大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的特点就是:大量、高速、数据的多样化、低价值密度等。
其实对于java开发人员来说,遇到的最多大数据问题就是业务系统中对庞大的数据量的处理,这篇文章主要是介绍了解大数据和大数据的解决方案。
一、hadoop是什么

hadoop就是一个大数据的解决方案,它主要解决:海量数据的存储和海量数据分析计算的问题,简单的说就是大数据量的存和算问题。
hadoop的优点:
1.高可靠性
hadoop会对一份数据会存储多个副本,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理,
2.高扩展性
Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3.高效性
Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4.高容错性
Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
二、hadoop的核心架构
hadoop的核心架构共分为三部分:负责存储数据的HDFS、计算数据的MapReduce、资源调度的YARN
1.HDFS
HDFS是hadoop中负责数据存储的模块,它就像一个传统的分级文件系统,但是它的存储单位是文件块。它的主要构成有三部分:
(1)DataNode:为HDFS提供存储模块,简单的来说就是存储数据的地方,简称DN。
(2)NameNode:文件的索引,也是存储元数据的地方,简称NN。
(3)Secondary NameNode:NN的辅助工具,用于辅助NN备份数据,简称2NN。
2.MapReduce
MapReduce是hado中负责计算数据的模块,它是一个应用程序,:一个 Map 函数、一个 Reduce 函数和一个 main 函数。
Map函数用于将数据的映射;
Reduce函数用于对数据的合并计算;
main 函数将作业控制和文件输入/输出结合起来。
3.YARN
YARN是Hadoop2.0版本引入的,,YARN 负责将系统资源分配给在 Hadoop 集群中运行的各种应用程序,并调度要在不同集群节点上执行的任务。
YARN中也有三个部分:
(1)Resource Manager :是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等,简称RM
它的作用主要有:
处理客户端请求;
监控NodeManager;
启动或监控ApplicationMaster;
资源的分配与调度。
(2)Node Manager 是Slave上一个独立运行的进程,负责上报节点的状态,简称NM
它的作用主要有:
管理单个节点上的资源;
处理来在Resource Manager的命令;
处理来自ApplicationMaster的命令
(3)ApplicationMaster 相当于这个Application的监护人和管理者,简称 AM
它的作用主要有:
负责一个任务的跟进;
数据的切分;
为应用程序申请资源并分配给内部的任务;
任务的监控;
(4)container
container是YARN中的资源抽象,它封装了某个节点上的多资源,如内存、CPU和所有的任务容器
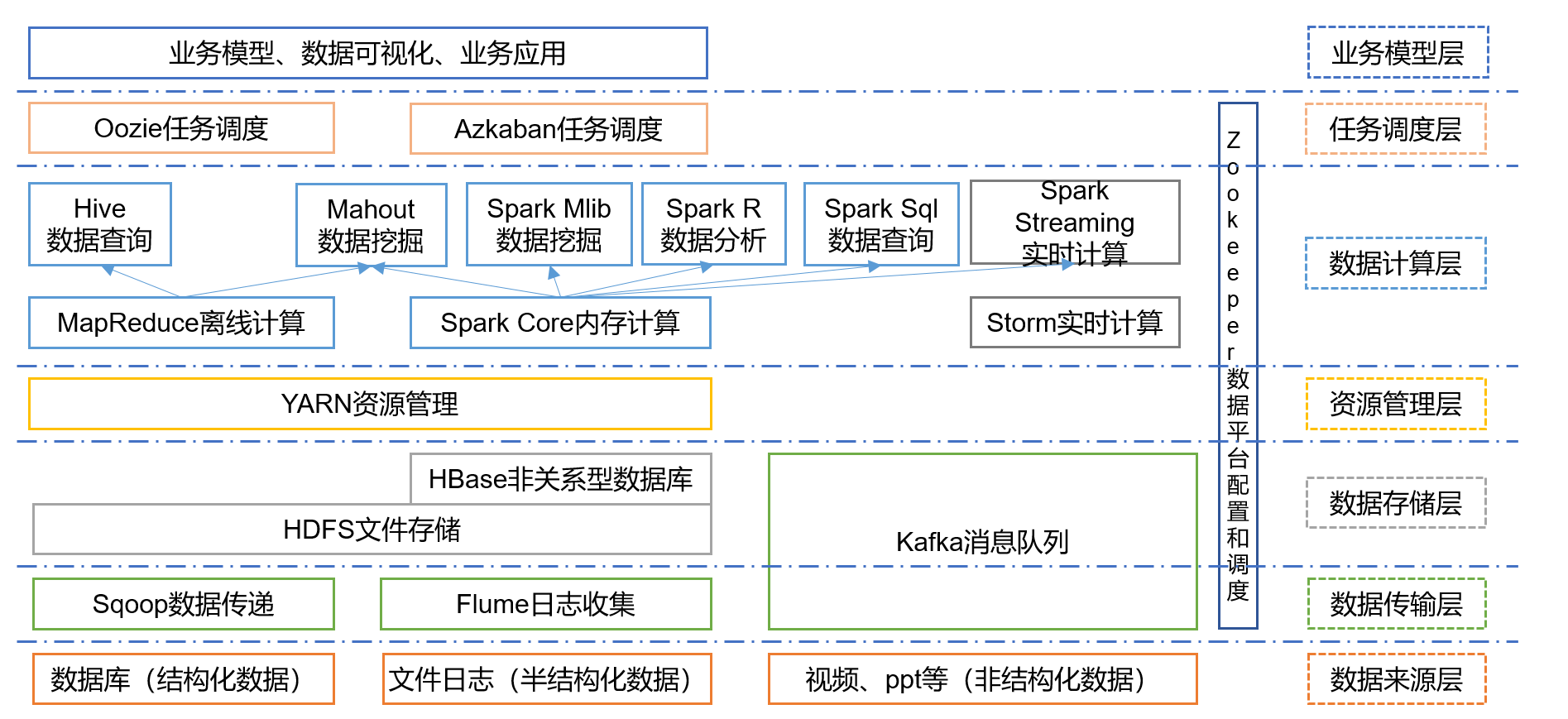
最后为大家介绍一下,大数据技术的生态体系: