看完简直秒懂!
集合类型及操作
集合类型定义
- 集合是多个元素的无序组合
- 集合类型与数学中的集合概念一致
- 集合元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型
- 集合用大括号 {} 表示,元素间用逗号分隔
- 建立集合类型用 {} 或 set()
- 建立空集合类型,必须使用set()
A = {"python", 123, ("python",123)} #使用{}建立集合
{123, 'python', ('python', 123)}
B = set("pypy123") #使用set()建立集合
{'1', 'p', '2', '3', 'y'}
C = {"python", 123, "python",123}#去除重复
{'python', 123}
集合处理函数及方法
- 集合类型通用操作符
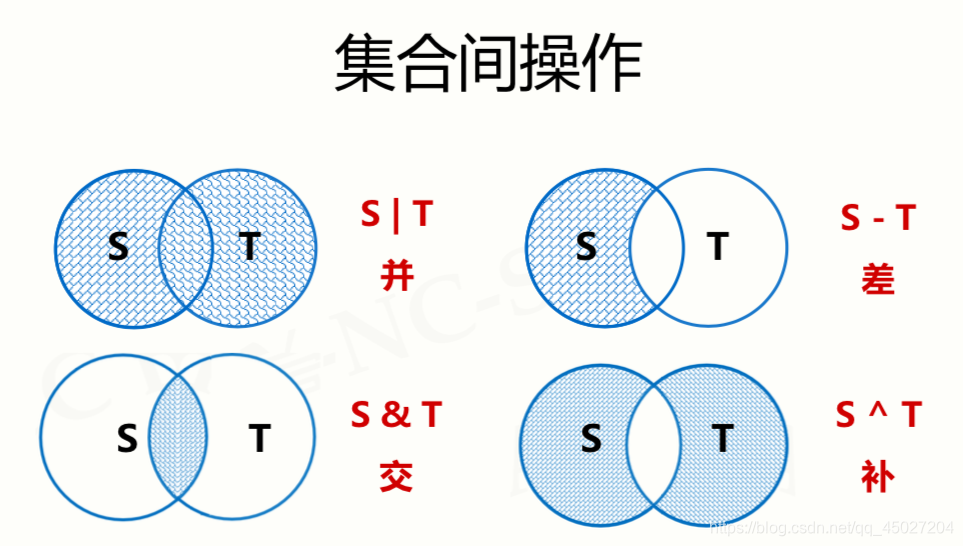
| 操作符及应用 | 描述 |
|---|---|
| S | T | 并,返回一个新集合,包括在集合S和T中的所有元素 |
| S-T | 差,返回一个新集合,包括在集合S但不在T中的元素 |
| S &T | 交,返回一个新集合,包括同时在集合S和T中的元素 |
| S ^T | 补,返回一个新集合,包括集合S和T中的非相同元素 |
| S <= T 或 S < T | 返回True/False,判断S和T的子集关系 |
| S >= T 或 S > T | 返回True/False,判断S和T的包含关系 |
| S | = T | 并,更新集合S,包括在集合S和T中的所有元素 |
| S -= T | 差,更新集合S,包括在集合S但不在T中的元素 |
| S &= T | 交,更新集合S,包括同时在集合S和T中的元素 |
| S ^= T | 补,更新集合S,包括集合S和T中的非相同元素 |
- 集合类型操作实例
A = {"p", "y" , 123}
B = set("pypy123")
A-B
{123}
B-A
{'3', '1', '2'}
A&B
{'p', 'y'}
A|B
{'1', 'p', '2', 'y', '3', 123}
- 集合类型通用函数和方法
| 操作函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果x不在集合S中,将x增加到S |
| S.discard(x) | 移除S中元素x,如果x不在集合S中,不报错 |
| S.remove(x) | 移除S中元素x,如果x不在集合S中,产生KeyError异常 |
| S.clear() | 移除S中所有元素 |
| S.pop() | 随机返回S的一个元素,更新S,若S为空产生KeyError异常 |
| S.copy() | 返回集合S的一个副本 |
| len(S) | 返回集合S的元素个数 |
| x in S | 判断S中元素x,x在集合S中,返回True,否则返回False |
| x not in S | 判断S中元素x,x不在集合S中,返回True,否则返回False |
| set(x) | 将其他类型变量x转变为集合类型 |
集合类型应用场景
- 包含关系比较
"p" in {"p", "y" , 123}
True
{"p", "y"} >= {"p", "y" , 123}
False
- 数据去重:集合类型所有元素无重复
>>> ls = ["p", "p", "y", "y", 123]
>>> s = set(ls) # 利用了集合无重复元素的特点
{'p', 'y', 123}
>>> lt = list(s) # 还可以将集合转换为列表
['p', 'y', 123]
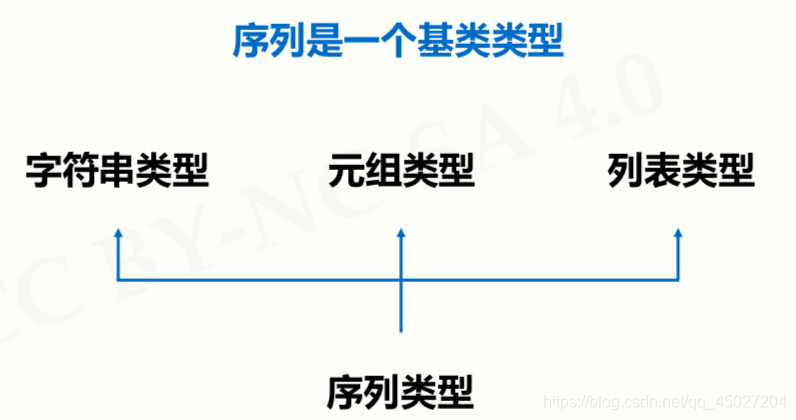
序列类型及操作
序列类型定义
- 序列是具有先后关系的一组元素
- 序列是一维元素向量,元素类型可以不同
- 类似数学元素序列: s0, s1, … , sn-1
- 元素间由序号引导,通过下标访问序列的特定元素
序列处理函数及方法
- 序列类型通用操作符
| 操作符及应用 | 描述 |
|---|---|
| x in s | 如果x是序列s的元素,返回True,否则返回False |
| x not in s | 如果x是序列s的元素,返回False,否则返回True |
| s+ t | 连接两个序列s和t |
| sn 或 ns | 将序列s复制n次 |
| s[i] | 索引,返回s中的第i个元素,i是序列的序号 |
| s[i: j] 或 s[i: j: k] | 切片,返回序列s中第i到j以k为步长的元素子序列 |
