最基础、最简陋的numpy入门学习
目的是为了记录所使用的方法
nump中数据类型为numpy.ndarray(查询输出为<class ‘numpy.ndarray’>)
要学好还是要看官方文档传送门
一.数据初始化
1.数据插入
- 用 .array() 方法插入数组,用的较多
- 用 .arange() 方法产生,常在后面.reshape(high,low)来改变其形状
# t1,t2,t3等效
t1 = np.array([1, 2, 3])
t2 = np.array(range(10), dtype=float) # dtype改变所存储数值数据类型
t3 = np.arange(10)
print(type(t1)) # <class 'numpy.ndarray'>
2.数据类型修改
将数据类型改为flout型
t1.astype(“float”)
3.数据小数有效位数修改
- 用np.round(t, n) ,其中t为指定数组,n为要求保留位数
- 用python基础风阀round()修改
t2 = np.round(t1, 2) # 保留2位小数
a = round(random.random(), 3) # 等效,但一次只能改变一个数
4.特殊数组
- np.ones((2, 3))
创建全为1的数组 - np.zeros((2, 4))
创建全为0的数组 - np.eye(3)
创建对角为1的方阵
[[1,0,0],
[0,1,0],
[0,1,0]] - np.full((2,2), 7)
创建全部为7的2*2数组
# 注意:数据全部为flout型
t = np.ones((2, 3)) # 创建全为1的数组(2*3)
t = np.zeros((2, 3)) # 创建全为0的数组(2*3)
t = np.eye(3) # 创建对角为1的方阵(3*3)
t = np.full((2,2), 7) # 创建全部为7的2*2数组
5.特殊字符
- inf:infinity,inf表示正无穷,-inf表示负无穷
- nan:not a number表示不是一个数字
1.注意np.nan!=np.nan
2.nan与任何其他数计算结果都是nan
3.在数据处理中不适合将nun直接设置为0,视情况考虑
4.np.isnan(t) 方法判断t是不是nan,或者用(t!=t)判断
# 一个将数值中nun换成当列平均数的方法
t = np.arange(12).reshape((3, 4)).astype("float")
t[1, 2:] = np.nan
print(t)
# 将nan替换为所在列的平均数
for i in range(t.shape[1]):
temp = t[:, i]
nan_num = np.count_nonzero(temp != temp)
if nan_num != 0:
temp_arr = temp[temp == temp]
temp[np.isnan(temp)] = temp_arr.mean()
print(t)
# [[ 0. 1. 2. 3.]
# [ 4. 5. nan nan]
# [ 8. 9. 10. 11.]]
#
# [[ 0. 1. 2. 3.]
# [ 4. 5. 6. 7.]
# [ 8. 9. 10. 11.]]
二.数据调用以及修改
1.索引与切片
- numpy的索引与python中的列表索引操作一样


- 布尔索引
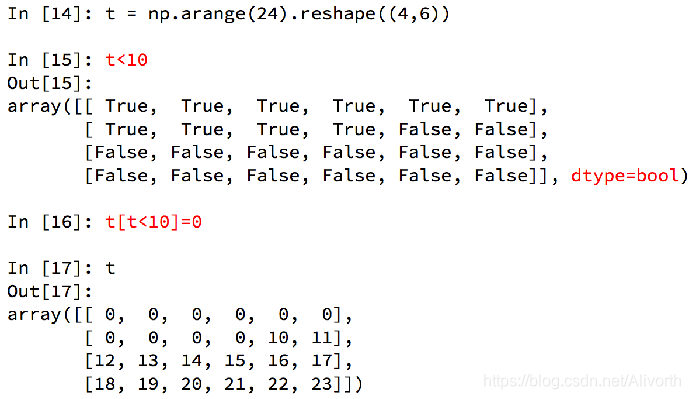
2.取部分元素
t[2,3] # 取某一个元素(类型int64)
t[[2, 3], [4, 2]] # 取(2,4)和(3,2)
t[2] # 单取第3行
