布隆算法是一个以牺牲一定的准确率来换取低内存消耗的过滤算法,可以实现大量数据的过滤、去重等操作。
本博客不讨论布隆算法的具体原理,如果想了解的可以查看这篇博客:布隆过滤器(Bloom Filter)详解
为了实现分布式过滤器,在这里使用了Redis,利用Redis的BitMap实现布隆过滤器的底层映射。
布隆过滤器的一个关键点就是如何根据预计插入量和可接受的错误率推导出合适的BIt数组长度和Hash函数个数,当然Hash函数的选取也能影响到过滤器的准确率和性能。为此我参考了Google的guava包中有关布隆过滤器的相关实现。
同时我还利用的Spring实现RedisBean和FilterBean的管理工作。利用Maven实现jar包的管理工作,
首先看下项目需要的jar包,这里面的jar版本大家可以去maven仓库中选择自己需要的版本。我这里的好多jar包版本都是继承了父亲的版本所以有些dependency中没有版本号。
<!--spring-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-expression</artifactId>
</dependency>
<!-- redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${redis.version}</version>
</dependency>
<!-- guava-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<!-- junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>Spring配置下Redis的Bean
<!-- 引入redis属性参数文件-->
<util:properties id="redis" location="classpath:redis.properties"/>
<!--Jedis连接池的相关配置-->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!--新版是maxTotal,旧版是maxActive-->
<property name="maxTotal" value="#{redis['redis.pool.maxActive']}"/>
<property name="maxIdle" value="#{redis['redis.pool.maxIdle']}"/>
<property name="testOnBorrow" value="true"/>
<property name="testOnReturn" value="true"/>
</bean>
<bean id="jedisPool" class="redis.clients.jedis.JedisPool">
<constructor-arg name="poolConfig" ref="jedisPoolConfig"/>
<constructor-arg name="host" value="#{redis['redis.host']}"/>
<constructor-arg name="port" value="#{redis['redis.port']}" type="int"/>
<constructor-arg name="timeout" value="#{redis['redis.timeout']}" type="int"/>
<constructor-arg name="password" value="#{redis['redis.password']}"/>
<constructor-arg name="database" value="#{redis['redis.database']}" type="int"/>
</bean>下面是Redis链接的配置文件redis.properties
#最大分配的对象数
redis.pool.maxActive=1
#最大能够保持idel状态的对象数
redis.pool.maxIdle=1
redis.host=自己的地址
redis.port=6379
redis.timeout=30000
redis.password=自己的密码
redis.database=0下面就是布隆过滤器的核心实现类BloomFilter.java
import com.google.common.hash.Funnels;
import com.google.common.hash.Hashing;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.Pipeline;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.io.IOException;
import java.nio.charset.Charset;
public class BloomFilter {
@Resource
private JedisPool jedisPool;
//预计插入量
private long expectedInsertions = 1000;
//可接受的错误率
private double fpp = 0.001F;
//布隆过滤器的键在Redis中的前缀 利用它可以统计过滤器对Redis的使用情况
private String redisKeyPrefix = "bf:";
private Jedis jedis;
//利用该初始化方法从Redis连接池中获取一个Redis链接
@PostConstruct
public void init(){
this.jedis = jedisPool.getResource();
}
public void setExpectedInsertions(long expectedInsertions) {
this.expectedInsertions = expectedInsertions;
}
public void setFpp(double fpp) {
this.fpp = fpp;
}
public void setRedisKeyPrefix(String redisKeyPrefix) {
this.redisKeyPrefix = redisKeyPrefix;
}
//bit数组长度
private long numBits = optimalNumOfBits(expectedInsertions, fpp);
//hash函数数量
