输出时间步学习。 该模型确实将所有压力施加在内部状态或内存上。 该模型的结果可以与具有输入或输出序列的模型进行对比,以查看跨时间步长的学习是否为预测增加了技巧。 我们可以通过在Keras中定义一个网络来实现这一点,该网络期望输入一个时间步长,并预测输出层的一个时间步长。

Keras实现:
model = Sequential()
model.add(LSTM(..., input_shape=(1, ...)))
model.add(Dense(1))
5.2.2 One-to-Many Model
一个一对多的模型通过一个输入产生多个预测值。
y(1),y(2) = f(X(1))
考虑将时间分别计入输入和输出可能会有所帮助。

内部状态随着输出序列中每个值的产生而累积。该模型适用于序列预测问题,即我们希望为每个输入时间步长生成序列输出。例如:
- 从单个图像预测单词序列。
- 从单一事件预测一系列观察结果。
一个很好的例子是为图片生成文本描述。在Keras中,这需要卷积神经网络从图像中提取特征,然后再通过LSTM一次输出一个单词序列。 输出层预测每个输出时间步长一个观察值,并包装在TimeDistributed包装器层中,以便对于所需数量的输出时间步长多次使用同一输出层。
model = Sequential()
model.add(Conv2D(...))
...
model.add(LSTM(...))
model.add(TimeDistributed(Dense(1)))
5.2.3 Many-to-One Model
一个多对一模型根据多个输入值产生一个预测输出。
y(1) = f(X(1), X(2))
同样,将时间分别计算在输入序列和输出序列中也是有帮助的。
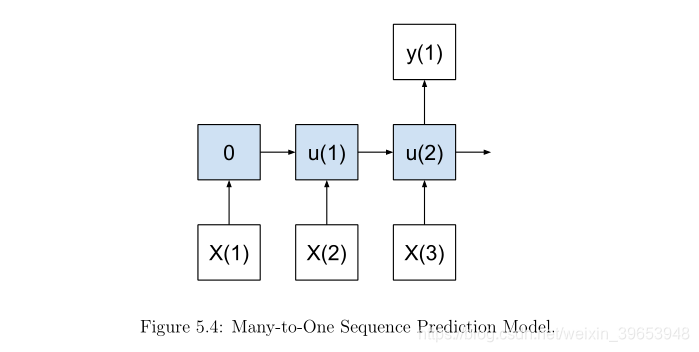
内部状态与每个输入值一起累积,然后产生最终的输出值。该模型适用于需要多个输入时间步长的序列预测问题。例如:
- 在给定一系列输入观测值的情况下,预测时间序列中的下一个实值。
- 预测单词输入序列的分类标签,如情感分析。
该模型可以在Keras中实现,就像一对一模型一样,只是输入时间步长的数目可以变化以适应问题的需要。
model = Sequential()
model.add(LSTM(..., input_shape=(steps, ...)))
model.add(Dense(1))
5.2.4 Many-to-Many Model
一个多对多模型由多个输入产生多个输出。
y(1),y(2) = f(X(1), X(2))
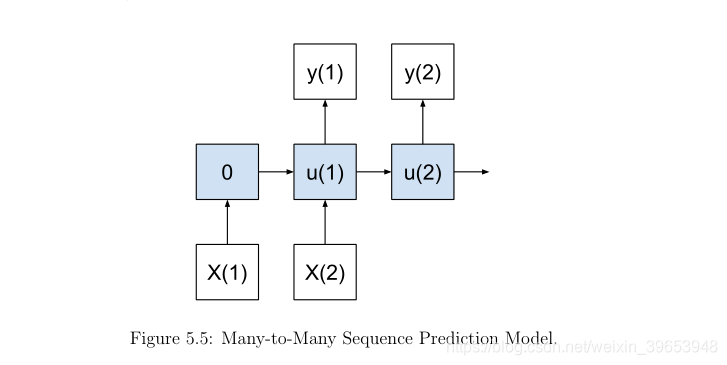
与多对一情况一样,状态会一直累积到创建第一个输出为止,但在这种情况下,会输出多个时间步长。 重要的是,输入时间步长的数量不必与输出时间步长的数量相匹配。 该模型适用于需要多个输入时间步长以预测输出时间步长序列的序列预测。 这些通常称为序列到序列(seq2seq)类型问题,并且可能是最近使用LSTM研究最多的问题。 例如:
- 将一份单词的文档概括成更短的单词序列。
- 将音频数据序列分类为单词序列。
在某种意义上,这个模型结合了多对一和一对多模型的功能。如果输入和输出时间步骤的数目是相等的,那么LSTM层必须配置为每个输入时间步返回一个值,而不是一个单一值的输入序列(如返回序列= True)和相同的致密层可以用来产生一个输出时间步的每个输入时间步骤通过TimeDistributed层包装。
model = Sequential()
model.add(LSTM(..., input_shape=(steps, ...), return_sequences=True))
model.add(TimeDistributed(Dense(1)))
如果输入和输出的时间步长不同,则可以使用编码器-解码器体系结构。将输入的时间步长映射到序列的一个固定大小的内部表示形式,然后使用这个向量作为输入来生成输出序列中的每个时间步长。
model = Sequential()
model.add(LSTM(..., input_shape=(in_steps, ...)))
model.add(RepeatVector(out_steps))
model.add(LSTM(..., return_sequences=True))
model.add(TimeDistributed(Dense(1)))
5.3 Mapping Applications to Models
我真的希望您了解这些模型以及如何将您的问题归结为上述4种类型之一。 为此,本节列出了10个不同的和不同的序列预测问题,并指出可以使用哪种模型来解决这些问题。 在每种解释中,我都给出了一个可用于解决该问题的模型的示例,但是,如果重新构建了序列预测问题,则可以使用其他模型。 将这些作为最佳建议,而不是坚不可摧的规则。
5.3.1 Time Series
- 单变量时间序列预测。 在这里,有一个具有多个输入时间步长的序列,并希望预测超出输入序列的一个时间步长。 可以将其实现为多对一模型。
- 多元时间序列预测。 在这里,将拥有多个具有多个输入时间步长的序列,并希望预测一个或多个输入序列之外的一个时间步长。 可以将其实现为多对一模型。 每个系列只是另一个输入功能。
- 多步时间序列预测:可以在其中拥有多个具有多个输入时间步长的序列,并希望预测一个或多个输入序列之外的多个时间步长。 可以将其实现为多对多模型。
- 时间序列分类。 在这里,可以有一个或多个序列,其中有多个输入时间步长作为输入,并希望输出分类标签。 可以将其实现为多对一模型。
5.3.2 Natural Language Processing
- 图片字幕。 这是有一张图片并希望生成文字描述的地方。 可以将其实现为一对多模型。
- 视频描述。 在这里,可以在视频中生成一系列图像,并希望生成文字说明。 可以使用多对多模型来实现。
- 情绪分析。 在这里可以输入文本序列,并希望生成分类标签。 可以将其实现为多对一模型。
- 语音识别。 在这里,可以输入一系列音频数据,并希望生成有关所讲内容的文本描述。 这可以通过许多模式来实现。
- 文字翻译。 在这里,可以使用一种语言的一系列单词作为输入,并希望生成另一种语言的一系列单词。 可以使用多对多模型来实现。
- 文字摘要。 在这里,有一个文本文档作为输入,并希望创建该文档的简短文本摘要作为输出。 可以使用多对多模型来实现。
5.4 Cardinality from Time Steps (not Features!)
一个常见的容易混淆的地方是将上面的序列映射模型示例与多个输入和输出特性合并在一起。序列可以由单个值组成,每个时间步一个值。
或者,一个序列可以简单地表示在时间步长的多个观测向量(例如[X1, X2]来预测给定时间步长的[y1, y2])。一个时间步的向量中的每一项都可以被认为是itd自己的独立时间序列。它不影响上述模型的描述。例如,以温度(X1)和压力(X2)一个时间步长作为输入,并预测温度(y1)和压力(y2)一个时间步长的模型是一对一模型,而不是多对多模型。