t[[2, 3, 6]] # 取第3,4,7行(不连续)
3.修改某数值范围元素
- 直接赋值,如
t[1,3] = 1 - np.where(t2 < 20, 1, 20)方法,方法内变量风别是条件,满足则改变为(某数),不满足则改为(某数)
- t.clip(20, 40)方法,修剪,相当于剪枝,把小于20的改为20,大于40的改为40,剪掉小的和大的
# 三元运算(条件,满足则改变为,不满足则改为)
np.where(t2 < 20, 1, 20)
# 裁剪,把小于20的改为20,大于40的改为40
t.clip(20, 40)
4.拼接与交换
- 拼接的方法:vstack竖直拼接,hstack水平拼接
- 交换,下面的方法就是相当于重新赋值
# 拼接
np.vstack((t1, t2)) # 竖直拼接
np.hstack((t1, t2)) # 水平拼接
# 交换
t1[[1, 0], :] = t1[[0, 1], :] # 行交换
t1[:, [1, 0]] = t1[:, [0, 1]] # 列交换
三.数据的运算
1.形状
在运算之前首先要了解“形状” 是什么
- t.shape 为数组的属性, 输出结果表示为数组的形状
- t.reshape((high, low)) 方法可以改变数组的形状,但是必须确保数组可以正好容纳全部元素
- t.flatten() 方法可以直接把任意形状的数组展开到1维
t1 = np.array([1, 2, 3])
t2 = np.array([[1, 2, 3], [1, 2, 3]])
t3 = np.array([
[[1, 2, 3], [1, 2, 3]],
[[1, 2, 3], [1, 2, 3]]
])
t4 = np.array(range(1, 13))
print(t1.shape) # 输出 " (3,) " ,一维
print(t2.shape) # 输出 "(2, 3)" ,二维
print(t3.shape) # 输出 "(2, 2, 3)" ,三维
print(t4.reshape((3, 4))) # 改变原有的形状
print(t3.flatten()) # 展开(降维到1维度)
同时注意轴表示的是什么
图源 黑马程序员 的网课
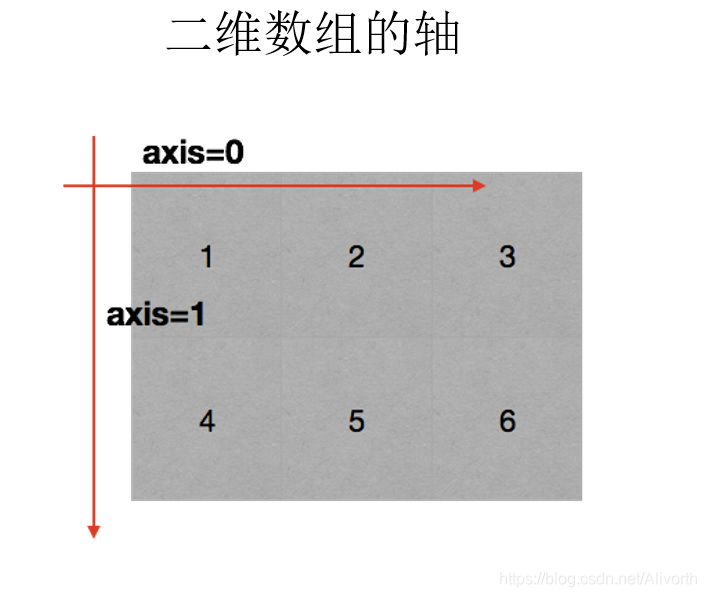
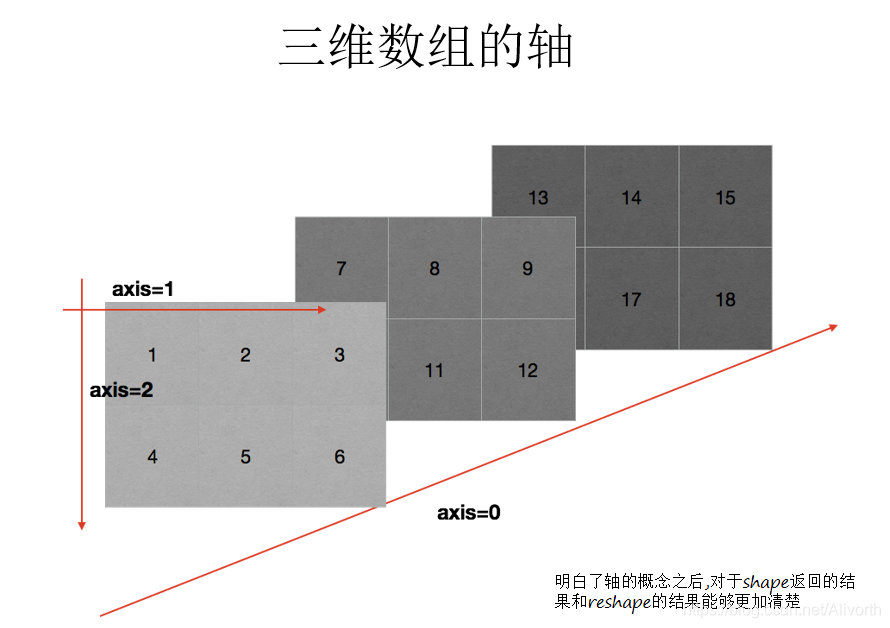
1.四则运算
nump数组的广播性,简单的四则运算都是在每个数组对应位置单个数字进行运算,不像线代中矩阵一样那种计算
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# 元素相加,都产生以下数组
# [[ 6.0 8.0]
# [10.0 12.0]]
print(x + y)
print(np.add(x, y))
# 元素相减,都产生以下数组
# [[-4.0 -4.0]
# [-4.0 -4.0]]
print(x - y)
print(np.subtract(x, y))
# 元素相乘,都产生以下数组
# [[ 5.0 12.0]
# [21.0 32.0]]
print(x * y)
print(np.multiply(x, y))
# 元素相除,都产生以下数组
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print(x / y)
print(np.divide(x, y))
# 元素开平方
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print(np.sqrt(x))
2.类矩阵变换
类矩阵变化的乘法运算
