文章目录

Pre
我们在 Redis进阶-Redis缓存优化中 讲到了 缓存穿透 的解决防范: 比缓存空值更好的一种解决方式 布隆过滤器 ,这里我们详细讲解下。
布隆能解决哪些问题?
举个例子 : 有50亿个电话号码,现在给你10万个电话号码,如何快速准确的判断出这些号码是否存在?
方案A: DB ? ----> 50亿的电话号码,这查询效率 ?
方案B: 内存 ? —> 就按1个电话号码8个字节 , 50亿*8字节= 40G 内存…
方案C: hyperloglog? ----> 准确率有点低
类似的问题还有很多,比如
- 垃圾邮件过滤
- 文字处理软件(比如word)错误单词检测
- 网络爬虫重复URL检测
- hbase 行过滤
- …
BloomFilter实现原理
1970年由伯顿.布隆提出 ,用很小的空间解决上述的问题
一个很长的二进制向量(你就理解为它底层的数据结构是一个超级巨大的数组,只存0和1) , 加上 若干个 hash函数

有 k个 hash函数, 进行k次运算,把每次hash运算的结果设置到对应的位上,获取的时候 再把这些hash函数重新算一遍,如果有一个不是1 ,则布隆过滤器认为这个数不存在,只有全部都是1 才存在。
存 和 取 的计算方法一定要一样,否则就歇菜了。。。。
构建布隆过滤器
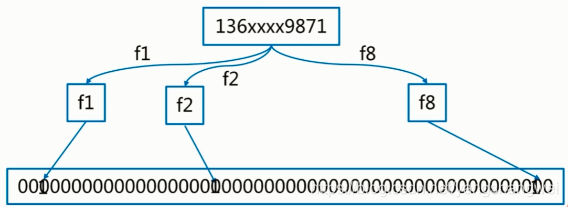
参数: m个二进制向量, n个预备数据,k个哈希函数
构建布隆过滤器: n个预备数据走一遍上面过程
判断元素存在与否:将这个数据,重走一遍构建的过程(进行k次hash运算),如果都是1,则表示存在,反之不存在。
构建布隆的误差率
首先声明,使用布隆过滤器一定要接受误差 ,有存在可能的误差。肯定存在误差,即恰好都命中了
举个例子,有两个值经过k次hash运算,计算的值都为1,这个时候其实你的底层数组中只有一个值,而布隆告诉你另外一个值也存在
参数: m个二进制向量, n个预备数据,k个哈希函数
直观因素: m/n 的比率, hash函数的个数
假设你的用于存储映射关系的二进制向量m 设置的很小 ,比如1000 (以Guava为例,设置1000并不是说只能存储1000个,Guava底层有大量的数据计算,结合你设置的误差率,计算出一个超级大的数组长度), 你的 n (数据量) 又超级多,比如100个亿,有3个hash函数用来计算。
这个时候我有一条数据“artisan ”,
经过第一个hash函数运算 存储到了底层数组中的第5个元素的位置
经过第二个hash函数运算 存储到了底层数组中的第100个元素的位置
经过第三个hash函数运算 存储到了底层数组中的第1024个元素的位置
这个时候 你要判断 artisan存在与否,只需要重新运算这个3个hash函数,只要 第5 100 1024元素位置对应的值都是1 ,那么就认为它存在。 只要有一个为0 ,就不存在。
假设我还有另外一条数据 xxxx , 经过三次hash计算,如果他正好也落在第5 100 1024个元素位置,那布隆告诉你了 xxx存在,实际上呢? 实际上 第5 100 1024是artisan这个值计算出来的,而不是xxx ,这就造成了数据的不准确,你要接受这误差可能性。
m/n 与误差率成反比, k与误差率成反比
m/n 与误差率成反比: m个二进制向量, n个预备数据 , 你用来存储二进制的数组m越大,你实际需要存储的数据 n越小,那么m/n 是不是就越大? 那误差率就相应的越低了。
k与误差率成反比 : 这个也好理解,假设你只有1个哈希函数,是不是你重复的概率就高很多? 所以说 k越大,误差率越低。
实际误差率推算
参数: m个二进制向量, n个预备数据,k个哈希函数
-
1) 1个元素,1个hash函数, 任何一个bit为1的概率为 1/m , 为0的概率为 1- 1/m
-
2) k个函数,为0的概率为 (1-1/m)的k次方, n个元素,依然为0的概率为 (1-1/m)的nk次方
-
3) 被设置为1的概率为 1 - (1-1/m)的nk次方
-
4) 新元素全中的概率为
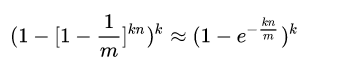
布隆过滤器 (JVM级别)
可以先了解下BitMap Algorithms_算法专项_Bitmap原理及应用
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class GuavaBloomFilterTest {
// BloomFilter 容量 (实际上Guava通过计算后开辟的空间远远大于capacity)
private static final int capacity = 100000;
// 构建 BloomFilter
private static BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity);
// 模拟初始化数据
static{
for (int i = 0; i < capacity; i++) {
bloomFilter.put(i);
}
}
public static void main(String[] args) {
int testData = 999;
long startTime = System.nanoTime();
if (bloomFilter.mightContain(testData)){
System.out.println(testData + " 包含在布隆过滤器中 ");
}
System.out.println("消耗时间: " + (System.nanoTime() - startTime) + " 微秒");
// 错误率判断
double errNums = 0;
for (int i = capacity + 1000000; i < capacity + 2000000; i++) {
if (bloomFilter.mightContain(i)) {
++errNums;
}
}
System.out.println("错误率: " + (errNums/1000000));
}
}
本地布隆过滤器的问题
- 容量受到本地容器比如tomcat 的jvm内存的限制
- 多个应用存在多个布隆过滤器,构建同步复杂 (类比session,就好理解了)

