- selector (scrapy 选择器)
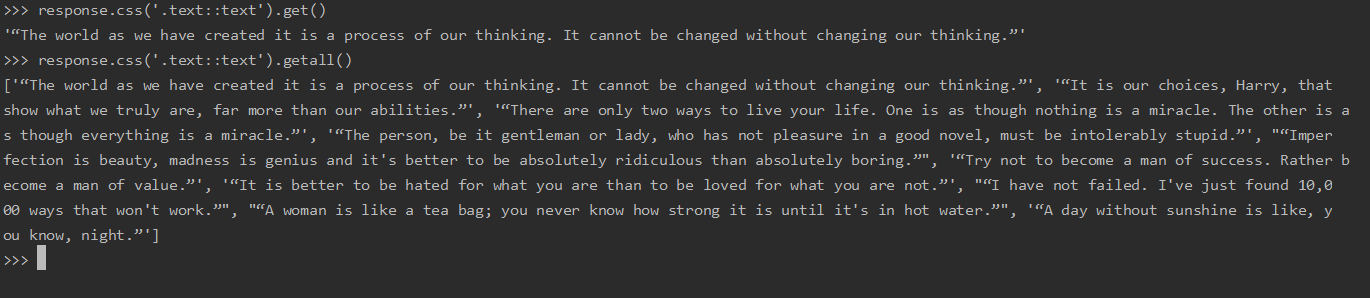
.get() 是返回匹配的第一项
.getall()返回包含所有结果的列表
非标准的伪元素:
::text 文本节点
::attr(name) 选择属性值 ,其中name是想要值得属性得名称


实例:

response.xpath('//title/text()').get()

response.xpath('//div[@id="images"]/a/text()').get()
或者
response.xpath('//div[@id="images"]').css('a::text').get() //获取内容

response.xpath('//div[@id="images"]').css('img::attr(src)').get() //获取属性

假设只想要 My image 可以再添加正则

用 re_first 获得第一个

- spider
可再settings.py里面设置请求头,这样就可以带 UA或者cookie访问

start_requests(self)默认是用GET方法请求网站,如果想改为POST请求,需要在spider处设置

callback 默认回调函数是 self.parse
- Item与Pipeline
当Item被spider抓取后,它被发送到Item管道(Item pipeline),它通过顺序执行的几个组件来处理Item。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
注意 pipeLine中的逻辑 正确则返回Item 如果错误返回的是 DropItem
process_item(self, item, spider)
每个 Item Pipeline 组件都会调用此方法。该方法必须:返回一个带数据的dict,或是返回一个
Item(或任何后代类)对象,或是返回一个 Twisted Deferred 或者抛出DropItem异常。被丢弃的item不再被之后的其他pipeline组件处理。参数:
另外,它们还可以实现以下方法:
当spider被开启时,这个方法被调用。
参数:
- spider (
Spider对象) – 被开启的spider当spider被关闭时,这个方法被调用
参数:
- spider (
Spider对象) – 被关闭的spider如果存在,则调用此类方法以从
Crawler创建pipeline实例。它必须返回一个新的pipeline实例。 Crawler对象提供对所有Scrapy核心组件(如settings 和 signals)的访问;它是pipeline访问它们并将其功能挂钩到Scrapy中的一种方法。参数:
- crawler(
Crawler对象) - 使用此pipeline的crawler
实例很多,在官方文档看吧!
今天没有实例,另外 middlewears.py文件好像是和代理有关,后面遇到再学吧,下一天弄两例实例,实例学起来是最快的。