在数据维度很高时,我们会从中提取出一些有用的特征,降低数据处理的维度,方便计算,这个过程也被叫做降维。
一般常用的降维方法有PCA和LDA。
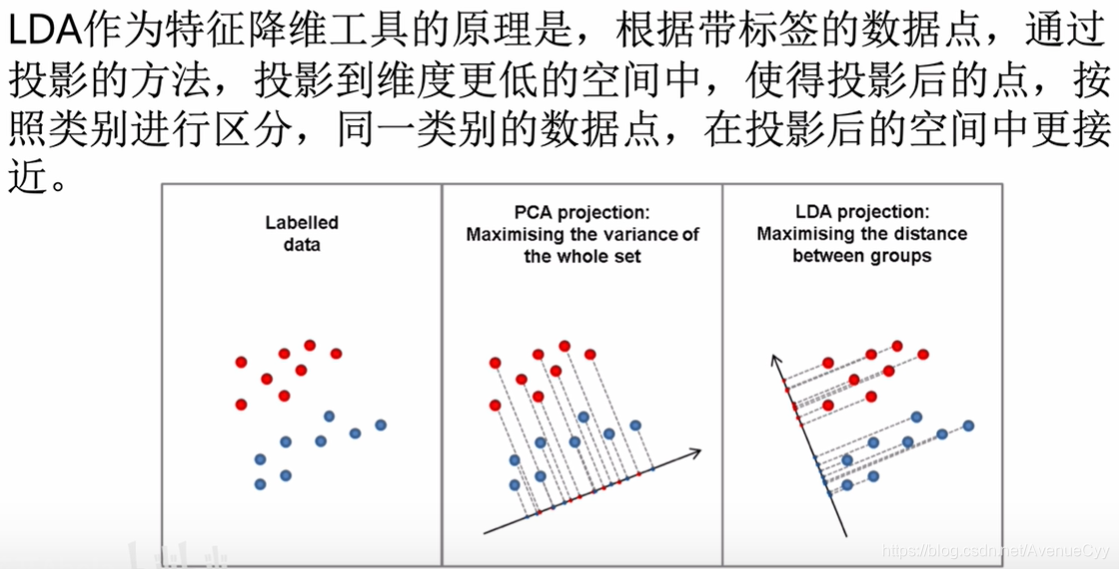
- PCA:非监督降维,降维后数据的方差尽可能的大(方差大,含有的信息量就大)
- LDA:有监督降维,降维后,组内(同一类别)方差小,组间(不同类别之间)方差大
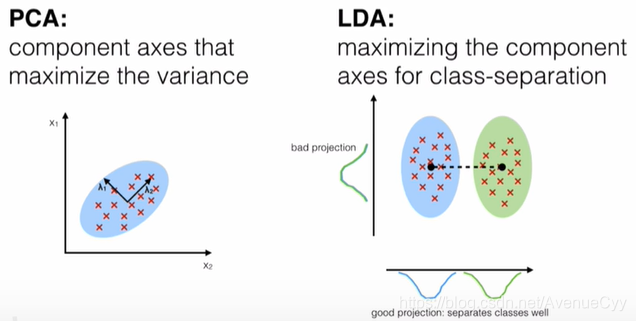
注:对原始数据进行线性变换,比如上面左图的二维数据,x1轴代表年龄,x2轴代表收入,这时候要是按照对角线进行线性变换,二维虽然降到了一维,但是无法解释这个新的一维特征的具体含义。即变换后的数据不具备可解释性。
因此,降维的操作比较适合在高维度下进行,若想要进行有解释性的特征选择,可以用随机森林的重要性或者Lasso回归,带L1正则化的逻辑回归等。
主成分分析PCA
PCA的直观理解
