Ubuntu系统安装Hadoop3.1.3并进行单机/伪分布式配置
文章目录
前言
Hadoop官方真正支持的作业平台只有 Linux,在其他平台运行 Hadoop时,往往需要安装其他的包来提供一些 Linux操作系统的功能,以配合 Hadoop的执行。例如,在 Windows下运行 Hadoop,需要安装 Cygwin等软件。
Hadoop在 Linux操作系统上运行可以发挥最佳性能,建议大家使用 Linux系统来运行 Hadoop,可以去搭虚拟机或者买云服务器。
Hadoop安装方式:
- 单机模式:Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。
- 伪分布式模式:Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
- 分布式模式:使用多个节点构成集群环境来运行 Hadoop
单机模式和伪分布式模式在个人电脑上即可搭建,全分布式模式要求拥有集群实验环境,需要四台以上电脑作为节点。因为个人不具备集群条件,这里仅介绍 Hadoop的单机模式和伪分布式模式的配置。
详细流程
创建Hadoop用户
我们创建一个名为“hadoop”的用户来运行 Hadoop程序,这样可以使不同用户之间有明确的权限划分,也使得对 Hadoop的配置操作不影响其他用户的使用。
创建用户时建议使用 adduser而不是 useradd命令,因为 useradd 这个命令添加的用户不能远程登录,在本机登录时的登录界面也不会把所添加的用户列出来。
使用 adduser创建用户时会提示让用户设置密码,这个密码就是用户用来登录的密码,设置完毕请牢记此密码。
- Full Name是设置系统登录时展示的名字,通常我们是将首字母大写。比如用户名 hadoop,则登录名设置为 Hadoop。
- Room Name——Other等信息可以随意填写,也可以不填
- 最后输入 y进行确认即可
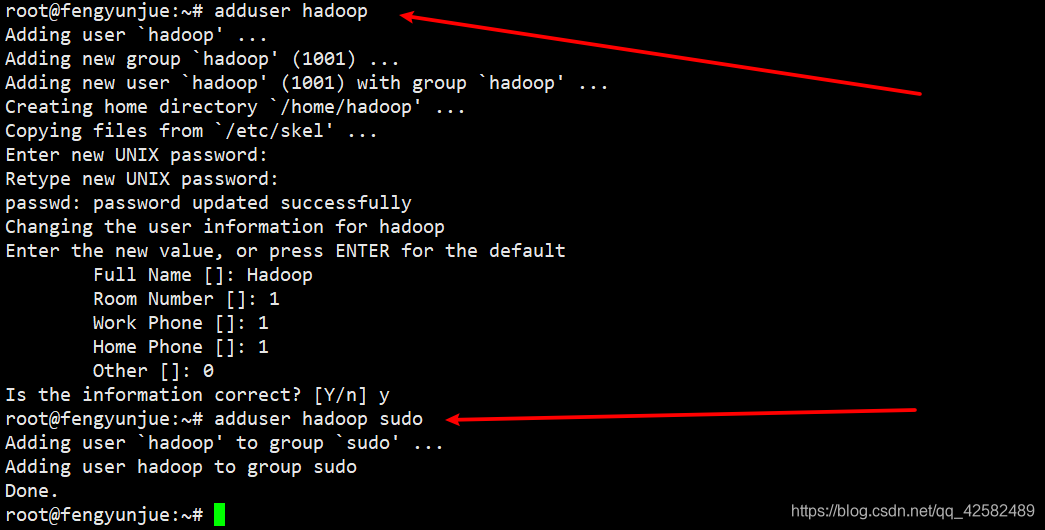
我们来创建一个新的普通用户 hadoop。
adduser hadoop //创建 hadoop用户
adduser hadoop sudo //增加管理员权限
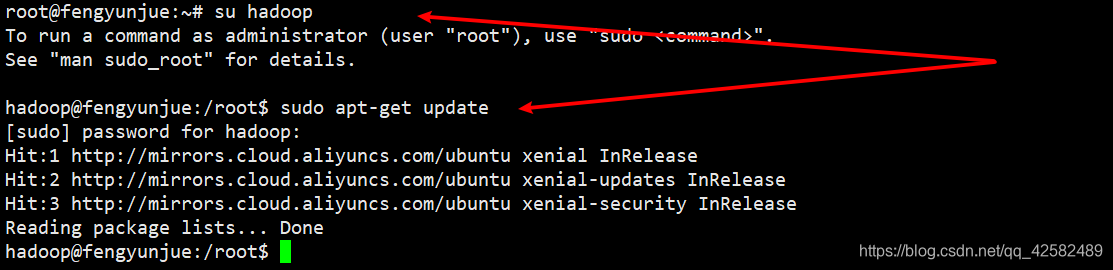
接着,我们把登录账户从 root切换到 hadoop,并更新 apt。
