HA集群的搭建可以在完全分布式的基础上搭建
目的:
减少单点故障的发生
规划配置图
| NN1 | NN2 | DN | zK | ZKFC | JNN | RM | |
|---|---|---|---|---|---|---|---|
| hadoop100 | * | * | * | * | * | * | |
| hadoop101 | * | * | * | * | * | * | |
| hadoop102 | * | * | * |
图中的 NN、DN、ZK、ZKFC、JNN、RM是以下简称
NN: NameNode
DN:DataNode
ZK:Zookeeper
ZKFC:Zookeeper客户端
JNN:Journalnode
RM:Resourcemanager
准备工作:
1、配置时间同步服务器(可选操作)
所有节点都执行
yum -y install ntp
ntpdate ntp1.aliyun.com
2、配置好各个主机的映射(不懂自行百度解决)
3、免密登录
所有节点都执行
ssh-keygen-t rsa //生成密钥 中途停下询问的一直按回车到执行成功为止
ssh-copy-id hadoop101 //发送公钥到其他节点上
4、设置关闭防火墙
systemctl stop firewalld.service //暂时关闭
systemctl disable firewalld.service //永久关闭
正式开始搭建Hadoop集群的高可用
安装jdk(如果是最小化安装Centos的默认是没有jdk的直接安装解压就好,图形化安装的需要卸载原来的jdk才能安装)
解压hadoop安装包
tar xf hadoop2.7.7... -C /module/ha/
进入hadoop的配置文件目录
cd /module/ha/hadoop/etc/hadoop
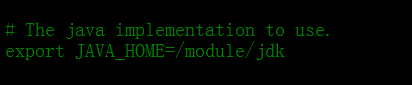
三个 (hadoop、yarn、mapred) -env.sh的文件,找到JAVA_HOME 设置jdk的安装路径
配置core-site.xml
vi core-site.xml
<!-- 设置hdfs的nameservice服务 名称自定义 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 设置hadoop的元数据存放路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/moudle/ha/hadoop/data</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop100:2181,hadoop101:2181,hadoop102:2181</value>
</property>
vi hdfs-site.xml
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop100:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop101:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop100:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop101:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop100:8485;hadoop101:8485;hadoop102:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/module/ha/hadoop/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--设置开启HA故障自动转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置mapred-site.xml
vi mapred-site.xml
增加以下配置
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置yarn-site.xml(可选配置)
vi yarn-site.xml
增加以下配置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop100</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop101</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop100:2181,hadoop101:2181,hadoop102:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
配置slaves
vi slaves
hadoop100
hadoop101
hadoop102
配置完了分发到所有的节点上
scp –r -p /usr/local/hadoop/ root@master2:/usr/local/
Zookeeper安装
解压文件
tar xf 文件名 -C 存放路径
自行好配置环境变量
修改conf目录下的zoo_sample.cfg
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
设置zk的存放元数据存放的路径
dataDir=/module/zookeeper/zk
在文件最下面增加以下数据
Server.1=hadoop100:2888:3888
Server.2=hadoop101:2888:3888
Server.3=hadoop102:2888:3888
修改zookeeper生成logs的位置可以不修改
vi bin/zkEnv.sh

修改第二个箭头指向的路径到自已想存放的地方
创建出zk的存放元数据存放路径的文件
mkdir /module/zookeeper/zk
分发zookeeper文件到所有配置zookeeper的节点上
在不同节点写入对应的id
echo 1 > /module/zookeeper/zk/myid # hadoop100节点上:
在ZooKeeper集群的每个节点上,执行启动ZooKeeper服务的脚本
zkServer.sh start
部署细节
1、必须先启动journalnode
hadoop-daemons.sh start journalnode
2、选择其中的一台是配置NN的节点上执行hadoop格式化
bin/hdfs namenode –format
3、选择一台NN启动namenode
sbin/hadoop-daemon.sh start namenode
4、在另一台NN节点上执行数据同步
bin/hdfs namenode -bootstrapStandby
5、在其中的一台NN上执行zkfc格式化
bin/hdfs zkfc –formatZK
在其中NN上启动hadoop集群
sbin/start-dfs.sh
使用jps命令查看各个节点上是否有以下节点
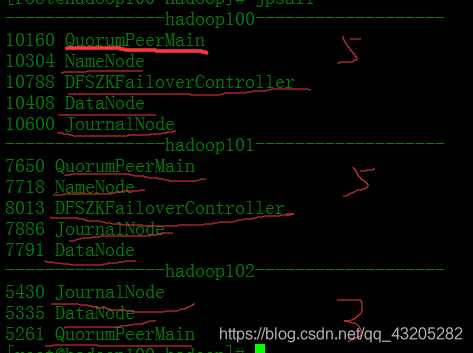
至此hadoop的HA集群完成!!!!
开启的RM的HA 在配置有RM节点上执行
sbin/start-yarn.sh
在另一台配置也有RM的节点上执行
sbin/yarn-daemon.sh start resourcemanager
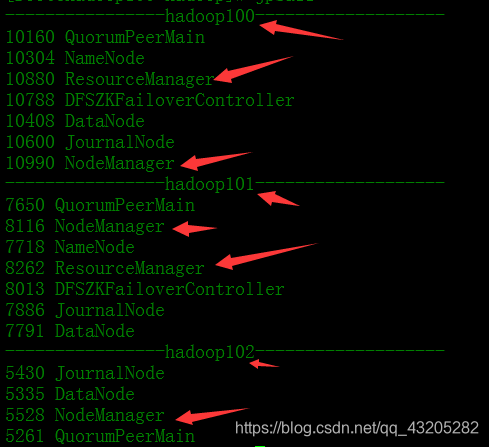
查看所有节点有以下节点至此 RM的HA集群配置成功!!!!!!
常用的命令 NameNode进程启动:hadoop-daemon.sh start namenode
DataNode进程启动:hadoop-daemon.sh start datanodeHA高可用环境中需要启动的进程: zookeeper: zkServer.sh start 启动 zkServer.sh stop 停止
zkServer.sh status 查看状态 leader follwerjournalnode集群命令 hadoop-daemon.sh start journalnode 启动 hadoop-daemon.sh
stop journalnode 停止ZKFC 格式化:hdfs zkfc -formatZK 启动zkfc进程: hadoop-daemon.sh start zkfc
停止zkfc进程: hadoop-daemon.sh stop zkfcNameNode数据同步命名:hdfs namenode -bootstrapStandby
启动yarn的进程:
yarn-daemon.sh start resourcemanager
模拟故障转移自动切换主备NN状态
- 使用jps查看namenode进程id
jps
- 停止namenode进程
kill -9 namenode的进程id
然后查看两个namenode的web页面查看状态是否切换过来
3. 重新启动namenode进程:
hadoop-daemon.sh start namenode