PCA的一般用途:
- 聚类:把复杂的多维数据转为少量数据,易于分簇
- 降维:降低高维数据,简化计算,达到数据降维,压缩,降噪(去掉不太重要的特征)的目的
PCA的作用:
- 将原有的d维数据集,转为k维数据,k<d
- 新生成的k维数据尽可能多的保留原来d维数据的信息
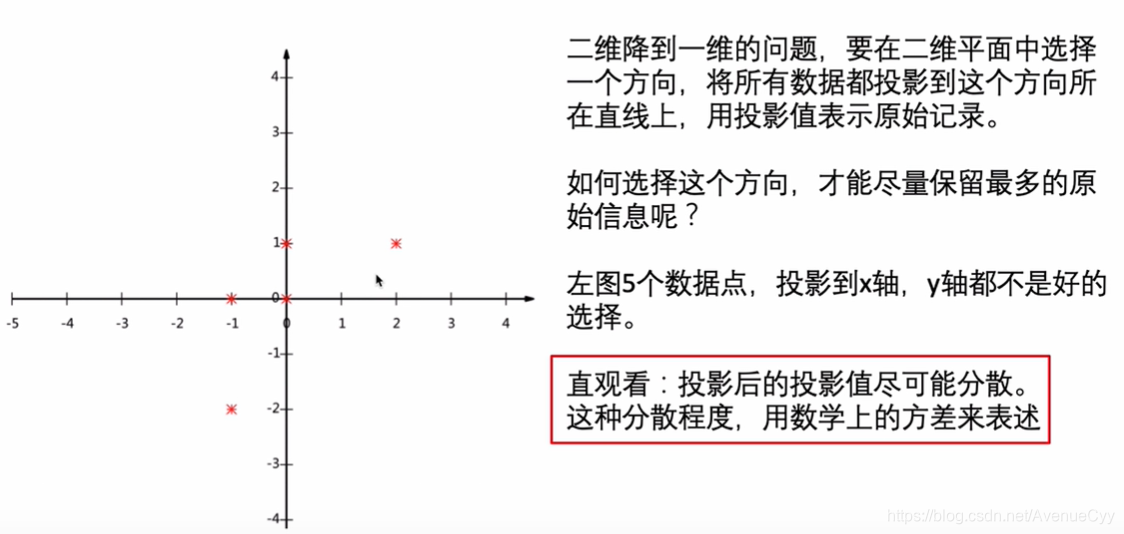
第一个图,投影到对角线上的话,保留的数据信息会多一些。
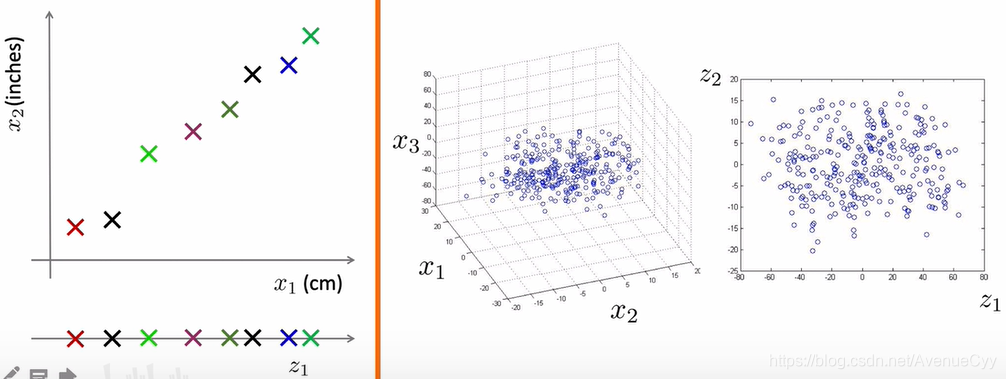
沿着对角线方向,投影后映射到该对角线上的值要尽可能的分散,这个分散程度就用方差来表示。
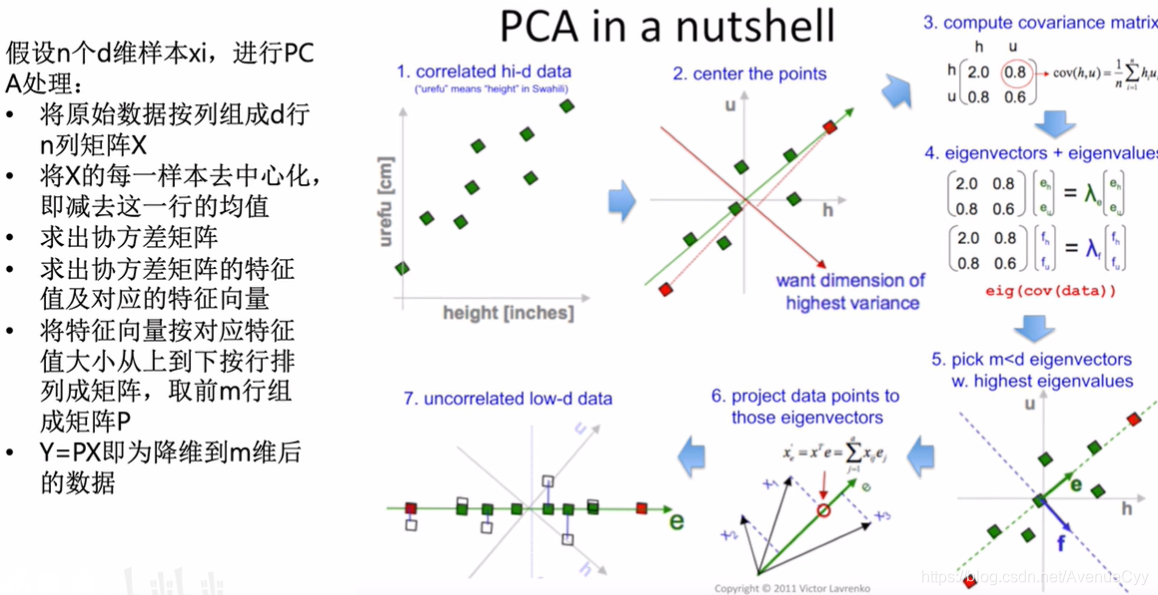
PCA的数据推导
PCA的目标函数
之前的数据均值不为0,需要进行中心化,将数据均值变为0。
协方差矩阵是用来衡量数据间的相似程度,主要是线性相关,若该值较大,说明线性相关程度越大。

