Hadoop目录结构及单机模式
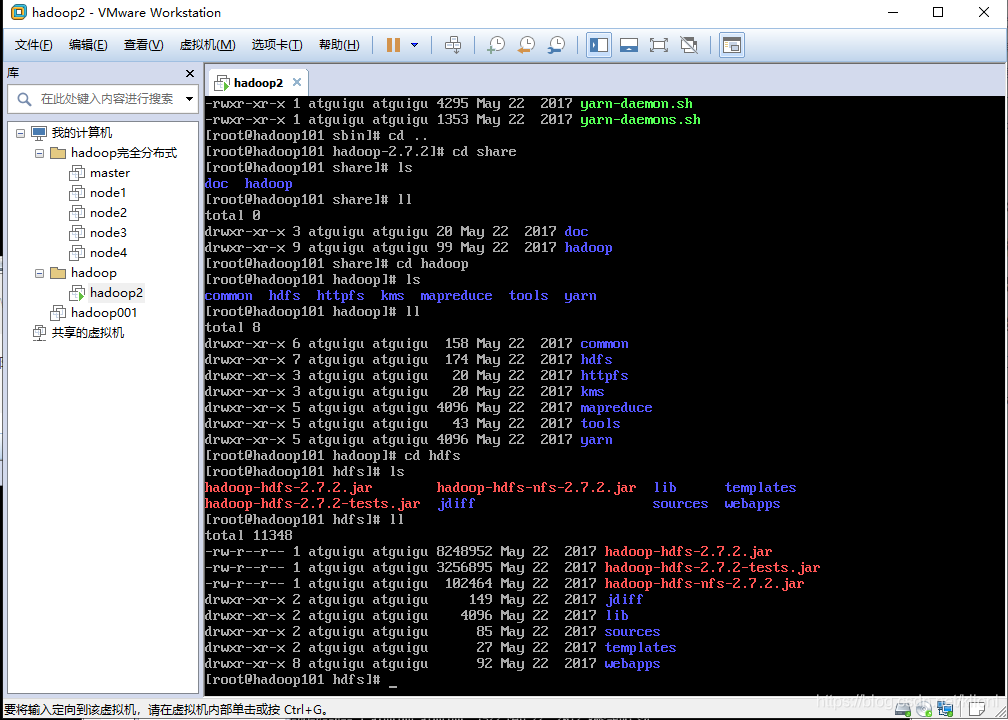
一. Hadoop目录结构

1 bin: 管理命令,一些系统的服务
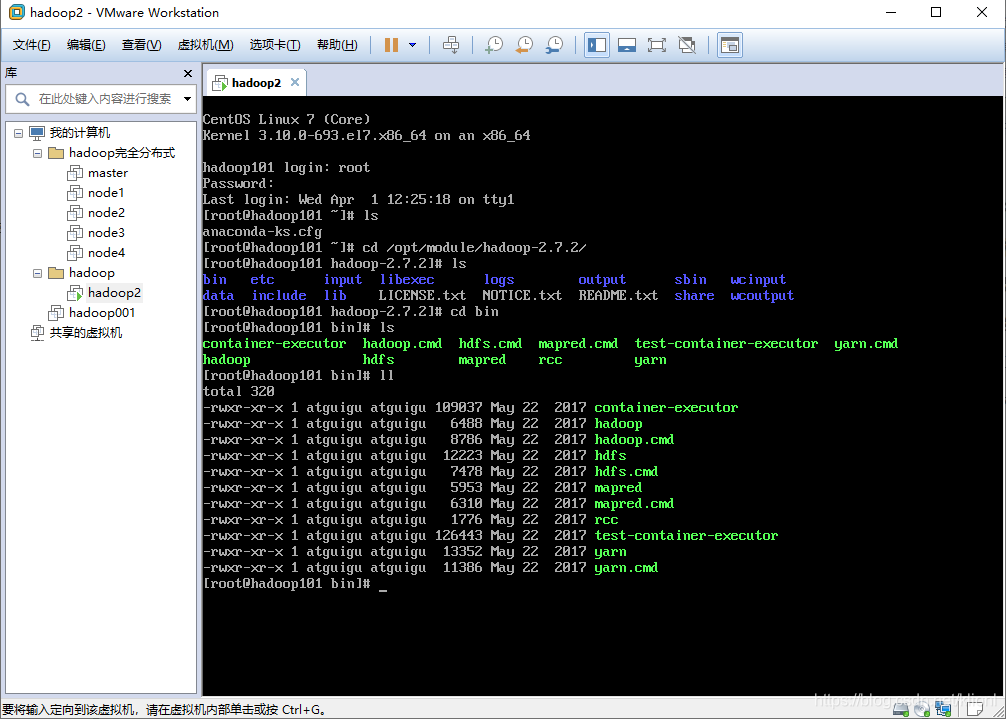
2 etc: 存放配置文件,如core-site.xml,hdfs-site.xml,mapred-site.xml等重要配置文件,后续的伪分布式和完全分布式的配置都要对这些配置文件进行一定的更改
3 include: 存放头文件
4 lib: 本地库
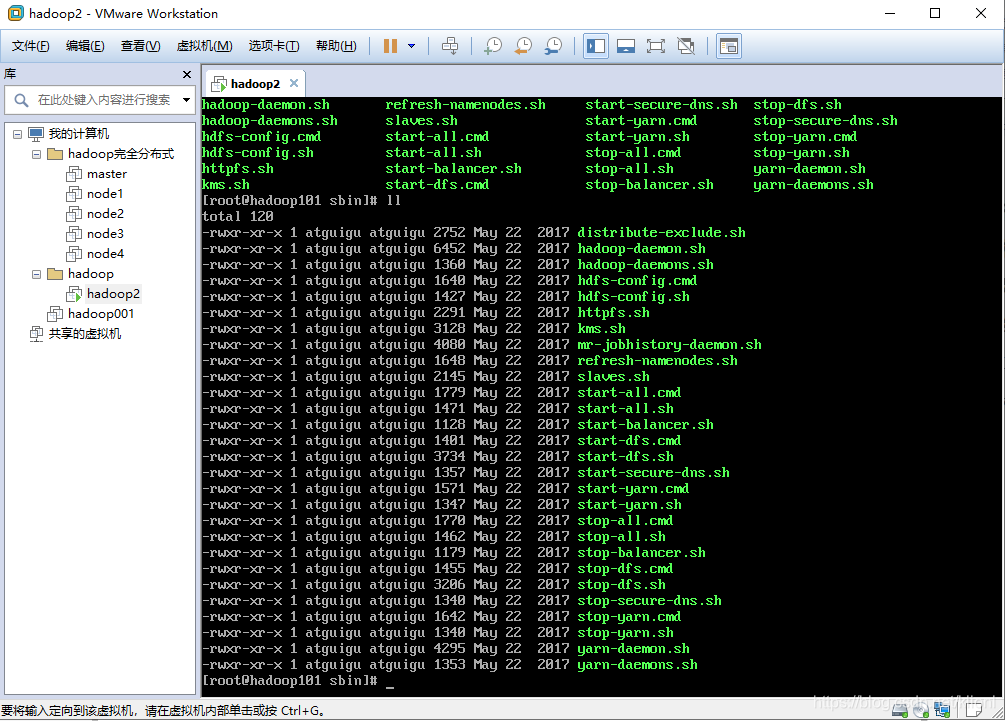
5 sbin: 存放大量hadoop命令,启动停止集群的命令,如start-dfs.sh,stop-dfs.sh是启动和关闭hdfs的命令,用来开启和关闭namenode和datanode,start-yarn.sh和stop-yarn.sh是启动关闭yarn的命令,用来开启和关闭NodeManager和ResourceManager,这四个命令是后续用到比较多的
