环境
Ubuntu18、openjdk-9、Hadoop3.1.3
因为近期网络问题,hadoop是阿里云的镜像,Ubuntu和jdk是华为云的镜像。
准备工作
更新apt
sudo apt-get update
安装SSH、配置SSH无密码登陆
sudo apt-get install openssh-server
ssh localhost
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
安装Java环境
使用手动安装的方式,下载openjdk 9。
安装的时候纠结了很久,为什么我安装的jdk和别人安装的java -version显示不一样,这里找到了区别,使用openjdk也是不影响的。OpenJDK和JDK区别
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
配置环境变量 vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存source ~/.bashrc,检查安装java -version
安装Hadoop
Hadoop安装文件,可以到Hadoop官网下载hadoop-3.1.3.tar.gz。
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
检查安装
cd /usr/local/hadoop
./bin/hadoop version
启动
单机配置
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
实例测试:在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
output结果是符合正则的单词 dfsadmin 出现了1次。
*运行中有报错找不到JAVA_HOME环境变量,解决办法是在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME
启动hadoop,报错Error JAVA_HOME is not set and could not be found
伪分布式配置
配置了一个namenode,datanode,secondarynamenode三个节点的集群。
1. 修改配置文件
Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
2. 格式化namenode
hadoop@mcq-virtual-machine:/usr/local/hadoop$ sudo ./bin/hdfs namenode -format
提示有一大串,出现common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted.这条就算成功了
3. 开启namenode,datanode守护进程
hadoop@mcq-virtual-machine:/usr/local/hadoop$ sudo ./sbin/start-dfs.sh
报错:WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [localhost]
localhost: root@localhost: Permission denied (publickey,password).
Starting datanodes
localhost: root@localhost: Permission denied (publickey,password).
Starting secondary namenodes [mcq-virtual-machine]
mcq-virtual-machine: root@mcq-virtual-machine: Permission denied (publickey,password).
解决:注意到被permission denied的用户名是root@localhost,我猜想是root用户的远程ssh登录出了问题,网上最常见的解决办法是修改ssh的配置文件/etc/ssh/sshd_config,把其中PermitRootLogin项由默认的prohibit-password改为yes,然后重启sshsudo service ssh restart。
大部分人到此就解决了,而我这里只解决了一部分,ssh root@localhost输入root密码之后可以ssh登录了(之前测试输对密码也会提升permission denied),但是执行start-dfs依然报上述错。
之前不是配置过ssh免登录吗?为什么ssh root的时候还要密码呢?这时猜想会不会root用户需要单独配置一次ssh免登录。试了一下,果然成功了。
HDFS的web页面默认端口是9870,yarn的web页面端口是8088。另外,jps命令查看节点时,也需要在特权用户root下。
运行实例
实际上有三种shell命令方式。
1. hadoop fs
2. hadoop dfs
3. hdfs dfs_
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
将配置文件作为输入文件,put指令放入HDFS系统中,ls查看,get指令从HDFS中取回本地
#创建用户目录
hadoop@mcq-virtual-machine:/usr/local/hadoop$ sudo ./bin/hdfs dfs -mkdir -p /user/hadoop
#放入HDFS
hadoop@mcq-virtual-machine:/usr/local/hadoop$ sudo ./bin/hdfs dfs -put ./etc/hadoop/*.xml /input
#执行
hadoop@mcq-virtual-machine:/usr/local/hadoop$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input /output 'dfs[a-z.]+'
#查看
hadoop@mcq-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -cat /output/*
#从HDFS取出
hadoop@mcq-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /output ./output
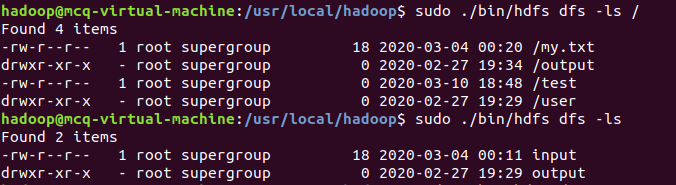
问题:hdfs用-ls查看根目录时,
如果加了/,里边的路径全部需要前置/
如果不加 /,不加sudo,那么不返回任何内容;加了sudo,有返回,但目录里没有/
参考资料
http://dblab.xmu.edu.cn/blog/2441-2/