su hadoop
sudo apt-get update
如果想退出 hadoop用户,回到 root账户,输入命令 exit即可。
如果不想继续使用用户 hadoop了,想要删除用户,输入命令
sudo deluser hadoop

创建新的用户‘hadoop’成功,我们可以先退出 Ubuntu系统,下次启动 Ubuntu时就能直接使用 hadoop这个账户登录了。
安装Java
因为 Hadoop本神是使用 Java语言编写的,所以 Hadoop的开发和运行都必须有 Java环境的支持,通常要求Java 7 或者更高版本。
对于 Ubuntu来说,系统可能已经预装了 Java,JDK版本为 OpenJDK,路径为“/usr/lib/jvm/default-java”。Ubuntu系统卸载 OpenJDK命令为
sudo apt-get remove openjdk*
在 Linux系统中安装 Java的步骤我们前面已经说过了,如果已经不记得怎么安装 Java的话,请参考这篇博客 Linux系统安装JDK1.8 详细流程
建议在 /usr/lib下新建 jvm文件夹,把 JDK安装在 jvm文件夹中。
配置SSH免密登陆
对于 Hadoop的伪分布式和全分布式配置来说,名称节点(NameNode)需要启动集群中所有机器的 Hadoop守护进程,这个过程可以通过 SSH登录实现。然而 Hadoop并没有提供 SSH输入密码登录的形式,因此我们需要配置为名称节点无密码登录所有机器,伪分布式和全分布式才能给顺利启动。
Ubuntu系统默认已安装了 SSH client,我们还需要安装 SSH server
sudo apt-get install openssh-server

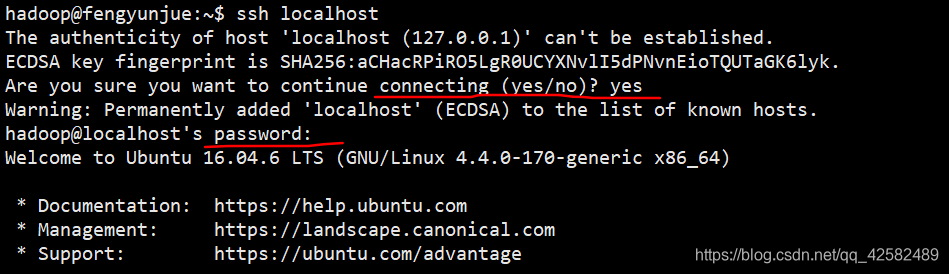
安装完成后,登录本机
ssh localhost
SSH首次登录会进行提示,输入 yes,接着按提示输入刚才 hadoop账户设置的密码,就可以登录本机了。
这样登录每次是需要输入密码的,接下来我们要配置无密码登录。
我们先退出 SSH
exit

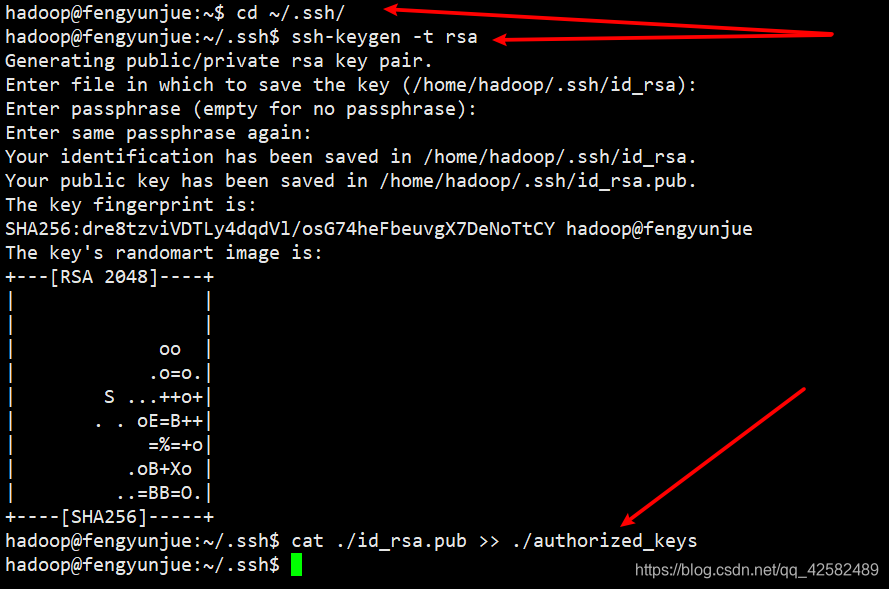
