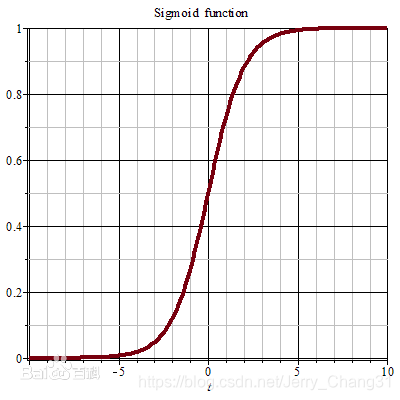
值得注意的是,逻辑回归(logistic regression)解决的是有监督的分类问题,而非回归问题。
分类问题和回归问题的区别在于输出:分类问题的输出是离散型变量,如判断一个人是否得病,只有两种结果:得病或者不得病;而回归问题的输出为连续型变量,如预测一个人五年后的工资,它就可能是一个实数区间内的任意值。
实际上,logistic回归和多重线性回归除输出的不同外基本类似,这两种回归可以归于同一个家族,即广义线性模型(generalized linear model)。因此这两个回归的模型形式基本差不多,都可以简单表示为:
y
=
Θ
T
X
y=\Theta^TX
y = Θ T X
sigmoid激活函数:
g
(
z
)
=
1
(
1
+
e
(
−
z
)
)
g(z)=\frac{1} {(1+e^{(-z)})}
g ( z ) = ( 1 + e ( − z ) ) 1
g
′
(
z
)
=
1
(
1
+
e
−
z
)
2
∗
(
e
−
z
)
=
1
1
+
e
−
z
∗
(
e
−
z
1
+
e
−
z
)
=
1
1
+
e
−
z
∗
(
1
−
1
1
+
e
−
z
)
=
g
(
z
)
(
1
−
g
(
z
)
)
g'(z)=\frac{1} {(1+e^{-z})^2}*(e^{-z})=\frac{1}{1+e^{-z}}*(\frac{e^{-z}}{1+e^{-z}})=\frac{1}{1+e^{-z}}*(1-\frac{1}{1+e^{-z}})=g(z)(1-g(z))
g ′ ( z ) = ( 1 + e − z ) 2 1 ∗ ( e − z ) = 1 + e − z 1 ∗ ( 1 + e − z e − z ) = 1 + e − z 1 ∗ ( 1 − 1 + e − z 1 ) = g ( z ) ( 1 − g ( z ) )
模型:
h
θ
(
x
)
=
g
(
Θ
x
)
=
1
1
+
e
−
Θ
T
x
h_\theta(x)=g(\Theta x)=\frac{1}{1+e^{-\Theta^{T}x}}
h θ ( x ) = g ( Θ x ) = 1 + e − Θ T x 1
{
P
(
y
=
1
∣
x
,
Θ
)
=
h
θ
(
x
)
P
(
y
=
0
∣
x
,
Θ
)
=
1
−
h
θ
(
x
)
\left\{\begin{matrix} P(y=1|x,\Theta )=h_\theta (x) \\P(y=0|x,\Theta ) =1-h_\theta (x) \end{matrix}\right.
{ P ( y = 1 ∣ x , Θ ) = h θ ( x ) P ( y = 0 ∣ x , Θ ) = 1 − h θ ( x )
可将以上两式进行如下组合:
P
(
y
∣
x
,
Θ
)
=
h
θ
(
x
)
y
(
1
−
h
θ
(
x
)
)
1
−
y
P(y|x,\Theta)=h_\theta(x)^y(1-h_\theta(x))^{1-y}
P ( y ∣ x , Θ ) = h θ ( x ) y ( 1 − h θ ( x ) ) 1 − y
L
(
Θ
)
=
P
(
y
⃗
∣
X
,
Θ
)
=
∏
i
=
1
m
P
(
y
(
i
)
∣
x
(
i
)
,
θ
)
=
∏
i
=
1
m
(
h
θ
(
x
(
i
)
)
)
(
y
(
i
)
)
(
1
−
h
θ
(
x
(
i
)
)
)
1
−
y
(
i
)
L(\Theta)=P(\vec{y}|X,\Theta)=\prod_{i=1}^{m}P(y^{(i)}|x^{(i)},\theta)=\prod_{i=1}^{m}(h_\theta(x^{(i)}))^{(y^{(i)})}(1-h_\theta(x^{(i)}))^{1-y^{(i)}}
L ( Θ ) = P ( y
∣ X , Θ ) = ∏ i = 1 m P ( y ( i ) ∣ x ( i ) , θ ) = ∏ i = 1 m ( h θ ( x ( i ) ) ) ( y ( i ) ) ( 1 − h θ ( x ( i ) ) ) 1 − y ( i )
两边求对数得:
l
o
g
L
(
Θ
)
=
∑
i
=
1
m
y
(
i
)
l
o
g
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
h
θ
(
x
(
i
)
)
)
logL(\Theta)=\sum_{i=1}^{m}y^{(i)}logh_\theta(x^{(i)})+(1-y^{(i)})log(1-h_\theta(x^{(i)}))
l o g L ( Θ ) = ∑ i = 1 m y ( i ) l o g h θ ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) )
d
l
o
g
L
(
Θ
)
d
θ
j
=
(
y
1
h
θ
(
x
)
−
(
1
−
y
)
1
1
−
h
θ
(
x
)
)
d
d
θ
j
h
θ
(
x
)
\frac{\mathrm{d} logL(\Theta )}{\mathrm{d} \theta _j}=(y\frac{1}{h_\theta(x)}-(1-y)\frac{1}{1-h_\theta(x)})\frac{\mathrm{d} }{\mathrm{d} \theta _j}h_\theta(x)
d θ j d l o g L ( Θ ) = ( y h θ ( x ) 1 − ( 1 − y ) 1 − h θ ( x ) 1 ) d θ j d h θ ( x )