该模型确实将两个值作为输入,具有两个单独的内部状态,并预测了两个值,但是对于输入仅表示一个序列时间步长,并且将其预测为输出。 上面定义的序列预测模型的基数是指时间步长,而不是特征。
5.5 Two Common Misunderstandings
功能与时间步长的混淆导致从业人员实施LSTM时有两个主要误解:
5.5.1 Time steps as Input Features
先前时间步长的滞后观测值被框架化为模型的输入要素。 这是多层感知器使用的基于经典的基于固定窗口的输入序列预测问题的方法。 相反,应该将序列作为多个输入时间步长显示给模型(例如,多对一模型)。 这种混淆可能导致认为已经实现了多对一或多对多序列预测模型,而实际上在一个时间步中只有一个向量输入。
5.5.2 Time steps as Output Features
对未来多个时间步长的预测作为模型的输出特性。这是多层感知器和其他机器学习算法使用的经典的多步预测固定窗口方法。相反,序列预测应该由模型一次生成一个时间步长。这种混淆可能会使您认为您实现了一对多或多对多序列预测模型,而实际上在一个时间步骤中只有一个向量输出(例如,seq2vec而不是seq2seq)。
注意:将时间步长作为序列预测问题的特征是一种有效的策略,即使在使用递归神经网络时也可以提高性能。这里的重点是理解常见的陷阱,而不是在构建自己的预测问题时欺骗自己。
5.6 Further Reading
The Unreasonable Effectiveness of Recurrent Neural Networks, 2015.
参考:Jason Brownlee 《long-short-term-memory-networks-with-python》chapter 5