然后我们利用 ssh-keygen生成密钥,在~/.ssh中会生成两个文件:id_rsa和id_rsa.pub。id_rsa为私钥,id_rsa.pub为公钥,我们将公钥 id_rsa.pub追加到 authorized_keys中,因为 authorized_keys用于保存所有允许以当前用户身份登录到 ssh客户端用户的公钥内容。
cd ~/.ssh/
ssh-keygen -t rsa //如果有提示,按回车继续运行
cat ./id_rsa.pub >> ./authorized_keys //加入授权
授权完成之后,我们再使用 ssh localhost命令进行登录,就不需要输入密码了。
这里提醒一下大家,如果是通过虚拟机配置 SSH,这一步已经结束了,直接进入下一步安装 Hadoop。如果是通过服务器来配置 SSH,还需要修改 hostname配置文件才能进入下一步。
要修改该配置文件,输入命令
sudo vim /etc/hosts
按“i”进入编辑模式,在文件中加入一行代码
172.17.91.224 iZbp11gznj7n38xkztu6xxxx
这行代码中,172.17.91.224是你自己的云服务器的私有IP地址,iZbp11gznj7n38xkztu6xxxx则是云服务器实例中的 Ubuntu系统的主机名。
安装Hadoop3.1.3
为了方便操作,这里我们给出 Hadoop3.1.3的 tar包
链接:https://pan.baidu.com/s/1SJ-G0qfRl-_GmDIRzVY_3A
提取码:josc
当然,我们也可以去网络上下载自己想要的 Hadoop的版本。然而,考虑到 Hadoop官网是外网,下载速度会极其缓慢,还是推荐使用国内的镜像站进行下载。(实际上,Hadoop官网也推荐我们通过镜像站下载,并且推荐了北理工和清华两个镜像站)
这里我们使用北理工的镜像站下载 Hadoop的稳定版本 Hadoop北理工镜像。
镜像站提供了几个 Hadoop的稳定版本,根据自己的意愿选择即可。这里我们选择 hadoop-3.1.3。
进入目录后,我们选择下载 hadoop-3.1.3.tar.gz,大小是322M。
下载完成后,通过 WinSCP等软件传输到自己的虚拟机或者服务器中,就放在 /usr/local目录下。
然后我们进行解压安装,并修改文件权限
cd /usr/local/
sudo tar -zxvf hadoop-3.1.3.tar.gz //解压
sudo mv ./hadoop-3.1.3 ./hadoop //文件夹改名为hadoop