通过线性变换u1,可以把原始数据投影一个方向上,在该方向上方差最大。
因为对样本做了去中心化,所以均值为0。

目的是想让投影后的方差取得最大值,得到如下优化函数,使用拉格朗日条件进行转换。。
为了方便计算,可以指定线性变换的模长为1。

λ是协方差矩阵的特征值,想要目标函数最大,也就是让λ值最大。
协方差的λ值有λ123……,对应的线性变换的方式就有u123……,彼此是对应的关系,将λ值从大到小进行排序,u也随之排序,取其前k个乘原始的数据,就得到降维后的数据Y。

PCA流程:
带核函数的PCA
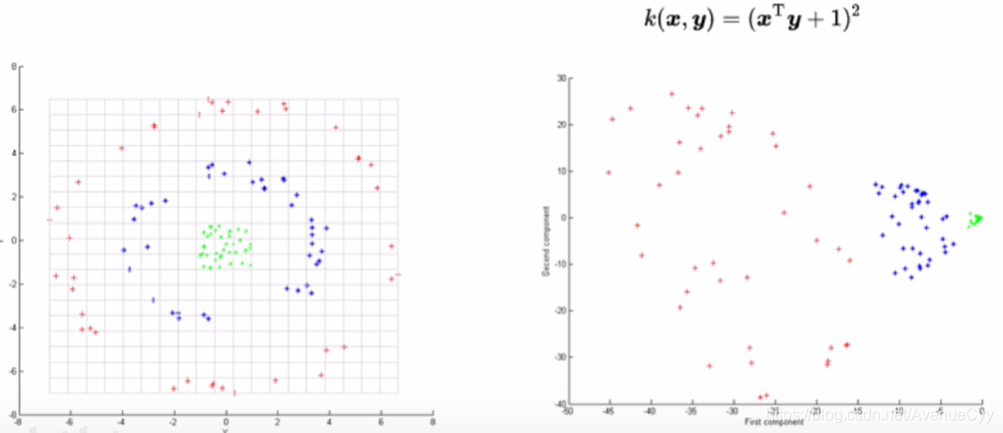
对于非线性数据,可将其映射到更高维的空间,转为线性数据,这样就可以用PCA进行处理。这里用核函数进行处理。