- 重启应用缓存内容需要重新构建
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送.
布隆过滤器返回某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
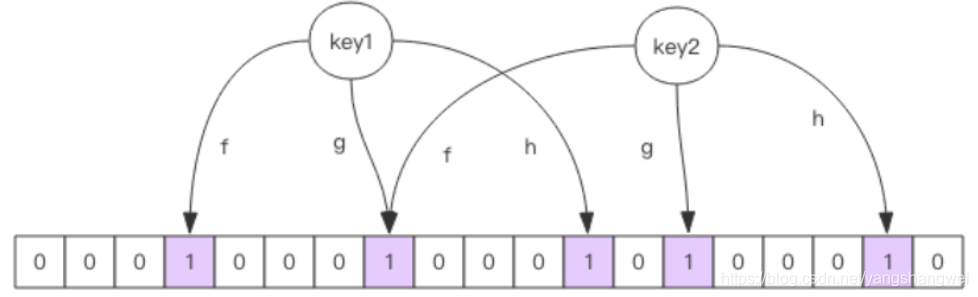
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。
所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。
如果都是 1,这并不能说明这个key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致.
如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少 .
伪代码如下
可以用guvua包自带的布隆过滤器,引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
import com.google.common.hash.BloomFilter;
//初始化布隆过滤器
//1000:期望存入的数据个数,0.001:期望的误差率
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf‐8")), 1000, 0.001);
//把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
String get(String key) {
// 从布隆过滤器这一级缓存判断下key是否存在
Boolean exist = bloomFilter.mightContain(key);
if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
布隆过滤器 (分布式)
我们分析了本地布隆过滤器的缺点 ,仅仅存在单个应用中,多个应用之间的布隆过滤器同步困难,而且一旦应用重启,缓存丢失。
对于分布式环境,可以利用 Redis 构建分布式布隆过滤器
使用redisson 框架
https://github.com/redisson/redisson/wiki/6.-distributed-objects#68-bloom-filter
RBloomFilter<SomeObject> bloomFilter = redisson.getBloomFilter("sample");
// initialize bloom filter with
// expectedInsertions = 55000000
// falseProbability = 0.03
bloomFilter.tryInit(55000000L, 0.03);
bloomFilter.add(new SomeObject("field1Value", "field2Value"));
bloomFilter.add(new SomeObject("field5Value", "field8Value"));
bloomFilter.contains(new SomeObject("field1Value", "field8Value"));
bloomFilter.count();
redis布隆过滤器 主要解决的场景是 缓存穿透 ,导致大量的请求落到DB上,压垮DB。
所以布隆过滤器应该在 redis缓存和 DB之间 。
布隆告诉你 ,存在的不一定存在,不存在的一定不存在。 所以 当你从DB中没有查到值的时候,你应该把这个key更新到布隆过滤器中,下次这个key再过来的时候,直接返回不存在了,无需再次查询DB。
伪代码如下
public String getByKey(String key) {
String value = get(key);
if (StringUtils.isEmpty(value)) {
logger.info("Redis 没命中 {}", key);
if (bloomFilter.mightContain(key)) {
logger.info("BloomFilter 命中 {}", key);
return value;
} else {
if (mapDB.containsKey(key)) {
logger.info("更新 Key {} 到 Redis", key);
String valDB = mapDB.get(key);
set(key, valDB);
return valDB;
} else {
logger.info("更新 Key {} 到 BloomFilter", key);
bloomFilter.put(key);
return value;
}
}
} else {
logger.info("Redis 命中 {}", key);
return value;
}
}
Bloom Filter的缺点
bloom filter牺牲了判断的准确率、删除的便利性 ,才做到在时间和空间上的效率比较高,是因为
-
存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
-
删除数据。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以考虑Counting Bloom Filter
