- 这里我们以索引库index为例子,依然是使用postman发送json数据来完成

1、增
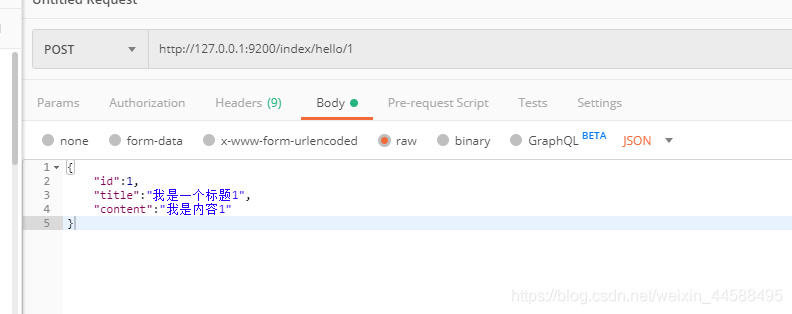
- 1是指文档的的_id,并不是下面的id,一般_id与id相同
{
"id":1,
"title":"我是一个标题1",
"content":"我是内容1"
}
{
"_index": "index",
"_type": "1",
"_id": "AW6dhLRtj92VZTE9RyoB",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}

2、删

{
"found": true,
"_index": "index",
"_type": "1",
"_id": "AW6dhLRtj92VZTE9RyoB",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
3、改
- 这里的原理是:先删除再添加,这里直接可以执行添加操作,就会先删除再添加
- 修改之前
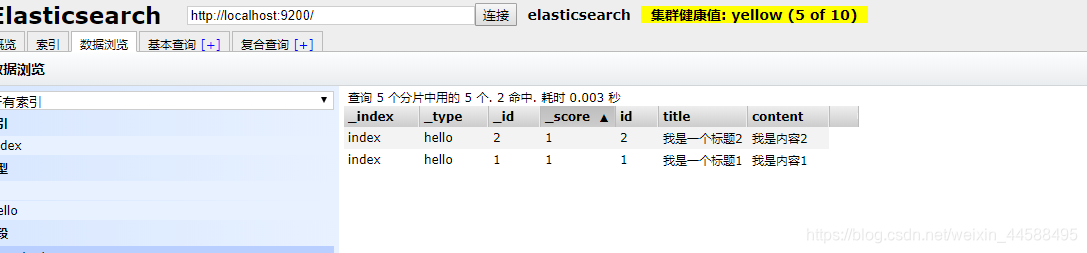

- 返回json
{
"_index": "index",
"_type": "hello",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
- 查看数据
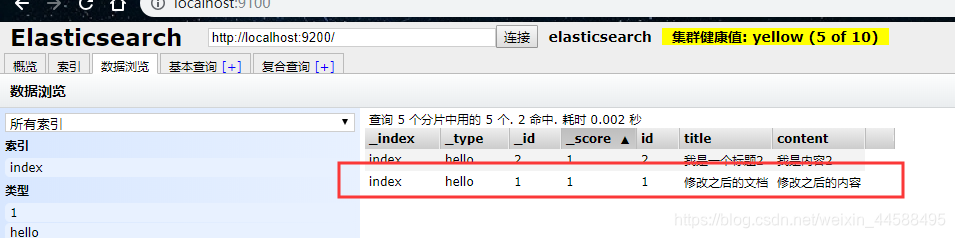
4、根据id查询
{
"_index": "index",
"_type": "hello",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"id": 1,
"title": "修改之后的文档",
"content": "修改之后的内容"
}
}
5、根据关键词查询
- 这里是post请求
{
"query":{
"term":{
"title":"修"
}
}
}
- 其中query和term都是关键字.,这里的查询只能输入一个汉字
- 返回json
{
"took": 127,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.28582606,
"hits": [
{
"_index": "index",
"_type": "hello",
"_id": "1",
"_score": 0.28582606,
"_source": {
"id": 1,
"title": "修改之后的文档",
"content": "修改之后的内容"
}
},
{
"_index": "index",
"_type": "hello",
"_id": "3",
"_score": 0.25811607,
"_source": {
"id": 1,
"title": "修改之后的文档as12d",
"content": "修改之后的内12容"
}
}
]
}
}
6、使用queryString查询
- 使用这个会进行分词,跟上面分词查询是一样的。

- 返回的json
{
"took": 125,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.5716521,
"hits": [
{
"_index": "index",
"_type": "hello",
"_id": "1",
"_score": 0.5716521,
"_source": {
"id": 1,
"title": "修改之后的文档",
"content": "修改之后的内容"
}
},
{
"_index": "index",
"_type": "hello",
"_id": "3",
"_score": 0.51623213,
"_source": {
"id": 1,
"title": "修改之后的文档as12d",
"content": "修改之后的内12容"
}
}
]
}
}
7、扩展
- 查看分词器中的分词效果
- 输入http://127.0.0.1:9200/_analyze?analyzer=standard&text=
- 其中text后面加英文或者中文
对于英文的支持
{
"tokens": [
{
"token": "i",
"start_offset": 0,
"end_offset": 1,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "am",
"start_offset": 2,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 5,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "hbu",
"start_offset": 7,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "student",
"start_offset": 11,
"end_offset": 18,
"type": "<ALPHANUM>",
"position": 4
}
]
}
对于中文的支持
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "河",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "北",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "大",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "学",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "青",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "年",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 7
}
]
}
- 实际上这种对于中文是非常不好的,因此在实际开发中我们不使用标准的分词器
