mysql索引实现原理(即innodb/myisam存储引擎原理)
innoDB与myisam底层实现原理:B+树
为什么这两种存储引擎都用B+树来实现底层数据结构?
因为B+树高度是可控的,一般就是3到5层。查询的效率高,树的高度越高,查询效率越慢。
B+树特点:只在最末端叶子节点存数据,叶子节点是以双向链表的形式相互指向的。
聚簇索引和非聚簇索引理解:
聚簇索引:索引节点上存储了整行数据。innodb的主键索引
非聚簇索引:索引节点上没有存储整行的数据。
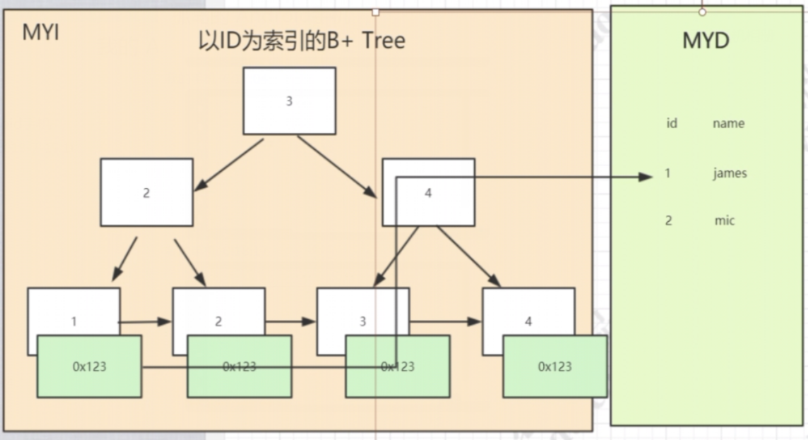
Myisam存储引擎(非聚簇索引)
这里讨论的是myisam的主键索引
创建表指定myisam后,数据库会生成3个文件:
1、user.myi 索引文件:表数据文件中任何索引的数据树
2、user.myd 数据文件:表的数据文件。(由于inndb使用聚簇索引存储数据,所以没有这个数据文件)
3、user.frm(form结构) 数据结构类型:描述表结构的文件
执行流程:select * from user where id =1
1、查看该user表的myi索引文件中有没有以id为索引的索引树
2、在id索引树上通过id值找到相应节点,从而得到节点的数据(叶子节点存的是索引值和数据地址,数据地址指向当前表myd数据文件具体的哪一行)
3、根据数据地址去myd文件里找到对应的数据返回。
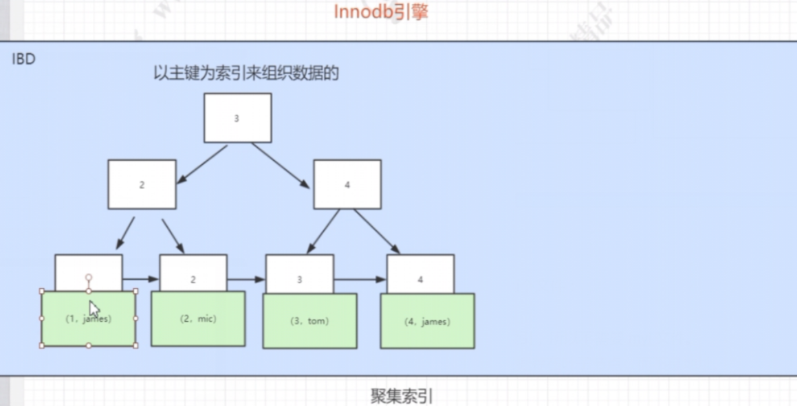
innodb存储引擎(聚簇索引)
这里讨论的是innobd的主键索引
创建user表后,指定为innodb存储引擎会生成2个文件:
1、user.ibd:索引文件
2、user.frm:数据结构类型
因为innodb存储引擎建表默认就是以主键为索引,而myisam不会默认指定主键和主键索引树;
myisam的主键索引树和普通索引树存的内容都是当列的值和数据行地址(行号)。
innodb以多块page的方式存储数据,不连续;myisam以一个连续的table存储数据,myisam索引储存的是索引列的值和数据的行号。
注:每个page区默认大小=16kb
innodb主键索引结构与myisam索引结构最大的区别:
innodb主键索引树叶子节点存的是索引列的值和整行数据,而myisam主键索引(或普通索引)存储的是索引列的值和数据的地址(行号),由于myisam索引存的都是数据的行号地址,所以myisam查询数据走普通索引也不存在回表的情况。
执行过程:select * from user where name = "james"
1、找到name索引树(普通索引树结构:索引列的值和主键的值)
2、根据name的值找到该树下name索引和主键的值
3、用主键的值去主键索引树叶子节点找到数据并返回
注:其中2到3这个过程称为回表
如有错误地方欢迎大佬批评留言!