sudo chown -R hadoop ./hadoop //修改文件权限
hadoop-3.1.3已经解压完成,在开始使用之前,我们先测试一下 hadoop是否可用。
cd hadoop
./bin/hadoop version

成功显示 hadoop版本信息,hadoop可用。
Hadoop单机配置
因为 Hadoop默认的安装模式就是单机模式,所以我们仅需要配置 hadoop的环境变量即可。
在 Hadoop的文件目录下,/etc/hadoop文件夹中放的是配置文件。我们需要更改 hadoop-env.sh文件,把 JAVA_HOME环境变量指定到本机的JDK目录。
如果已经忘记了 JAVA_HOME的值,请在修改之前查看一下
echo $JAVA_HOME
cd /usr/local/hadoop/etc/hadoop
sudo vim hadoop-env.sh
按“i”进入编辑模式,配置 JAVA_HOME环境变量。修改完成后,按“esc”键,输入“:wq”保存并退出。
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_241
编辑完成后,使用 source命令使配置生效
source hadoop-env.sh

接着,编辑配置文件 /etc/profile,配置 hadoop环境变量 HADOOP_HOME。
cd ~
sudo vim /etc/profile
在配置文件中输入以下代码:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
编辑完成后保存并退出,使用 source命令使配置生效
source /etc/profile
测试环境是否配置成功
hadoop version
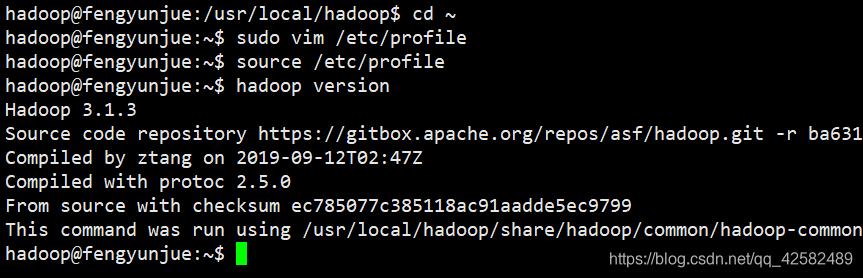
成功显示 Hadoop的版本信息,环境变量配置成功。
Hadoop单机运行实例
hadoop自带了大量的实例,包括 wordcount、terasort、grep等。我们可以运行一下这些实例,感受一下 hadoop单机模式的运行情况。这里我们运行实例 wordcount。
首先,在 hadoop目录下新建 input文件夹,用来存放输入数据。
cd $HADOOP_HOME
mkdir input