private int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
//计算hash函数个数 方法来自guava
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
//计算bit数组长度 方法来自guava
private long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 判断keys是否存在于集合where中
*/
public boolean isExist(String where, String key) {
long[] indexs = getIndexs(key);
boolean result;
//这里使用了Redis管道来降低过滤器运行当中访问Redis次数 降低Redis并发量
Pipeline pipeline = jedis.pipelined();
try {
for (long index : indexs) {
pipeline.getbit(getRedisKey(where), index);
}
result = !pipeline.syncAndReturnAll().contains(false);
} finally {
try {
pipeline.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (!result) {
put(where, key);
}
return result;
}
/**
* 将key存入redis bitmap
*/
private void put(String where, String key) {
long[] indexs = getIndexs(key);
//这里使用了Redis管道来降低过滤器运行当中访问Redis次数 降低Redis并发量
Pipeline pipeline = jedis.pipelined();
try {
for (long index : indexs) {
pipeline.setbit(getRedisKey(where), index, true);
}
pipeline.sync();
} finally {
try {
pipeline.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 根据key获取bitmap下标 方法来自guava
*/
private long[] getIndexs(String key) {
long hash1 = hash(key);
long hash2 = hash1 >>> 16;
long[] result = new long[numHashFunctions];
for (int i = 0; i < numHashFunctions; i++) {
long combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
result[i] = combinedHash % numBits;
}
return result;
}
/**
* 获取一个hash值 方法来自guava
*/
private long hash(String key) {
Charset charset = Charset.forName("UTF-8");
return Hashing.murmur3_128().hashObject(key, Funnels.stringFunnel(charset)).asLong();
}
private String getRedisKey(String where) {
return redisKeyPrefix + where;
}
}这里我需要提到一点就是在插入或者获取Redis BitMap里面的的值时我都使用了Redis的管道Pipeline,这么做的目的是将一次判断中的多次操作合并为一次,避免过滤器在大量调用时造成Redis并发量太高的问题。
接下来就可以把过滤器配置进Spring中交给它来管理,Spring配置文件中过滤器配置如下。
<bean id="bloomFilter" class="your.package.BloomFilter">
<!--预计插入量 默认100000000-->
<property name="expectedInsertions" value="100000000"/>
<!--redis里面的key前缀 默认 bf:-->
<property name="redisKeyPrefix" value="bf:"/>
<!--允许的错误率-->
<property name="fpp" value="0.001"/>
</bean>这样一个过滤器就可以在项目当中使用了,我们利用Junit进行测试,测试类FilterTest代码如下。
import your.package.BloomFilter;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class FilterTest {
@Test
public void testFilter() {
ApplicationContext context = new ClassPathXmlApplicationContext("spring/applicationContext.xml");
BloomFilter filter = context.getBean("bloomFilter", BloomFilter.class);
System.out.println(filter.isExist("aaa", "aaa"));
System.out.println(filter.isExist("aaa", "aaa"));
System.out.println(filter.isExist("aaa", "bbb"));
System.out.println(filter.isExist("bbb", "aaa"));
}
}运行结果如下。
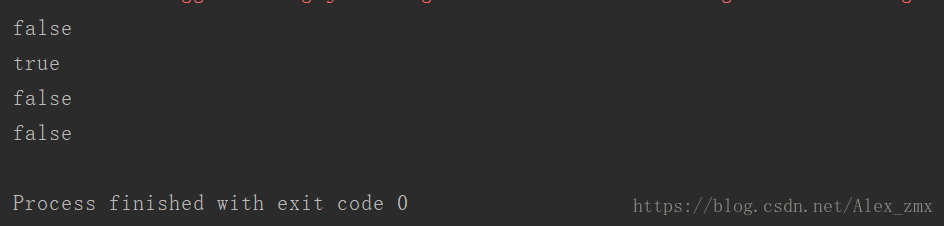
到这里一个完整的基于Redis的分布式布隆过滤器的实现就完成了,这部分代码的不足之处是对于Redis中Key的过期问题没有涉及,这一部分的实现需要大家根据各自的需要进行实现(具体可能要考虑业务上对于某些过滤是否有时限)。
这是本人的第一篇博客,希望可以帮助到大家,如果有任何建议和意见欢迎在下面留言。