数据分析的基本过程一般分为以下几个部分:
- 提出问题
- 获取并理解数据
- 数据清洗
- 构建模型
- 数据可视化
1.提出问题
在数据分析之前,我们先要明确分析目标,可以帮助我们更高效的选取数据,进行分析研究。
本次的分析目标是从销售数据中分析出以下业务指标:
1)月均消费次数
2)月均消费金额
3)客单价
4)消费趋势
有了分析目标,我们再来关注一下数据情况。
2.获取并理解数据
这里的数据集来源于微信公众号【数据分析1480】
我们先导入数据集,看看数据基本情况
1)导入数据处理相关库
import pandas as pd
2)导入数据,并理解数据
df=pd.read_excel('某医院2018年销售数据.xlsx')
df.head(5)

读取时默认将第一行作为标题行,打印前5行观察数据,发现数据表的基本信息包括"购药时间",“社保卡号”,“商品编码”,“商品名称”,“销售数量”,“应收金额”,“实收金额”。
#检查数据基本情况(缺失值、数据类型、行列情况等)
df.info()

行列:6578行x7列
缺失值:明显发现各项均小于6578,都存在缺失值
数据类型:各列数据类型object、float64…
#进行描述性统计
df.describe()

这里社保卡号和商品编号无实际意义,不考虑。
只看后三列,结果中最小值出现负数,需要关注
3.数据清洗
从上面的数据来看,我们明显发现存在缺失值,异常值,并不能马上就开始进行数据分析。这些数据都会使我们的分析结果产生偏差。
在分析之前,需要进行子集选择、缺失数据补充、异常值处理、数据类型转换等多个步骤。这些都属于数据清理的范畴。 在数据分析中,通常有多达60%的时间是花在数据清洗中的。通常的清洗步骤有以下几步:
• 选择子集
• 列名重命名
• 缺失数据处理
• 数据类型转换
• 数据排序
• 异常值处理
这些步骤有些不是一步就能完成的,可能需要重复操作。
现在开始对药店销售数据进行数据清洗。
1)选择子集
药店销售数据中,项目较少,选择子集可以忽略,我们从列名重命名开始。
2)列名重命名
销售数据集,购药时间显示为销售时间更为合理,我们先把这个项目名称做一下变更。
nameChangeDict = {'购药时间':'销售时间'}
#参数inplace=True表示覆盖元数据集
df.rename(columns = nameChangeDict,inplace=True)
df.head(5)

3)缺失值处理
对于缺失数据,我们可以有几种处理方法:
▪ 删除
当缺失数据占总数据量的比例很小的时候,我们通常采用删除的处理方法。
▪ 合理值填充
在某些不适合删除的场合,我们有时候也会对缺失数据进行合理值填充,如平均值,中位数,相邻数据等等。
#查看缺失值
df.isnull().any()
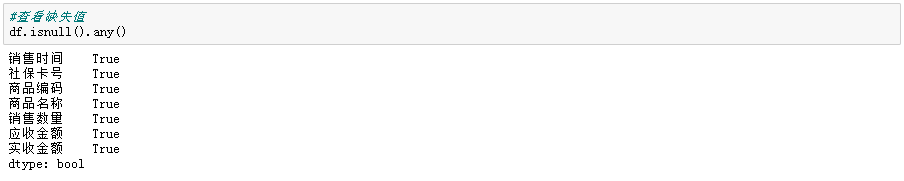
我们前面已经分析发现每列数据都有缺失值。
因为,缺失值数据占总数据量比例较小,并且销售时间和社保卡号为必须数据,且无法通过填充进去清理,所以在这里我们选择先删除社保卡号为空的数据,
查看缺失值数据:

#序号6574因为销售时间和社保卡号都缺失,所以会出现两次。
可以看到缺失值数据量仅为3条,我们对其进行删除

这里我们再次查看缺失值

发现已经不存在缺失值了,说明其他列的缺失值是由销售时间和社保卡号缺失造成。
我们重新查看一下数据集规模:

在数据删除后要及时更新一下最新的序号,不然可能会产生问题。同时打印后5行检验序号是否正确

4)数据类型转换
比如金额项目需要从字符串类型转换为数值(浮点型)类型。
这里先查看数据类型是否符合要求

可以看出,符合要求
如果需要更改数据类型,比如销售数量更改为整数int,则可以按下列代码进行更改并查看数据类型:
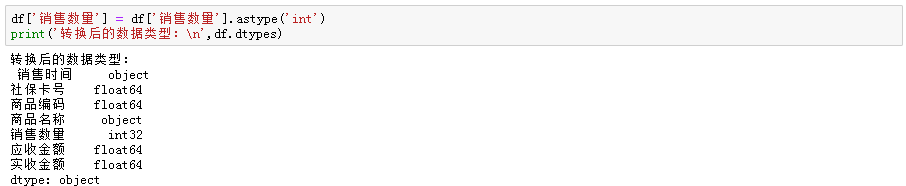
日期类型:从字符串类型转换为日期类型
这里的销售日期中包含了日期和星期,我们先提取星期建立新列。这里用一个自定义的函数dateadd来实现这个功能。
#新建星期列
def dateadd(dateSer):
dateList = []
for i in dateSer:
#例如2018-01-01 星期五,提取“星期五”
str = i.split(' ')[1]
dateList.append(str)
dateaddSer = pd.Series(dateList)
return dateaddSer
dateaddSer = dateadd(df['销售时间'])
df.insert(1, '星期',dateaddSer)

然后删去销售日期中的星期信息
#日期转换
def dateChange(dateSer):
dateList = []
for i in dateSer:
#例如2018-01-01 星期五,分割后为:2018-01-01
str = i.split(' ')[0]
dateList.append(str)
dateChangeSer = pd.Series(dateList)
return dateChangeSer
dateChangeSer = dateChange(df['销售时间'])
dateChangeSer
df['销售时间'] = dateChangeSer
df.head()

我们继把销售时间的数据类型转为日期型。

因为改变了数据类型,未来确保数据转换成有效数据,这里我们查看是否出现了空值,发现出现了空值

这里判断可能是原始日期出现了问题,在实际应用中,需要分析产生的原因以及需不需要将这样的数据进行一下必要的修正。
这里我们就简单的把数据进行删除。由于条数不太多,我们暂时将其删去,再次检查发现不存在空值了

**5)数据排序 **
这里非常重要,不排序会影响建模过程
销售记录一般是以销售时间为顺序排列的,所以我们对数据进行一下排序

6)异常值处理
通过前面df.describe()的描述指标中可以看出,存在销售数量为负的数据,这明显是不合理的,我们把这部分数据也进行删除

重新进行描述统计,发现负值不存在了

及时更新一下最新的序号,不然可能会产生问题。同时打印后5行检验序号是否正确

5.构建模型
1)业务指标1:
月均消费次数=总消费次数 / 月份数
总消费次数:同一天内,同一个人发生的所有消费算作一次消费。这里我们根据列名(销售时间,社区卡号)结合,如果这两个列值同时相同,只保留1条,将重复的数据删除
月份数:数据已经按照销售时间进行排序,只需将最后的数据与第一条数据相减就可换算出月份数
#总消费次数计算
kpdf = df.drop_duplicates(subset=['销售时间','社保卡号'])
total = kpdf.shape[0]
print('总消费次数为:',total)
#月份数计算
startDay = df.loc[0,'销售时间']
print('开始日期:',startDay)
endDay = df.loc[df.shape[0]-1,'销售时间']
print('结束日期:',endDay)
monthCount = (endDay - startDay).days//30
print('月份数:',monthCount)
#业务指标1:月均消费次数=总消费次数 / 月份数
kpi1 = total / monthCount
print('业务指标1:月均消费次数=',kpi1)

2)指标2:月均消费金额 = 总消费金额 / 月份数

3)指标3:客单价=总消费金额 / 总消费次数

4)指标4:消费趋势
#在进行操作之前,先把数据复制到另一个数据框中,防止对之前清洗后的数据框造成影响
groupDf=df
#第1步:重命名行名(index)为销售时间所在列的值
groupDf.index=groupDf['销售时间']
#第2步:分组
gb=groupDf.groupby(groupDf.index.month)
#第3步:应用函数,计算每个月的消费总额
mounthDf=gb.sum()

导入可视化库
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.serif'] = ['SimHei']
sns.set_style("darkgrid",{"font.sans-serif":['simhei', 'Arial']})
import matplotlib.pyplot as plt
%matplotlib inline
#绘制销售数量图
plt.plot(mounthDf['销售数量'],color = 'b')