带核函数的PCA推导
以下是数学推导过程,具体的讲解可看PCA讲解。






计算步骤的总结:
1.选择一个核函数。
2.根据原始的数据得到正规化的K。(相当于数据向高维的映射)
3.计算特征值和特征向量
4.进行降维。

常用的核函数:高斯核,多项式核等。
利用核函数对数据进行映射,将左边的数据转为右边的形式,再进行降维。
SVD
另外还有一种降维的方法SVD,说是另外一种降维方法,但其实跟PCA相差不大,实现PCA的时候一般底层都是SVD的方法。
具体的原理可参考SVD原理,区别可参考PCA与SVD区别。这里先简单说明下PCA和SVD的区别:
- SVD不需要求解协方差矩阵,比PCA的计算速度要快。
- PCA的降维是特征的降维,使用的是SVD的右奇异矩阵。而SVD可以得到“两个方向的PCA”,一个是右奇异矩阵,用于特征(列)的降维,另一个是左奇异矩阵,用于数据(行)的降维。
线性判别分析LDA
LDA的直观理解
LDA:线性判别分析,可以做特征降维,也可以做分类方法。
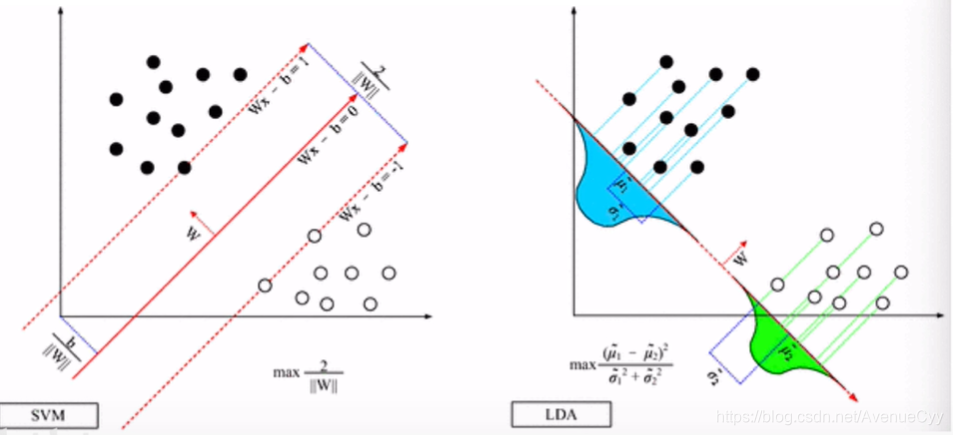
LDA降维原理:通过投影的方法,对带标签的数据投影到更低维的空间中。投影后,同一类别的点之间比较近,不同类别的比较远。
连接两个数据的中心点,在连线上进行降维。
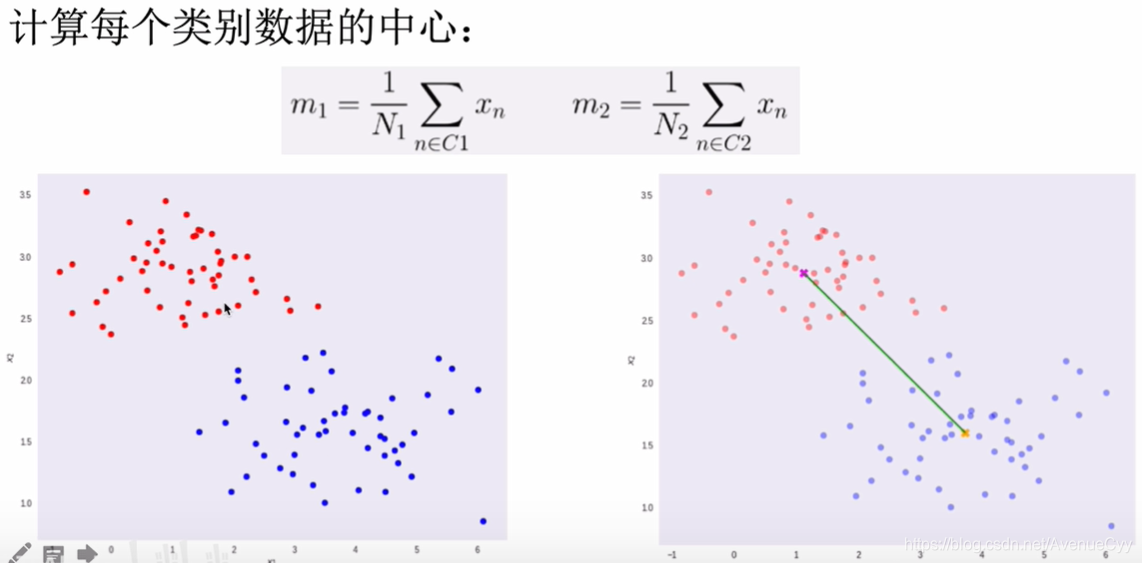
但是这样处理后,数据之间有交叉,效果不好。
