好接下来!我们来学习本地模式。
上一篇是【Hadoop集群搭建】Hadoop运行环境配置——虚拟机准备(CentOS 8)
首先来了解一下Hadoop的目录结构。
马赛克涂掉的是我之后产生的文件,剩下的是一个原本的干干净净的目录。
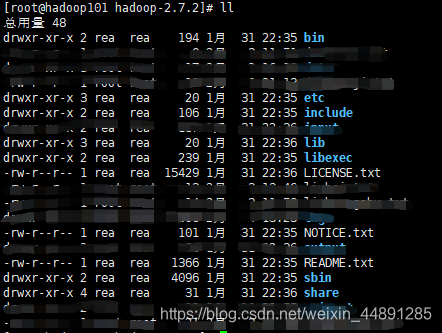
介绍几个重要的常用的如下:

Hadoop的运行模式分为 本地模式 / 伪分布式 / 完全分布式 三种,下面我们来讲第一种——最简单的也是最基础的
本地模式(Local/Standalone Operation)
顾名思义,本地模式是一种只运行在本机上的模式,“在默认情况下,Hadoop被配置用于运行非分布式模式,作为一个单独的Java进程,这种模式对于debug来说是有帮助的”(翻译自Hadoop官方文档,我们要学会阅读它们)
本地模式并不需要部署什么服务,我们从两个案例来了解一下它,这次我在克隆的hadoop101上进行演示。

1.官方Grep案例
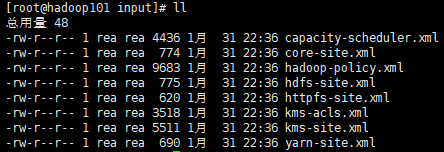
首先来理解一下官方文档上给出的这个案例,在**/opt/module/hadoop-2.7.2**目录下:
mkdir input #创建input文件夹
cp etc/hadoop/*.xml input #把 etc/hadoop下所有的xml文件拷贝到input文件夹中
执行当前bin目录下的hadoop命令,执行一个jar包+执行的jar包路径+其中名为grep案例+输入文件路径+输出文件路径(必须未创建)+正则表达式。这个案例就是在统计input中符合这个正则表达式的所有单词个数。
[a-z]表示字符范围,匹配指定范围内的任何字符;后面的“.” 表示匹配除“\r\n”之外的任何单个字符;“+”表示一次或多次匹配前面的字符或子表达式; 这个正则表达式就是表示匹配以"dfs"开头,后面是任意 a 到 z 小写字母,并且这个a到z可有任意多个的单词。
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input/ output 'dfs[a-z.]+'
cat output/* #查看结果
一共匹配到1个结果,叫 dfsadmin 的词。

2.官方WordCount案例
很经典的案例,案例本身是统计文本中每个单词的个数。所有涉及到统计汇总的案例都与其原理有渊源。
同样在**/opt/module/hadoop-2.7.2**目录下:
mkdir wcinput #创建输入文件夹
cd wcinput
touch wc.input #在wcinput文件夹下创建一个输入文件
vim wc.input #编辑wc.input文件并输入以下内容(自定义)
接下来回到**/opt/module/hadoop-2.7.2**目录并执行程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput #前面也可以不加bin,是因为配置了环境变量,由此感受环境变量的作用
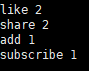
cat wcoutput/*
统计的很到位,subscribe(关注),like(点赞),add(收藏),share(分享),嗯~ o( ̄▽ ̄)o你懂我意思吧。
**
至此我们的Hadoop运行模式之本地模式篇就完成啦!
希望能帮到大家>_<
在下一篇我们会来了解伪分布式运行模式。
**
