R-CN
N
框架

简要步骤:
(1) 输入测试图像
(2) 利用选择性搜索Selective Search算法在图像中从下到上提取
2000个左右的可能包含物体的候选区域Region Proposal
(3) 因为取出的区域大小各自不同,所以需要将每个Region Proposal
缩放(warp)成统一的227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征
(将ROI输入到神经网络)
(4) 将每个Region Proposal提取到的CNN特征输入到
SVM进行分类
具体步骤则如下
步骤一:训练(或者下载)一个分类模型(比如AlexNet)
步骤二:对该模型做fine-tuning(微调)
•将分类数从1000改为21,比如20个物体类别 + 1个背景
•去掉最后一个全连接层
步骤三:特征提取
•提取图像的所有候选框(选择性搜索Selective Search)
•对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
步骤四:训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative。
IOU的定义
:
IOU定义了两个bounding box的重叠度

矩形框A、B的一个重合度IOU计算公式为:
IOU=
(A∩
B
)/
(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例:
IOU=S
I
/(S
A
+S
B
-S
I
)
非极大值抑制(Non-Maximun Suppression)
学习R-CNN算法必然要了解一个重要的概念——非极大值抑制(NMS)。比如,我们会从一张图片中找出N多个可能包含物体的Bounding-box,然后为每个矩形框计算其所属类别的概率。可以参看下图8所示。

正如上面的图片所示,假如我们想定位一个车辆,最后算法就找出了一堆的方框,每个方框都对应一个属于汽车类别的概率。我们需要判别哪些矩形框是没用的。采用的方法是非极大值抑制:先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
如此循环往复知道没有剩余的矩形框,然后找到所有被保留下来的矩形框,就是我们认为最可能包含汽车的矩形框。
R-CNN算法中NMS的具体做法:
假设有20类,2000个建议框,最后输出向量维数2000*20,则每列对应一类,一行是各个建议框的得分,NMS算法步骤如下:
① 对2000×20维矩阵中每列按从大到小进行排序;
② 从每列最大的得分建议框开始,分别与该列后面的得分建议框进行IOU计算,若IOU>阈值,则剔除得分较小的建议框,否则认为图像中存在多个同一类物体;
③ 从每列次大的得分建议框开始,重复步骤②;
④ 重复步骤③直到遍历完该列所有建议框;
⑤ 遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制;
⑥ 最后剔除各个类别中剩余建议框得分少于该类别阈值的建议框。
Region Proposal建议框的Crop/Wrap具体做法
R-CNN论文中采用的是各向异性缩放,padding=16的精度最高。作者使用了最简单的一种变换,即无论候选区域是什么尺寸,先在每个建议框周围context(图像中context指RoI周边像素)加上16个像素值为建议框像素平均值的边框,再直接变形为227×227的大小。
(1)各向异性缩放(非等比缩放)
这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到CNN输入的大小227*227;有比例上的形变扭曲。
(2)各向同性缩放
因为图片扭曲后,会对后续CNN的训练精度有影响,于是作者也测试了“各向同性缩放”方案。这个有两种办法。
① 直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;
② 先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值);
回归器是线性的,输入为Alexnet pool5的输出。Bounding-
box回归认为候选区域和Ground-tTruth之间是线性关系(因为在最后从SVM内确定出来的区域比较接近Ground-Truth,这里近似认为可以线性关系),
训练回归器的输入为N对值,
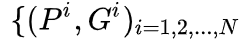 ,分别为候选区域的框坐标和真实的框坐标,下面在不必要时省略i。这里选用的Proposal必须和Ground Truth的IOU>0.6才算是正样本。Bounding-box对以及输入特征如下图9所示:
,分别为候选区域的框坐标和真实的框坐标,下面在不必要时省略i。这里选用的Proposal必须和Ground Truth的IOU>0.6才算是正样本。Bounding-box对以及输入特征如下图9所示:

从候选框P到预测框
 的基本思路如下:
的基本思路如下:
因为我们在分类之后得到候选框P
 ,其中
,其中
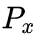 和
和
 为候选框的中心点,
为候选框的中心点,
 为候选框的宽高,下面介绍中所有框的定位都用这种定义,即x和y表示中心点坐标,w和h表示框的宽高。我们知道了候选框的表示,那么只要估计出候选框与真实框的平移量和尺度缩放比例,就可以得到我们的估计框了。
为候选框的宽高,下面介绍中所有框的定位都用这种定义,即x和y表示中心点坐标,w和h表示框的宽高。我们知道了候选框的表示,那么只要估计出候选框与真实框的平移量和尺度缩放比例,就可以得到我们的估计框了。
回归模型的训练阶段表示为图10所示:

根据上述的损失函数模型,求解出最优解权重W,权重乘以pool5的特征得到平移参数和缩放参数。
在边界回归的测试阶段:
测试阶段权重参数已经训练出来了,
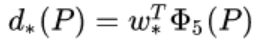 上式中
上式中
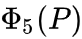 为Alexnet pool5输出的特征,所以可以求出
为Alexnet pool5输出的特征,所以可以求出
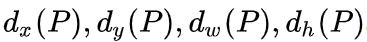 这四个变换。然后,利用下图11的公式求出预测出来包含物体的边界框。
这四个变换。然后,利用下图11的公式求出预测出来包含物体的边界框。

R-CNN存在以下几个问题:
-
训练分多步骤(先在分类数据集上预训练,再进行fine-tune训练,然后再针对每个类别都训练一个线性SVM分类器,最后再用regressors对bounding box进行回归,并且bounding box还需要通过selective search生成)
-
时间和空间开销大(在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间开销较大)
-
测试比较慢(每张图片的每个region proposal都要做卷积,重复操作太多) 在Fast RCNN之前提出过SPPnet来解决R-CNN中重复卷积问题,但SPPnet仍然存在与R-CNN类似的缺陷:
-
训练分多步骤(需要SVM分类器,额外的regressors)
-
空间开销大