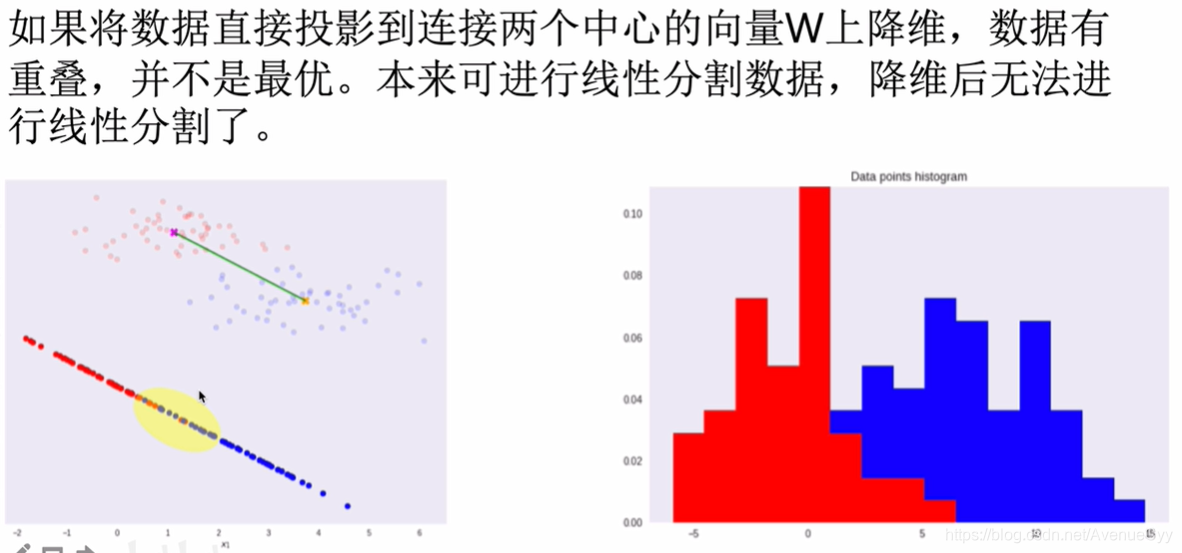
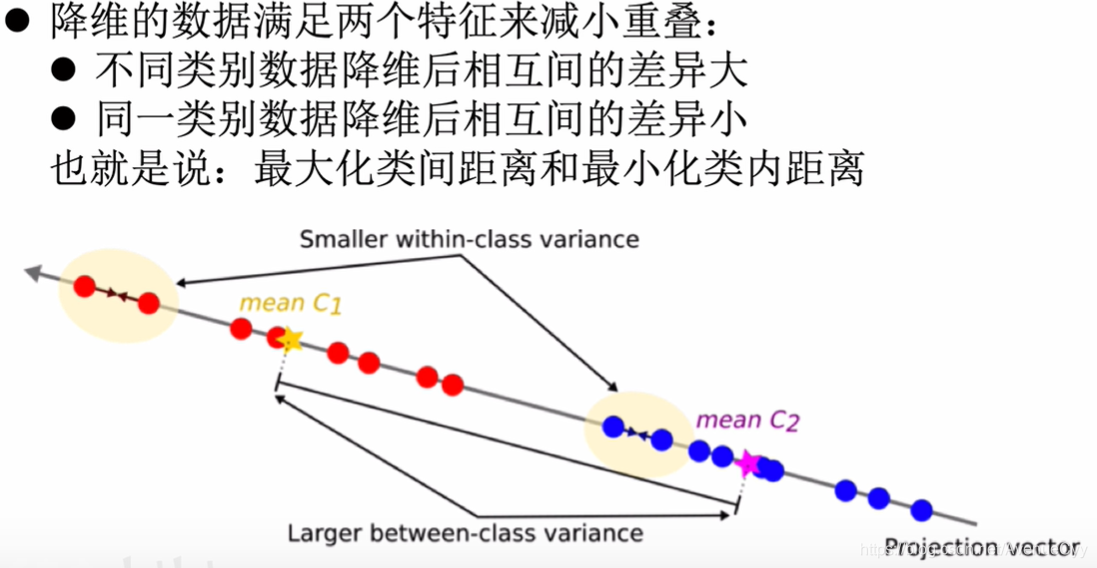
为了降低数据之间的重叠,可以让不同类别数据的中心点之间的距离最大化,同一类别的方差要小一些。
LDA的数据推导
求出投影后各类别样本间的距离(用均值绝对值的差表示)和各样本的方差。要让D最大,V最小。

构建优化目标,要让J最大化。定义类内散度矩阵和类间散度矩阵。

将Sw和Sb带入公式。对w求导,w是线性变换(向量)。
将求导后得到的结果w回带之前的公式,将J的最大值用λ进行表示。
最后得到λ=Sw的逆Sb,让Sw的逆Sb的特征值最大,即求得λ最大。

LDA的降维流程:

PCA和LDA的比较
相同点:
从求解的过程看,PCA和LDA最后都是求某一个矩阵的特征值,投影矩阵即为该特征值对应的特征向量。
不同点:
- PCA为无监督降维,LDA为有监督降维。
- PCA投影后的数据方差尽可能的大,因为假设其方差越大,所包含的信息就越多;LDA投影后不同类别组间方差大,相同类别组内方差小。LDA能结合标签的信息,使得投影后的维度具有判别性(分类),不同类别的数据尽可能地分开。
- 对于有标签的数据就使用LDA,而对于无监督的任务,则使用PCA。
参考资料
https://www.bilibili.com/video/BV1ME411T7tV?p=10