将
h
θ
(
x
)
=
g
(
Θ
T
x
)
h_\theta(x)=g(\Theta^Tx)
h θ ( x ) = g ( Θ T x )
d
l
o
g
L
(
Θ
)
d
θ
j
=
(
y
1
h
θ
(
x
)
−
(
1
−
y
)
1
1
−
h
θ
(
x
)
)
d
d
θ
j
h
θ
(
x
)
=
(
y
1
g
(
θ
T
x
)
−
(
1
−
y
)
1
1
−
g
(
θ
T
x
)
)
d
d
θ
j
g
(
θ
T
x
)
\frac{\mathrm{d} logL(\Theta )}{\mathrm{d} \theta _j}=(y\frac{1}{h_\theta(x)}-(1-y)\frac{1}{1-h_\theta(x)})\frac{\mathrm{d} }{\mathrm{d} \theta _j}h_\theta(x)=(y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)})\frac{\mathrm{d} }{\mathrm{d} \theta _j}g(\theta^Tx)
d θ j d l o g L ( Θ ) = ( y h θ ( x ) 1 − ( 1 − y ) 1 − h θ ( x ) 1 ) d θ j d h θ ( x ) = ( y g ( θ T x ) 1 − ( 1 − y ) 1 − g ( θ T x ) 1 ) d θ j d g ( θ T x )
因为
g
′
(
z
)
=
g
(
z
)
(
1
−
g
(
z
)
)
g'(z)=g(z)(1-g(z))
g ′ ( z ) = g ( z ) ( 1 − g ( z ) )
d
l
o
g
L
(
Θ
)
d
θ
j
=
(
y
1
g
(
θ
T
x
)
−
(
1
−
y
)
1
1
−
g
(
θ
T
x
)
)
g
(
θ
T
x
)
(
1
−
g
(
θ
T
x
)
)
d
d
θ
j
θ
T
x
\frac{\mathrm{d} logL(\Theta )}{\mathrm{d} \theta _j}=(y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)})g(\theta^Tx)(1-g(\theta^Tx))\frac{\mathrm{d} }{\mathrm{d} \theta _j}\theta^Tx
d θ j d l o g L ( Θ ) = ( y g ( θ T x ) 1 − ( 1 − y ) 1 − g ( θ T x ) 1 ) g ( θ T x ) ( 1 − g ( θ T x ) ) d θ j d θ T x
d
d
θ
j
θ
T
x
=
x
j
\frac{\mathrm{d} }{\mathrm{d} \theta _j}\theta^Tx=x_j
d θ j d θ T x = x j
所以:
d
l
o
g
L
(
Θ
)
d
θ
j
=
[
y
(
1
−
g
(
θ
T
x
)
)
−
(
1
−
y
)
g
(
θ
T
x
)
]
x
j
=
[
y
−
y
g
(
θ
T
x
)
−
g
(
θ
T
x
)
+
y
g
(
θ
T
x
)
]
x
j
\frac{\mathrm{d} logL(\Theta )}{\mathrm{d} \theta _j}=\left [ y(1-g(\theta^Tx))-(1-y)g(\theta^Tx) \right ]x_j=\left [ y-yg(\theta^Tx)-g(\theta^Tx)+yg(\theta^Tx) \right ]x_j
d θ j d l o g L ( Θ ) = [ y ( 1 − g ( θ T x ) ) − ( 1 − y ) g ( θ T x ) ] x j = [ y − y g ( θ T x ) − g ( θ T x ) + y g ( θ T x ) ] x j
d
l
o
g
L
(
Θ
)
d
θ
j
=
(
y
−
g
(
θ
T
x
)
)
x
j
=
(
y
−
h
θ
(
x
)
)
x
j
\frac{\mathrm{d} logL(\Theta )}{\mathrm{d} \theta _j}=(y-g(\theta^Tx))x_j=(y-h_\theta(x))x_j
d θ j d l o g L ( Θ ) = ( y − g ( θ T x ) ) x j = ( y − h θ ( x ) ) x j
θ
=
θ
−
λ
Δ
\theta=\theta-\lambda\Delta
θ = θ − λ Δ
λ
\lambda
λ
Δ
\Delta
Δ
因此对
θ
j
\theta_j
θ j
θ
j
\theta_j
θ j
θ
j
−
λ
(
g
(
θ
T
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
=
θ
j
−
λ
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\theta_j-\lambda(g(\theta^Tx^{(i)})-y^{(i)})x_{j}^{(i)}=\theta_j-\lambda(h_\theta(x^{(i)})-y^{(i)})x_{j}^{(i)}
θ j − λ ( g ( θ T x ( i ) ) − y ( i ) ) x j ( i ) = θ j − λ ( h θ ( x ( i ) ) − y ( i ) ) x j ( i )
至此,我们完成了逻辑回归的梯度下降算法的全部推导过程。