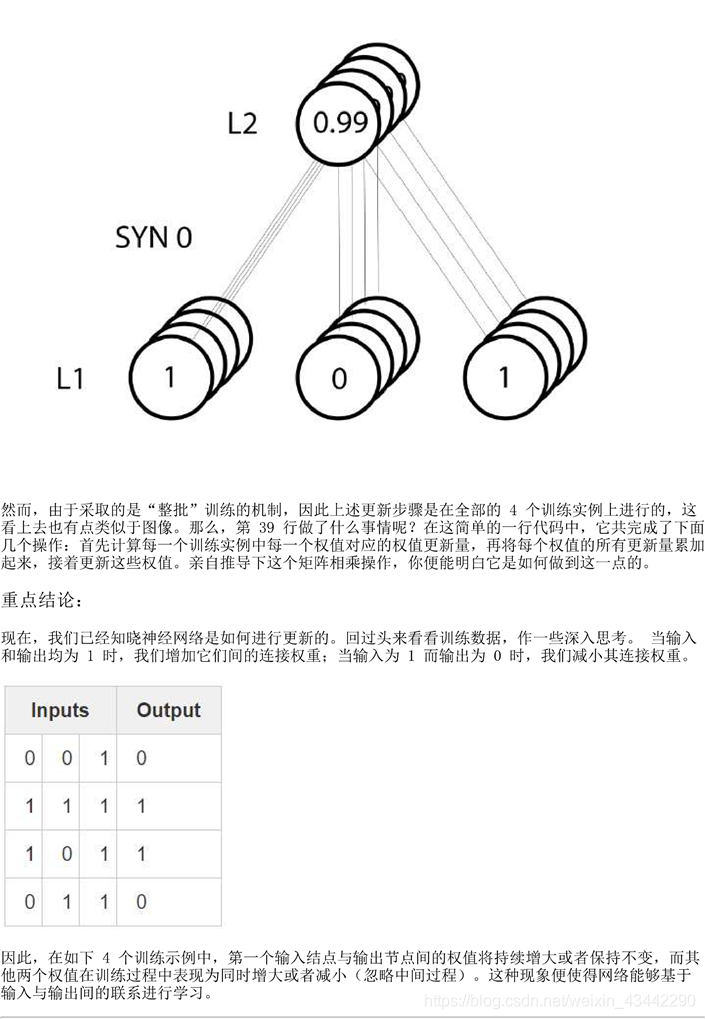
内容:




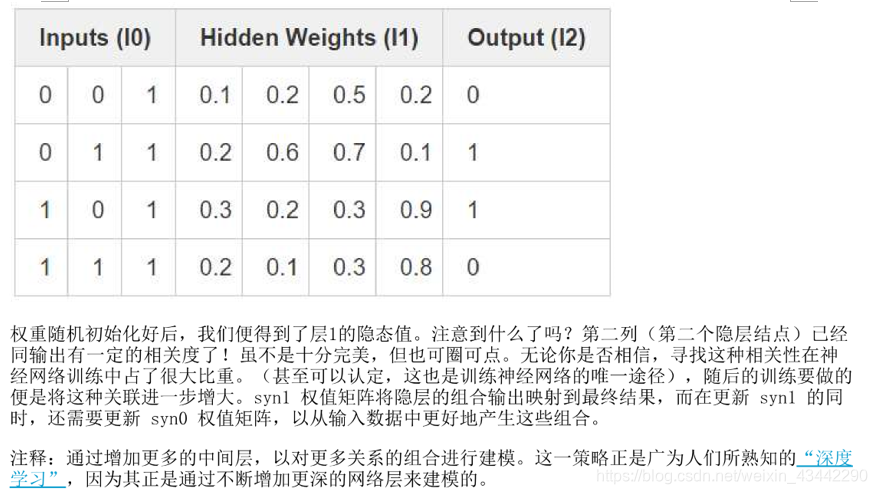
以下是一个两层神经网络的代码
import numpy as np
import pickle
# 非线性部分,“sigmoid”的函数,可以将任何值都映射到一个位于0到1范围内的值,
# 通过它,可以将实数转换为概率值,对于神经网络训练,Signomid 函数也有其非常不错的特性
# 通过“online”函数还能得到sigmod函数的导数(当形参derive 为 True 时)。
# Sigmoid 函数优异特性之一,在于只用它的输出值便可以得到其倒数值(即曲线在定点上的斜率)。若Sigmoid 的输出值用变量out表示,
# 则其倒数值可简单通过式子 out * (1 - out) 得到,这是非常高效的。
def nonlin(x, deriv=False):
if (deriv==True):
return x * (1 - x)#S函数的导数
else:
return 1 / (1 + np.exp(-x))
def load_data():
fr = open('F:\python学习\代码\神经网络\BP神经网络\data_pickle.txt', 'rb')
x = pickle.load(fr)
fr.close()
return (x)
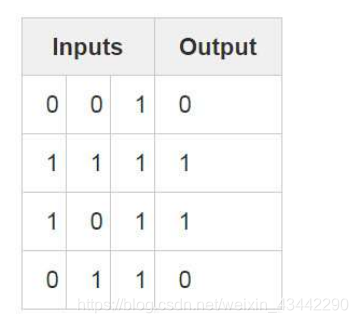
# 将输入的数据集初始化为 numpy 中的矩阵。每一行为一个“训练实例”,每一列的对应着一个输入节点。
# 这样,我们的神经网络便有 3 个输入节点,4 个训练实例。
x = np.array([[0, 0, 1],
[0, 1, 1],
[1, 0, 1],
[1, 1, 1]])
# 这行代码对输出数据集进行初始化。在本例中,为了节省空间,我们以格式水平(1行4列)定义成了数据集。
# “.T” 为转置函数。经转置后,该 y 矩阵便包含 4 行 1 列。 同我们的输入一致,每一行是一个训练实例,
# 而每一列(仅有一列)对应一个输出节点。因此,我们的网络含有3个输入,1个输出。
y = np.array([[0, 0, 1, 1]]).T
# 你的随机数设定产生种子是一个良好的习惯。这样一来,你得到的权重初始化集仍是随机分布的,但每次训练开始时,
# 得到的权重初始集分布都是完全一致的。这便于观察你的策略变动是如何影响网络训练的。
np.random.seed(1)
# 这行代码实现了该神经网络权重矩阵的初始化操作。用“sny0”来代指“零号突触”(即“输入层-第一层隐层”间权重矩阵)。
# 由于我们的神经网络只有两层(输入层与输出层),因此,想要将10层的每个神经元节点与11层的每个神经元节点相连,
# 就需要一个维度大小为(3,1)的连接矩阵。
# 关于权重的1初始化,有许多学问,这里只是练习,随机初始化的权重矩阵均值为0。
# 所谓的“神经网络”实际上就是这个权值矩阵。虽然有“层”10 和 11 ,但它们都是基于数据集的瞬间值,即层的输入输出
# 状态随不同输入数据而不同,这些状态是不需要保存的。在学习训练过程中,只需存储syno权值矩阵。
syn0 = 2 * np.random.random((3, 1)) - 1
# 本行开始就是神经网络训练代码了。本for循环迭代式地多次执行训练代码,使得我们的网络能够更好地拟合训练集。
for i in range(10000):
# 网络第一层就是我们的输入数据,X 包含4个训练实例(行),该部分实现中将同时对所有的实现进行处理,这种训练方式
# 称作“整批”训练。因此,虽然我们有 4 个不同的10行,但你可以将其整体视为单个训练实例,这样做并没有什么差别。
# (我们可以在不改动一行代码的前提下,一次性装入1000个甚至10000个实例)。
l0 = x
# 这是神经网络的前向预测阶段。基本上,首先让网络基于给定输入“试着”去预测输出。
# 接着,我们研究效果如何,以至于作出一些调整,使得在每次迭代过程中网络能够表现的更好一点。
# ( 4 x 3 ) dot ( 3 x 1 ) = ( 4 x 1 )
# 首先,将 10 与 syn0 进行矩阵相乘。然后,将计算结果传递给 sigmoid 函数。具体考虑到各个矩阵的维度。
# ( 4 x 3 ) dot ( 3 x 1 ) = ( 4 x 1 )
# 矩阵相乘是有约束的,比如等式靠中间的两个维度必须一致。而最终产生的矩阵。其行数为第一矩阵的行数,
# 列数则为第二个矩阵的列数
# 由于装入 4 个训练实例,因此最终得到了4个猜测结果,即一个( 4 x 1 )的矩阵。
# 每一个输出都对应,给定输入下网络对正确结果的一个猜测。也许这也能直观解释:
# 为什么可以“载入”任意数目的训练实例,它可以反映出网络的误差多大。
l1 = nonlin(np.dot(l0, syn0))
if (i == 1):
print(l1)
print(syn0)
#(4*1)的矩阵。每一个输出都对应,给定输入下网络对正确结果的一个猜测。
# 对应每一输入,可知 11 都对应的一个“猜测”结果。那么通过将真实的结果(y)与猜测结果(11)作减,就可以
# 对比得到网络预测的效果怎么样。11_error是一个有正数和负数组成的向量,它可以反映出网络的误差有多大。
l1_error = y - l1
print(i, l1_error, '\n')
# 这部分很复杂,单独说明。
l1_delta = l1_error * nonlin(l1, True)
syn0 += np.dot(l0.T, l1_delta)
print('over!\n', l1)
print(syn0)

此处省略很多组结果

第77行


第79行