模型评估
评估指标的局限性
question:准确率的局限性?
answer:准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比 如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确 率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
question:精确率与召回率的权衡?
answer:精确率是指分类 正确的正样本个数占分类器判定为正样本的样本个数的比例。召回率是指分类正 确的正样本个数占真正的正样本个数的比例。在排序问题中,通常没有一个确定的阈值把得到的结果直接判定为正样本或 负样本,而是采用Top N返回结果的Precision值和Recall值来衡量排序模型的性 能,即认为模型返回的Top N的结果就是模型判定的正样本,然后计算前N个位置 上的准确率Precision@N和前N个位置上的召回率Recall@N。 Precision值和Recall值是既矛盾又统一的两个指标,为了提高Precision值,分 类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保 守而漏掉很多“没有把握”的正样本,导致Recall值降低。
知识点:P-R曲线绘制方法:

P-R曲线的横轴是召回率,纵轴是精确率。对于一个排序模型来说,其P-R曲 线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本, 小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。整条P-R 曲线是通过将阈值从高到低移动而生成的。图2.1是P-R曲线样例图,其中实线代表 模型A的P-R曲线,虚线代表模型B的P-R曲线。原点附近代表当阈值最大时模型的 精确率和召回率。
当召回率接近于0时,模型A的精确率为0.9,模型B的精确率是1, 这说明模型B得分前几位的样本全部是真正的正样本,而模型A即使得分最高的几 个样本也存在预测错误的情况。并且,随着召回率的增加,精确率整体呈下降趋 势。但是,当召回率为1时,模型A的精确率反而超过了模型B。这充分说明,只用 某个点对应的精确率和召回率是不能全面地衡量模型的性能,只有通过P-R曲线的 整体表现,才能够对模型进行更为全面的评估。
question:平方根误差的“意外”?如何解决?
answer:一般情况下,RMSE能够很好地反映回归模型预测值与真实值的偏离程度。但 在实际问题中,如果存在个别偏离程度非常大的离群点(Outlier)时,即使离群点数量非常少,也会让RMSE指标变得很差。
第一,如果我们认定这些离群点是“噪声点”的话,就需要在数据预处理的阶段把这些噪声点过滤掉。第二,如果不认为这些离群点是“噪声点”的话,就需要进一步提高模型的 预测能力,将离群点产生的机制建模进去。第三,可以找一个更合适的指标来评估该模型。关于评估指标,其实是存在比RMSE的鲁棒性更好的指标,比如平均绝对百分比误差(Mean Absolute Percent Error,MAPE),它定义为
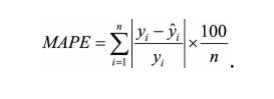
相比RMSE,MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来 的绝对误差的影响。
补充:平方根差公式(rmse) :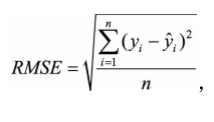
ROC曲线
question:什么是ROC曲线?
answer:ROC曲线是Receiver Operating Characteristic Curve的简称,中文名为“受试者工 作特征曲线”。ROC曲线的横坐标为假阳性率(False Positive Rate,FPR);纵坐标为真阳性 率(True Positive Rate,TPR)。FPR和TPR的计算方法分别为:

P是真实的正样本的数量,N是真实的负样本的数量,TP是P个正样本中 被分类器预测为正样本的个数,FP是N个负样本中被分类器预测为正样本的个数。
举个例子:假设有10位疑似癌症患者,其中有3位很不幸确实患了癌症(P=3), 另外7位不是癌症患者(N=7)。医院对这10位疑似患者做了诊断,诊断出3位癌症 患者,其中有2位确实是真正的患者(TP=2)。那么真阳性率TPR=TP/P=2/3。对 于7位非癌症患者来说,有一位很不幸被误诊为癌症患者(FP=1),那么假阳性率 FPR=FP/N=1/7。对于“该医院”这个分类器来说,这组分类结果就对应ROC曲线上 的一个点(1/7,2/3)。
question:如何绘制ROC曲线?
answer:ROC曲线是通过不断移动分类器的“截断点”来生成曲线上的一组关键点的。
补充:AUC指的是ROC曲线下的面积大小,该值能够量化地反映基于 ROC曲线衡量出的模型性能。计算AUC值只需要沿着ROC横轴做积分就可以了。 由于ROC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的 概率反转成1−p就可以得到一个更好的分类器),所以AUC的取值一般在0.5~1之 间。AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。