x.dot(y)
np.dot(x,y)
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
v = np.array([9,10])
w = np.array([11, 12])
# #向量的内积,都产生219
print(v.dot(w))
print(np.dot(v, w))
# #矩阵/向量乘积,都产生1级数组[29 67]
print(x.dot(v))
print(np.dot(x, v))
# #矩阵/矩阵乘积,都产生2级数组
# [[19 22]
# [43 50]]
print(x.dot(y))
print(np.dot(x, y))
3.数组转置
- t.transpose() 方法直接转置
- t.T 属性
- t.swapaxes(1, 0) 方法是换轴的方法,填入对应轴就会类似等效
t2.transpose()
t2.T # 与上面等效
t2.swapaxes(1, 0) # 换轴,类似等效
4.常用统计函数
默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
- 求和:t.sum(axis=None)
- 均值:t.mean(a,axis=None) 受离群点的影响较大
- 中值:np.median(t,axis=None)
- 最大值:t.max(axis=None)
- 最小值:t.min(axis=None)
- 极差值:np.ptp(t,axis=None) 即最大值和最小值只差
- 标准差:t.std(axis=None)
- 获取最大值最小值的位置:
np.argmax(t,axis=0)
np.argmin(t,axis=1) - np.count_nonzero(t) 方法统计t中有多少个数不是0(或者false)
# 求最大值最小值的位置
t10 = np.array([[1, 2, 3],[6, 7, 8]])
print(np.argmax(t10, axis=0)) # 每列最大
print(np.argmin(t10, axis=1)) # 每行最小
print(np.argmax(t10)) # 所有最大(按顺序,从0开始)
# [1 1 1]
# [0 0]
# 5
四.numpy中的随机数

# 随机数
a1 = np.random.seed(10) # 指定种子,后续产生的随机数与第一次的相同
a1 = np.random.rand(2, 3) # 在(0,1)生成浮点型随机数
a1 = np.random.randn(2, 3) # 在(0,1)生成标准正态分布随机数(平均数0,标准差1)
# 在(0,10)的范围生成整型随机数,形状为(2,3)
a1 = np.random.randint(0, 10, (2, 3))
# 在(0,10)的范围生成浮点型随机数,形状为(2,3)
a1 = np.random.uniform(0, 10, (2, 3))
五.本地文件导入
我导入的是csv文件,数据以“,”分割那种
导入方法:
np.loadtxt(fname,dtype=np.float,delimiter=None, skiprows=0,usecols=None, unpack=False)

# 此处路径不能有中文
text_path = "I:/trySomething/python/numpy/text.csv"
t1 = np.loadtxt(text_path, delimiter=",", dtype="int")
t2 = np.loadtxt(text_path, delimiter=",", dtype="int", unpack=True)