然后,将 /etc/hadoop文件夹下的一个配置文件 core-site.xml复制到 input文件夹中。
cp ./etc/hadoop/core-site.xml ./input
最后,执行实例 wordcount,统计各个单词出现的次数,将结果输出到 output文件夹。(output文件夹不用新建,系统运行会自动建立)
./bin/hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount ./input ./output
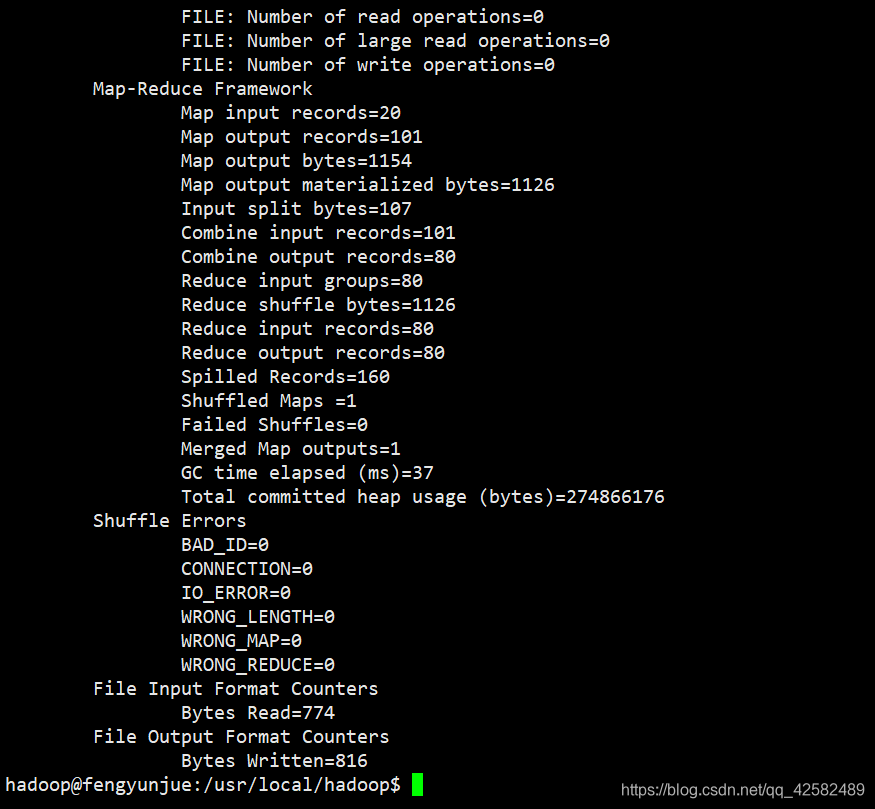
执行完成后,查看输出数据的内容
cat ./output/*
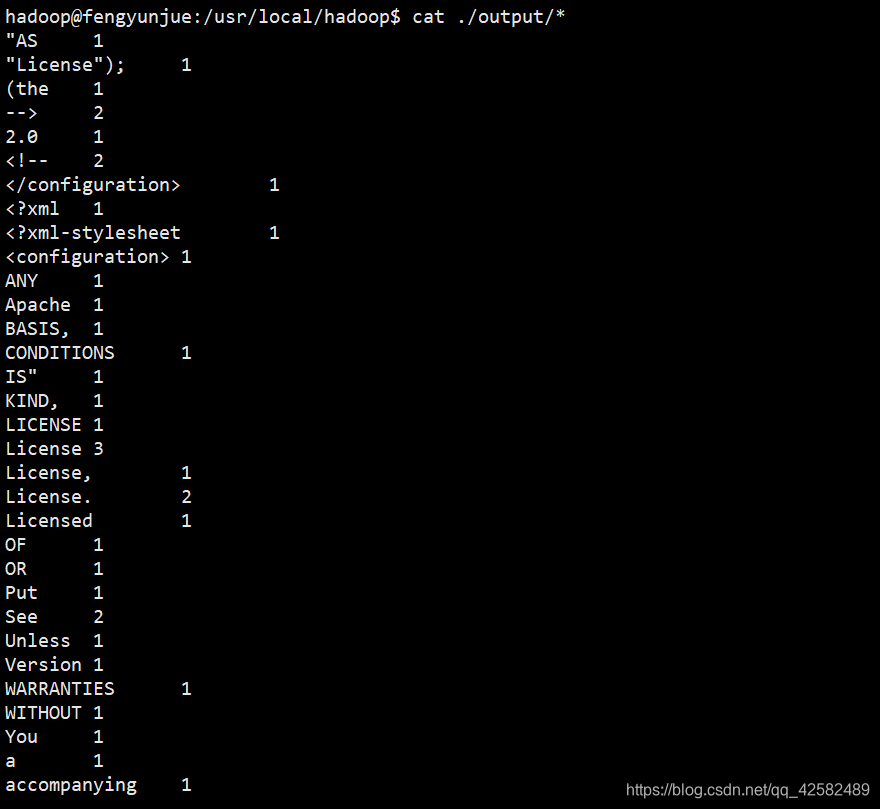
注意,Hadoop 默认不会覆盖结果文件,因此再次运行一个实例并且结果也是输出到output目录则会提示出错,需要先将 output 目录删除。
rm -r ./output
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。标签代表了配置项的名字,标签设置的是配置的值。Hadoop 的运行方式是由配置文件决定的,运行 Hadoop 时会读取配置文件。
对于伪分布式配置,我们需要修改 core-site.xml、hdfs-site.xml这两个文件。如果需要从伪分布式模式切换回单机模式,需要删除 core-site.xml、hdfs-site.xml 中的配置项。
core-site.xml、hdfs-site.xml单机模式仅有 configuration标签。
<configuration>
</configuration>
我们先修改 core-site.xml
cd $HADOOP_HOME
sudo vim ./etc/hadoop/core-site.xml
按“i”键进入编辑模式,core-site.xml修改为下面的配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改 core-site.xml的目的是配置 HDFS的 NameNode的地址,以及配置 Hadoop运行时产生的文件的目录。
- fs.default.name是NameNode的URI。hdfs://主机名:端口/