- 序列类型操作实例
>>> ls = ["python", 123, ".io"]
>>> ls[::-1]
['.io', 123, 'python']
>>> s = "python123.io"
>>> s[::-1]
'oi.321nohtyp'
- 序列类型通用函数和方法
| 函数和方法 | 描述 |
|---|---|
| len(s) | 返回序列s的长度,即元素个数 |
| min(s) | 返回序列s的最小元素,s中元素需要可比较 |
| max(s) | 返回序列s的最大元素,s中元素需要可比较 |
| s.index(x) 或 s.index(x, i, j) | 返回序列s从i开始到j位置中第一次出现元素x的位置 |
| s.count(x) | 返回序列s中出现x的总次数 |
- 序列类型操作实例
>>> ls = ["python", 123, ".io"]
>>> len(ls)
3
>>> s = "python123.io"
>>> max(s)
'y'
序列类型应用场景(元组与列表)
数据表示:元组 和 列表
- 元组用于元素不改变的应用场景,更多用于固定搭配场景
- 列表更加灵活,它是最常用的序列类型
- 最主要作用:表示一组有序数据,进而操作它们
1.元素遍历
for item in ls: <语句块>
for item in tp: <语句块>
2.数据保护
- 如果不希望数据被程序所改变,转换成元组类型
>>> ls = ["cat", "dog", "tiger", 1024]
>>> lt = tuple(ls)
>>> lt
('cat', 'dog', 'tiger', 1024)
元组类型及操作
元组类型定义
- 元组是序列类型的一种扩展
- 元组是一种序列类型,一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
- 可以使用或不使用小括号
>>> creature = "cat", "dog", "tiger", "human"
>>> creature
('cat', 'dog', 'tiger', 'human')
>>> color = (0x001100, "blue", creature)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
元组类型操作
- 元组继承序列类型的全部通用操作
- 元组继承了序列类型的全部通用操作
- 元组因为创建后不能修改,因此没有特殊操作
- 使用或不使用小括号
>>> creature = "cat", "dog", "tiger", "human" >>> creature[::-1]
('human', 'tiger', 'dog', 'cat')
>>> color = (0x001100, "blue", creature)
>>> color[-1][2]
'tiger'
列表类型及操作
列表类型定义
列表是序列类型的一种扩展,十分常用
- 列表是一种序列类型,创建后可以随意被修改
- 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔
- 列表中各元素类型可以不同,无长度限制
>>> ls = ["cat", "dog", "tiger", 1024]
>>> ls
['cat', 'dog', 'tiger', 1024]
>>> lt = ls
>>> lt
['cat', 'dog', 'tiger', 1024]
列表处理函数及方法
| 函数或方法 | 描述 |
|---|---|
| ls[i] = x | 替换列表ls第i元素为x |
| ls[i: j: k] = lt | 用列表lt替换ls切片后所对应元素子列表 |
| del ls[i] | 删除列表ls中第i元素 |
| del ls[i: j: k] | 删除列表ls中第i到第j以k为步长的元素 |
| ls += lt | 更新列表ls,将列表lt元素增加到列表ls中 |
| ls *= n | 更新列表ls,其元素重复n次 |
>>> ls = ["cat", "dog", "tiger", 1024]
>>> ls[1:2] = [1, 2, 3, 4]
['cat', 1, 2, 3, 4, 'tiger', 1024]
>>> del ls[::3]
[1, 2, 4, 'tiger']
>>> ls*2
[1, 2, 4, 'tiger', 1, 2, 4, 'tiger']
| 函数或方法 | 描述 |
|---|---|
| ls.append(x) | 在列表ls最后增加一个元素x |
