hadoop 2.7集群搭建
目录
一:版本介绍
LINUX版本:centos6.5 64位版本(虚拟机三台机器,一主两从)
192.168.37.101
192.168.37.102
192.168.37.103
hadoop版本:2.7.7版本
JAVA版本:1.8.0
二:SSH免密
1、编辑hosts
在root用户下输入命令,vi /etc/hosts,用vi编辑hosts文件,如下:

2、生成authorized_keys文件
登录centos01,在.ssh目录下输入命令:
ssh-keygen -t rsa
,三次回车后,该目录下将会产生id_rsa,id_rsa.pub文件。其他主机也使用该方式产生密钥文件。

拷贝其它两台机器的秘钥文件到centos01

输入命令:
cat id_rsa.pub >> authorized_keys
cat id_rsa.pub.s1 >> authorized_keys
cat id_rsa.pub.s2 >> authorized_keys
修改authorized_keys权限
chmod 600 authorized_keys
输入命令
more authorized_keys
可以看到

拷贝 authorized_keys到另外两台机器的.ssh文件夹。免密码登录设定完成,注意第一次ssh登录时需要输入密码,再次访问时即可免密码登录。
三:安装JDK
1、解压jdk安装包
下载安装包jdk-8u191-linux-x64.tar.gz,解压文件
tar -zxvf jdk-8u191-linux-x64.tar.gz -C /home/www
解压后文件如下:

2、设置环境变量
vim /etc/profile
在/etc/profile添加如下内容
export JAVA_HOME=/home/www/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:
export PATH=$PATH:$JAVA_HOME/bin:
查看配置是否生效
java -version

四:安装hadoop
1、创建hadoop目录
为了便于管理,创建hdfs的NameNode、DataNode及临时文件,命令如下:
mkdir /home/hadoop
mkdir /home/hadoop/hdfs/data
mkdir /home/hadoop/hdfs/name
mkdir /home/hadoop/hdfs/temp
2、安装hadoop安装包
下载安装包hadoop-2.7.7.tar.gz,解压文件
tar -zxvf hadoop-2.7.7.tar.gz -C /home/hadoop
解压后文件如下:

3、设置环境变量
vim /etc/profile
在/etc/profile添加如下内容
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
expor tPATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
查看配置是否生效
hadoop version

4、设置hadoop配置文件
转到/home/hadoop/hadoop-2.7.7/etc/hadoop目录,需要修改如下5个文件:
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及slaves文件

4.1 修改hdfs-site.xml
vim hdfs-site.xml, 输入如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos01:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4.2 修改core-site.xml
vim core-site.xml, 输入如下内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hdfs/temp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://centos01:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
4.3 修改mapred-site.xml
vim mapred-site.xml, 输入如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.4 修改yarn-site.xml
vim yarn-site.xml, 其中centos01是主机名,输入如下内容:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>centos01:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>centos01:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>centos01:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>centos01:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>centos01:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.5 修改slaves
vim slaves, 输入如下内容:
centos02
centos03
4.6 修改hadoop-env与yarn-env
由于配置了环境变量。所以hadoop-env.sh与yarn-env.sh这两个文件不用修改,因为里面的配置是:
export JAVA_HOME=${JAVA_HOME}
五:启动hadoop
1、初始化hdsf
执行:hadoop namenode -format,看到如下证明启动成功

2、查看hadoop相关启动文件
进入/home/hadoop/hadoop-2.7.7/sbin/目录,可以看到很多的启动文件

3、 启动hdfs
输入命令:
./start-dfs.sh
看到如下启动日志

主机输入jps,看到如下进程
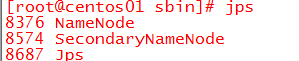
备机输入jps,看到如下进程

4、 启动yarn
输入命令:
./start-yarn.sh
看到如下启动日志

主机输入jps,看到如下进程
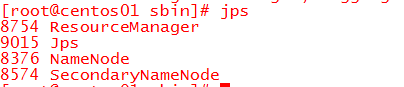
备机输入jps,看到如下进程
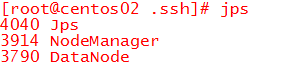
5、 验证是否启动成功
验证hdfs,进入/home/hadoop/hadoop-2.7.7/bin目录,输入命令
hdfs dfsadmin -report
看到如下:

验证yarn,登录http://192.168.37.101:18088/cluster/nodes(IP是主机IP,端口号是在yarn-site配置的),看到如下界面证明启动成功:

六:可能会运到问题FAQ
1、JDK版本配置完成后不对
使用which java 和 which javac 分别可以看到
[root@localhost ~]# which java
/usr/bin/java
[root@localhost ~]# which javac
/usr/bin/javac
简单说一下,就是把这2个文件ln -s 到我们新的jdk 下的 java 和 javac 上,命令如下:
rm -rf /usr/bin/java
rm -rf /usr/bin/javac
ln -s $JAVA_HOME/bin/javac /usr/bin/javac
ln -s $JAVA_HOME/bin/javac /usr/bin/java
这样执行以后,然后 java -version 、 javac -version 解决问题
2、hdfs report报异常
hdfs 会报java.net.NoRouteToHostException: No route to host的异常
./hdfs dfsadmin -report
report: No Route to Host from centos01/192.168.37.102 to centos01:9000 failed on socket timeout exception: java.net.NoRouteToHostException: No route to host; For more details see: http://wiki.apache.org/hadoop/NoRouteToHost
原因是由于防火墙开启,datanode连接不上namenode,导致datanode无法启动
关闭防火墙即可,输入命令
service iptables stop
可以看到

3、hadoop日志报异常(Unable to load native-hadoop library for your platform)
hadoop打印日志时会发现如下日志异常:

这里的主要原因是centos6.x的glibc版本过低,需要升级2.14版本,输入如下命令
strings /lib64/libc.so.6 | grep GLIBC
发现glibc版本是2.12

按照如下命令升级即可,编译时间超长,如果出现部分警告可忽略
# 下载 glibc 2.14源码
wget wget http://ftp.gnu.org/gnu/glibc/glibc-2.14.tar.gz
# 解压上一步下载后的源码
tar xvf glibc-2.14.tar.gz && cd glibc-2.14
# 在源码文件夹下创建一个build文件夹,编译生成的文件都放在此文夹下
mkdir build && cd build
# 如果是新机器,需要安装编译依赖
yum install gcc gcc-c++
# 在源码文件夹下创建一个build文件夹,编译生成的文件都放在此文夹下
mkdir build && cd build
# configure的时候,不能直接在解压目录configure
../configure --prefix=/usr
# 编译安装
make -j4 && make install
# 检验是否成功
ls -l /lib64/libc.so.6
lrwxrwxrwx 1 root root 12 Jul 23 16:17 /lib64/libc.so.6 -> libc-2.14.so
最终查看可以看到:

4、无法启动NodeManager
备机输入jps命令,无法看到NodeManager,原因是因为2.4以上的hadoop版本配置中的yarn-site.xml有变化
需要修改mapreduce.shuffle为mapreduce_shuffle
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
5、粘贴XML很多空格
在拷贝前输入:set paste (这样的话,vim就不会启动自动缩进,而只是纯拷贝粘贴)
拷贝完成之后,输入:set nopaste (关闭paste)