- hadoop.tmp.dir :Hadoop的默认临时路径。如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
编辑完成后,按“esc”键,输入“:wq!”强制编辑并退出。
如果出现 E212:can’t open file for writing错误,原因是权限不够,普通用户用 vim进行不了编辑保存,切换到 root账户再次尝试。

在 root账户下,我们使用以下这条命令进行保存。这条命令的含义是把当前编辑的文件的内容当做标准输入输入到命令sudo tee 文件名里去。
:w ! sudo tee %
如果这条命令还是不能保存刚才编辑的 core-site.xml文件,那就直接手动修改。在 Ubuntu的图形界面中找到 core-site.xml文件,把刚才的内容手动添加进去。
同理,将 hdfs-site.xml文件修改为下面的配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
- dfs.replication表示副本的数量,伪分布式要设置为1。
- dfs.namenode.name.dir表示本地磁盘目录,是存储 fsImage文件的地方。
- dfs.datanode.data.dir表示本地磁盘目录,HDFS数据存放 block的地方。
这两个 xml文件配置完成后,我们需要初始化 HDFS文件系统。Hadoop的很多工作都是在自带的 HDFS文件系统上完成的,因此需要将文件系统初始化之后才能进一步执行计算任务。
cd $HADOOP_HOME
./bin/hdfs namenode -format
在运行结果中看到“successfully formatted”提示信息,就意味着 hdfs初始化成功了。
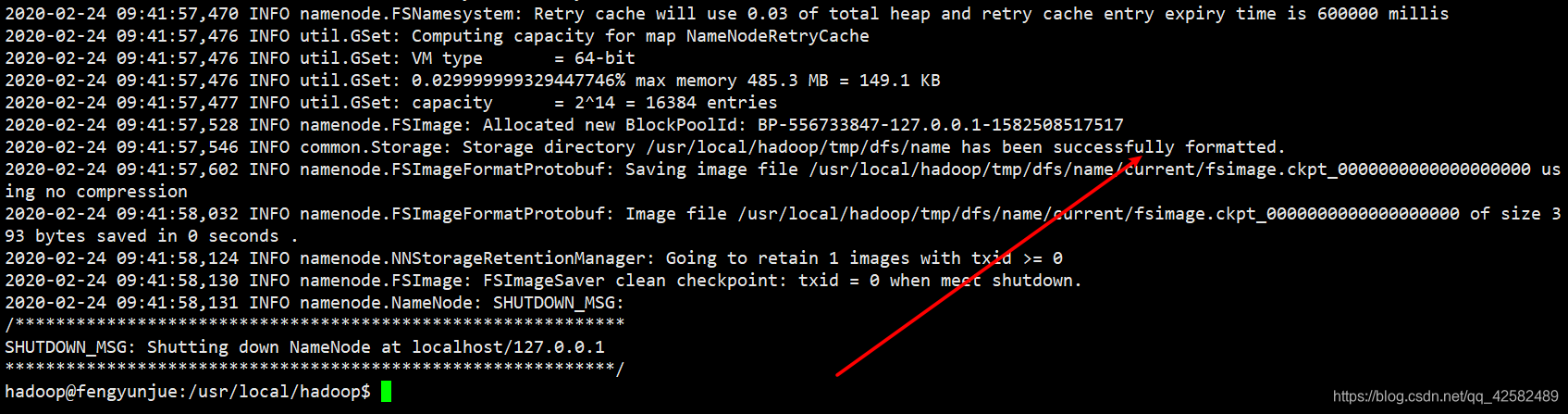
然后,我们启动 Hadoop的 NameNode和 DataNode守护进程。
cd $HADOOP_HOME
./sbin/start-dfs.sh
启动时如果出现SSH提示,输入 yes即可。还有,启动时可能会出现 WARN提示。这个提示可以忽略不计,不会影响 hadoop的正常使用。
Permanently added ‘xxxxxx’ (ECDSA) to the list of known hosts.