6 share: 存放大量的说明文档和开发案例,是各个模块编译后的Jar包所在目录。后面单机案例都是用的share里面的开发案例,比如grep和wordcount等
二.Hadoop三种模式
1 单机模式/本地模式: 不需要更改配置文件,不需要启用单独进程,直接可以运行,测试和开发时使用。
2 伪分布式模式:需要配置相关文件,将多台机器的任务放到一台机器运行,模拟一个小规模的集群,但又因为只是一台节点,所以称为伪分布式
3 完全分布式模式:实际生产中真正用到的模式,多台机器共同运行
三.单机模式
1. Grep案例
grep–提供一些文本文件,grep可以从中找到想要匹配的文本
1 创建input目录并拷贝etc(配置文件)目录下后缀为.xml类型的所有文件到input目录下
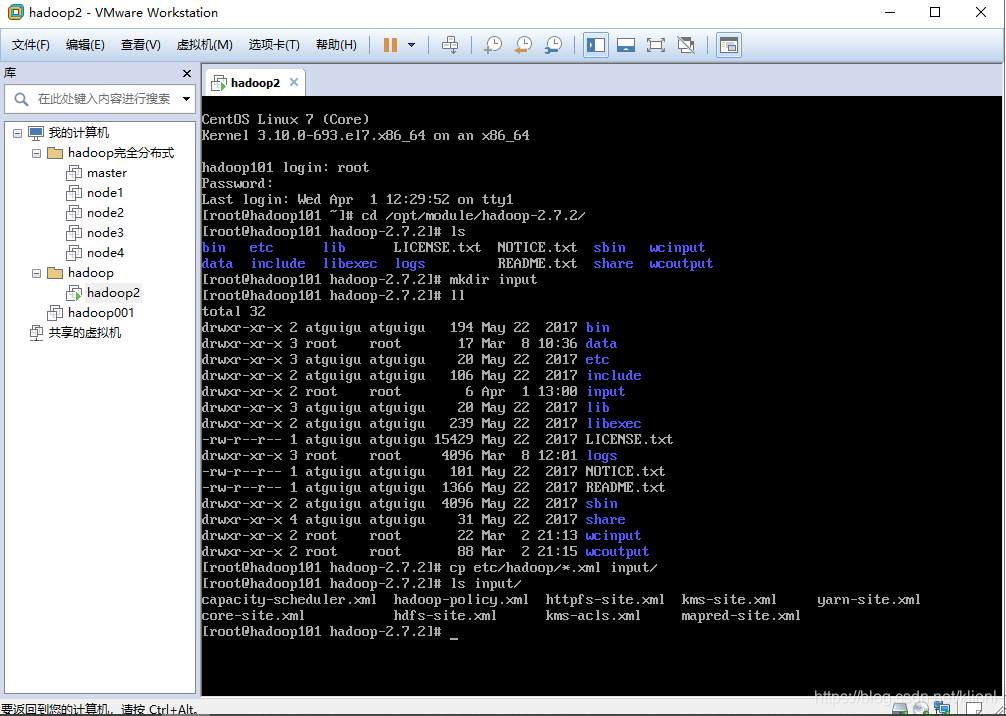
2 执行命令 这里的输出目录output事先不能被创建,否则会报错 将input下开头为dfs的文件拷贝到输出目录下,这里的匹配机制用的是正则表达式