| ls.clear() | 删除列表ls中所有元素 |
| ls.copy() | 生成一个新列表,赋值ls中所有元素 |
| ls.insert(i,x) | 在列表ls的第i位置增加元素x |
| ls.pop(i) | 将列表ls中第i位置元素取出并删除该元素 |
| ls.remove(x) | 将列表ls中出现的第一个元素x删除 |
| ls.reverse() | 将列表ls中的元素反转 |
>>> ls = ["cat", "dog", "tiger", 1024]
>>> ls.append(1234)
['cat', 'dog', 'tiger', 1024, 1234]
>>> ls.insert(3, "human")
['cat', 'dog', 'tiger', 'human', 1024, 1234]
>>> ls.reverse()
[1234, 1024, 'human', 'tiger', 'dog', 'cat']
字典类型及操作
字典类型定义
字典类型是“映射”的体现
- 键值对 : 键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 采用大括号{}和dict()创建,键值对用冒号: 表示
- {<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}

字典类型定义和使用
>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> d
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
>>> d["中国"]
'北京'
>>> de = {} ; type(de)
<class 'dict'>
字典处理函数及方法
| 函数或方法 | 描述 |
|---|---|
| del d[k] | 删除字典d中键k对应的数据值 |
| k in d | 判断键k是否在字典d中,如果在返回True,否则False |
| d.keys() | 返回字典d中所有的键信息 |
| d.values() | 返回字典d中所有的值信息 |
| d.items() | 返回字典d中所有的键值对信息 |
| d.get(k, ) | 键k存在,则返回相应值,不在则返回<default>值 |
| d.pop(k, ) | 键k存在,则取出相应值,不在则返回<default>值 |
| d.popitem() | 随机从字典d中取出一个键值对,以元组形式返回 |
| d.clear() | 删除所有的键值对 |
| len(d) | 返回字典d中元素的个数 |
>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> "中国" in d
True
>>> d.keys()
dict_keys(['中国', '美国', '法国'])
>>> d.values()
dict_values(['北京', '华盛顿', '巴黎'])
>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> d.get("中国","伊斯兰堡")
'北京'
>>> d.get("巴基斯坦","伊斯兰堡")
'伊斯兰堡'
>>> d.popitem()
('美国', '华盛顿')
字典类型应用场景
- 映射无处不在,键值对无处不在
- 例如:统计数据出现的次数,数据是键,次数是值
- 最主要作用:表达键值对数据,进而操作它们
1.元素遍历
for k in d : <语句块>
总结比较
1、集合类型及操作
- 集合使用{}和set()函数创建
- 集合间操作:交(&)、并(|)、差(-)、补(^)、比较(>=<)
- 集合类型方法:.add()、.discard()、.pop()等
- 集合类型主要应用于:包含关系比较、数据去重
2、序列类型及操作
- 序列是基类类型,扩展类型包括:字符串、元组和列表
- 元组用()和tuple()创建,列表用[]和set()创建
- 元组操作与序列操作基本相同
- 列表操作在序列操作基础上,增加了更多的灵活性
3、字典类型及操作
- 映射关系采用键值对表达
- 字典类型使用{}和dict()创建,键值对之间用:分隔
- d[key] 方式既可以索引,也可以赋值
- 字典类型有一批操作方法和函数,最重要的是.get()
本文整理自中国大学MOOC网/Python语言程序设计 嵩天老师的PPT和视频内容,如果有不清晰的知识点,可以搜索嵩天老师的视频进行学习,整理不易,有用记得收藏+点赞+评论哦。