启动完成之后,输入 jps指令查看所有的 Java进程。
jps
如果出现以下四个进程,证明 Hadoop启动成功。
Jps
DataNode
NameNode
SecondaryNameNode
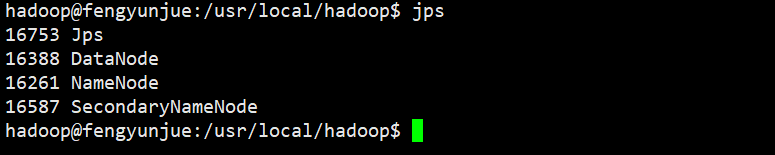
如果输入 jps指令出现以下错误,就是 java的环境变量没有生效,请使用 source命令使环境变量生效。
The program ‘jps’ can be found in the following packages: * openjdk-8-jdk-headless * openjdk-9-jdk
如果想要启动所有的 Hadoop进程,使用 all命令,启动过程中的 WARN可以忽略不计。伪分布式模式下我们仅 start-dfs就足够了,不必将全部进程都启动,全分布式模式才需要 start-all。
cd $HADOOP_HOME
./sbin/start-all.sh
Hadoop进程全部启动的话,会有六个进程
Jps
DataNode
NameNode
SecondaryNameNode
NodeManager
ResourceManager
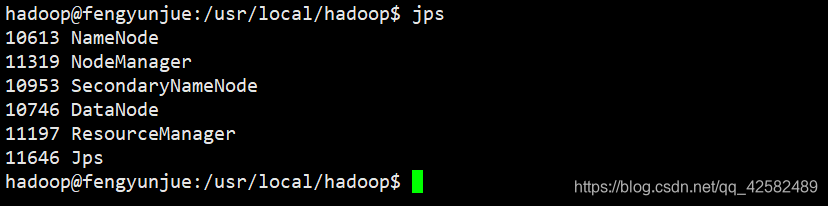
如果想要关闭 Hadoop,使用以下命令关闭 Hadoop守护进程。如果使用 all启动了全部进程,也请使用 all关闭全部进程。
//关闭守护进程
cd $HADOOP_HOME
./sbin/stop-dfs.sh
//关闭全部进程
cd $HADOOP_HOME
./sbin/stop-all.sh
如果 Hadoop启动之后输入 jps指令发现 DataNode节点没有启动,可以尝试一下删除 tmp文件夹,然后重新初始化 HDFS。
cd $HADOOP_HOME
./sbin/stop-dfs.sh
rm -r ./tmp
./bin/hdfs namenode -format
./sbin/start-dfs.sh
注意,这样会删除 HDFS中原有的所有数据,如果原有数据比较重要的话请做好备份。
Hadoop伪分布式运行实例
我们将单机模式下建立的 input和 output文件夹及其数据都删除。
cd $HADOOP_HOME
rm -r input output
在单机模式中,wordcount 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。
操作 HDFS的 Shell命令有三种:
- hadoop fs
- hadoop dfs
- hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和 HDFS文件系统;hadoop dfs、hdfs dfs只能适用于 HDFS文件系统。
首先,我们需要在 HDFS 中创建用户目录
