1、 集群环境
192.168.67.10
192.168.67.11
192.168.67.12
2、 关闭系统防火墙及内核防火墙
#master、slave1、slave2
#清空系统防火墙
iptables -F
#保存防火墙配置
service iptables save
#临时关闭内核防火墙
setenforce 0
#永久关闭内核防火墙
vim/etc/selinux/config
SELINUX=disabled
3、修改主机名
#master
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
NTPSERVERARGS=iburst
#slave1
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave1
NTPSERVERARGS=iburst
#slave2
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave2
NTPSERVERARGS=iburst
4、修改IP地址
#master、slave1、slave2(除IPADDR不一样其他属性都一样)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
BOOTPROT=static
NM_CONTROLLED=yes
ONBOOT=yes
TYPE=Ethernet
IPADDR=192.168.67.10
NETMASK=255.255.255.0
GATEWAY=192.168.67.2
DNS1=202.106.0.20
5、修改主机文件
#master、slave1、slave2
192.168.67.10 master
192.168.67.11 slave1
192.168.67.12 slave2
6、SSH互信配置
#生成秘钥对(公钥和私钥)
ssh-keygen -t rsa
#三次回车
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys
#相互追加key
#master
ssh slave1 cat /root/.ssh/authorized_keys >> /root/.ssh/authorized_keys
ssh slave2 cat /root/.ssh/authorized_keys >> /root/.ssh/authorized_keys
#slave1
ssh master cat /root/.ssh/authorized_keys > /root/.ssh/authorized_keys
#slave2
ssh master cat /root/.ssh/authorized_keys > /root/.ssh/authorized_keys
7、安装JDK
http://www.oracle.com/technetwork/java/javase/downloads/index.html
我下载的是jdk-8u152-linux-x64.tar.gz
把jdk-8u152-linux-x64.tar.gz放在share_folder文件夹下
把windows桌面上的share_folder中的jdk-8u152-linux-x64.tar.gz包复制到master虚拟机的/usr/local/src/目录中
#cd /mnt/hgfs/
#ls //展示路径中的所有文件
#cd share_folder/
# ls
#cp jdk-8u152-linux-x64.tar.gz /usr/local/src/
# tar zxvf jdk-8u152-linux-x64.tar.gz //解压
8、配置JDK环境变量
#master、slave1、slave2
vim ~/.bashrc
JAVA_HOME=/usr/local/src/jdk1.8.0_152
JAVA_BIN=/usr/local/src/jdk1.8.0_152/bin
JRE_HOME=/usr/local/src/jdk1.8.0_152/jre
CLASSPATH=/usr/local/jdk1.8.0_152/jre/lib:/usr/local/jdk1.8.0_152/lib:/usr/local/jdk1.8.0_152/jre/lib/charsets.jar
PATH=
9、JDK拷贝到slave主机
#master
scp -r /usr/local/src/jdk1.8.0_152 root@slave1:/usr/local/src/jdk1.8.0_152
scp -r /usr/local/src/jdk1.8.0_152 root@slave2:/usr/local/src/jdk1.8.0_152
10、下载hadoop2.0
#master
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.2/hadoop-2.8.2.tar.gz
tar zxvf hadoop-2.8.2.tar.gz
11、修改hadoop配置文件
cd hadoop-2.8.2/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim slaves
slave1
slave2
vim core-site.xml
fs.defaultFS
hdfs://192.168.67.10:9000
hadoop.tmp.dir
file:/usr/local/src/hadoop-2.8.2/tmp
vim hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.namenode.name.dir
file:/usr/local/src/hadoop-2.8.2/dfs/name
dfs.datanode.data.dir
file:/usr/local/src/hadoop-2.8.2/dfs/data
dfs.repliction
3
vim mapred-site.xml
mapreduce.framework.name
yarn
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8035
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
#创建临时目录和文件夹
mkdir /usr/local/src/hadoop-2.8.2/tmp
mkdir -p /usr/local/src/hadoop-2.8.2/dfs/name
mkdir -p /usr/local/src/hadoop-2.8.2/dfs/data
12、配置环境变量
#master、slave1、slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.8.2
export PATH=
#刷新环境变量
source ~/.bashrc
13、拷贝安装包
#master
scp -r /usr/local/src/hadoop-2.8.2 root@slave1:/usr/local/src/hadoop-2.8.2
scp -r /usr/local/src/hadoop-2.8.2 root@slave2:/usr/local/src/hadoop-2.8.2
14、启动集群
#maser
#初始化namenode,第一次启动需要初始化,以后都不需要了
hadoop namenode -format
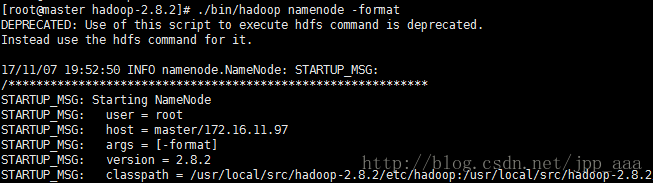
#启动集群
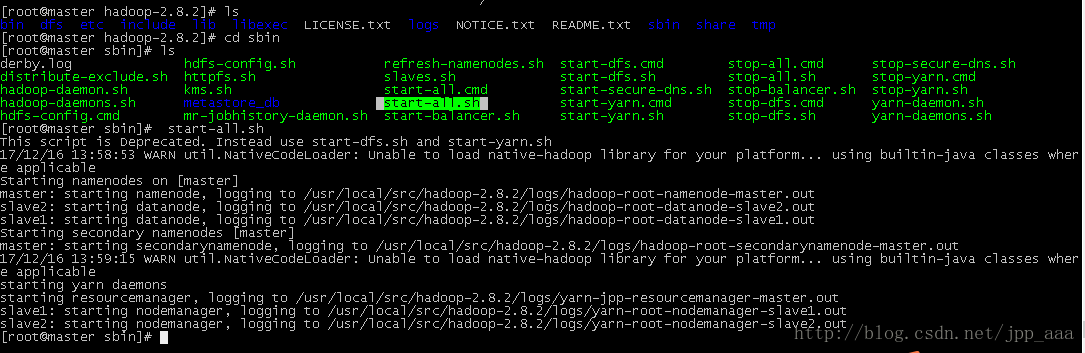
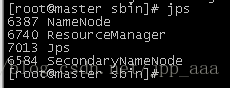
15、集群状态
#master
jps
注:之前有一篇文章是关于hadoop集群1.0搭建的,安装的JDK版本较低,现在hadoop2.0搭建安装的JDK版本为1.8,用之前的hadoop2.0对JDK版本是有要求的