http://blog.csdn.net/a2011480169/article/details/53647012
http://hadoop.apache.org/
Apache Hadoop软件库是一个框架,允许使用简单的编程模型跨大型计算机对大型数据集进行分布式处理。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。
Hadoop2.0 项目包括以下模块:
Hadoop Common:用于支持其他Hadoop模块
HDFS:Haddop 分布式文件系统
Hadoop Yarn:作业调度和集群资源管理的框架
HadoopMapReduce用于并行处理大型数据集的基于YARN的系统
Hadoop1.0的HDFS结构如下图所示
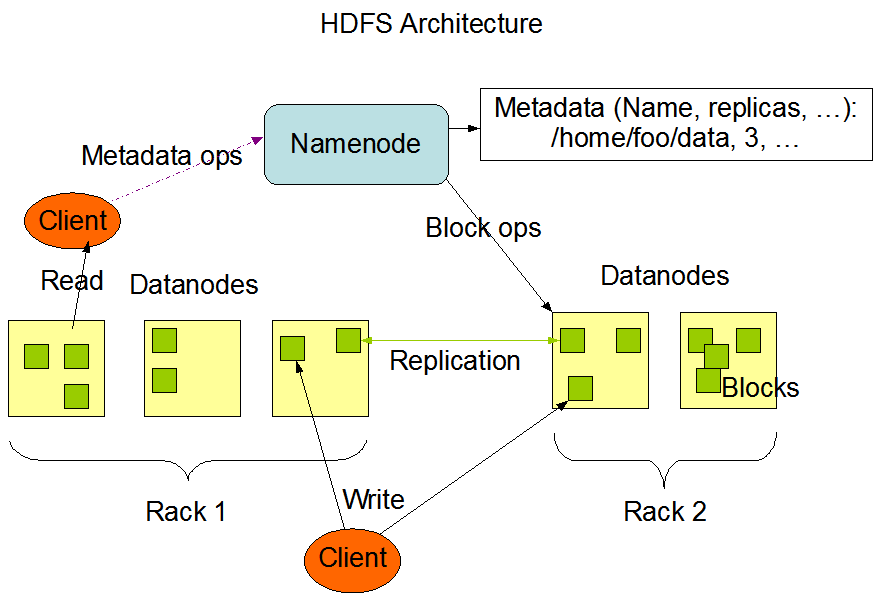
Haddop1.0的HDFS是一个主从结构,即一个HDFS集群包含一个NameNode和多个DataNode,如果namenode挂掉,文件的映射关系就没有了
Hadoop1.0的Mapreduce也是一个主从结构,即是一个JobTracker对应多个TaskTracker,JobTracker的工作太多,包括负责用户提交的任务、给TaskTracker分配任务并跟踪
针对上述问题,Hadoop2.0在HDFS和MapReduce上均做了改进
Hadoop2.0引入HDFS联邦和HA机制(待补充)
Hadoop2.0Yarn
Yarn是2.0的资源管理系统
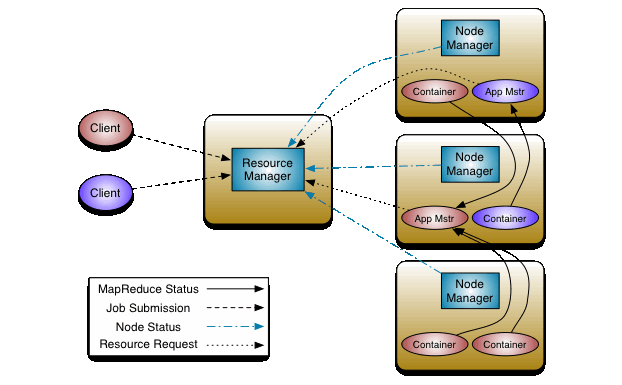
Yarn 基本上就是将Hadoop1.0中的Mapreduce的JobTracker拆分成ResourceManager和每个应用程序特有的AppMaster
ResourceManager:负责整个系统的资源管理和分配
AppMaster:负责任务的分配和监控,每个Job都有一个AppMaster
------------------------------------------------------------------------------待更------------------------------------------------------------------------------------------------------------------