cd $HADOOP_HOME
./bin/hdfs dfs -mkdir -p /user/hadoop
然后,在相对路径下建立新文件夹 input,将 ./etc/hadoop文件夹下的一个配置文件 core-site.xml复制到 input文件夹中。(我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,其对应的绝对路径就是 /user/hadoop/input)
./bin/hdfs dfs -mkdir /usr/hadoop/input
./bin/hdfs dfs -put ./etc/hadoop/core-site.xml /usr/hadoop/input
复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls /usr/hadoop/input

最后,执行实例 wordcount,统计各个单词出现的次数,将结果输出到 output文件夹。(伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件)
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /usr/hadoop/input /usr/hadoop/output

执行完成后,查看输出数据的内容(查看的是位于 HDFS 中的输出结果)
./bin/hdfs dfs -cat /usr/hadoop/output/*
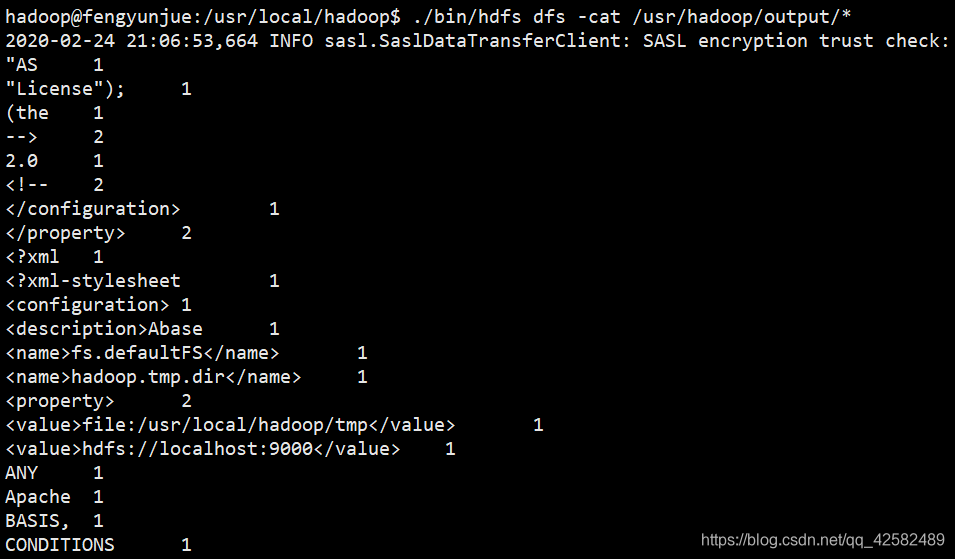
注意,Hadoop 默认不会覆盖结果文件,因此再次运行一个实例并且结果也是输出到output目录则会提示出错,需要先将 output 目录删除。
./bin/hdfs dfs -rm -r output
Web访问Hadoop信息
我们可以通过 Ubuntu的图形界面,打开 FireFox浏览器,在地址栏输入“localhost:9870”来查看 Hadoop信息。
如果是云服务器,请先在云控制台打开修改安全组,开放 9870端口,再通过“localhost : 9870”的形式访问。
很多博客都是说要用 50070端口进行访问,然而 hadoop2.x用的才是 50070端口,hadoop3.X的 webUI已经改到端口 localhost : 9870。
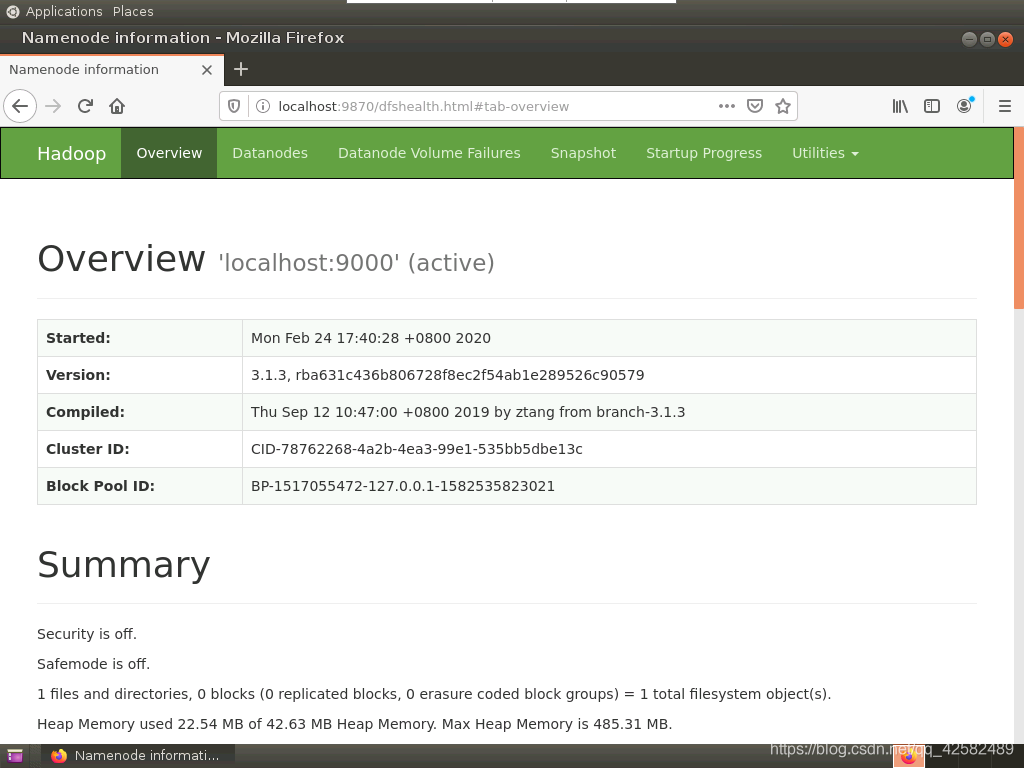
在打开 firefox浏览器的时候如果遇到无法加载的错误,请参考这篇博客进行解决 ubuntu自带的firefox浏览器只能以root权限使用
参考文章
Hadoop3.1.3安装教程_单机/伪分布式配_Hadoop3.1.3/Ubuntu18.04
Hadoop的HelloWorld(单机模式下的安装和使用)