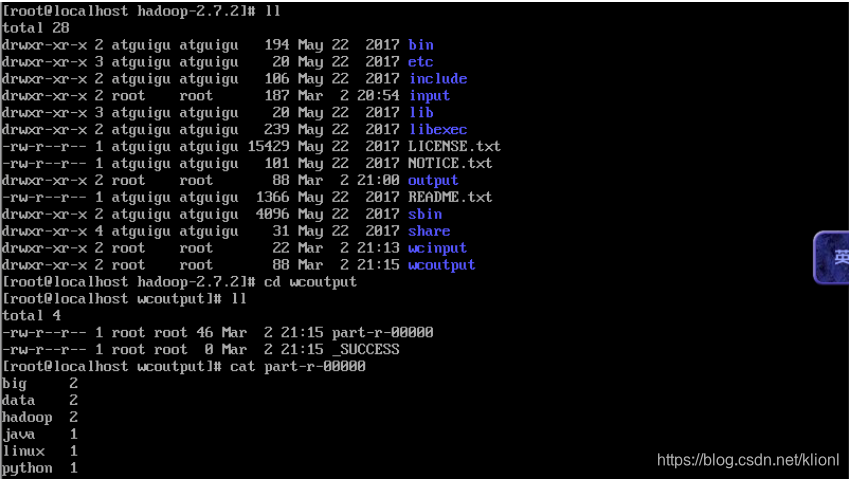
 3 查看符合正则表达式的统计结果
3 查看符合正则表达式的统计结果

2.WordCount案例
wordcount–统计单词出现次数
1 准备一个待统计的文件

2 执行命令,这里的output输出目录也不能被创建,否则会报错


3 查看结果