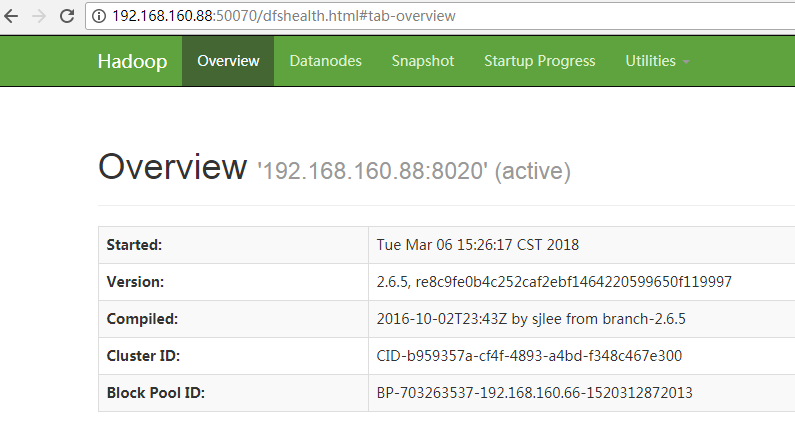
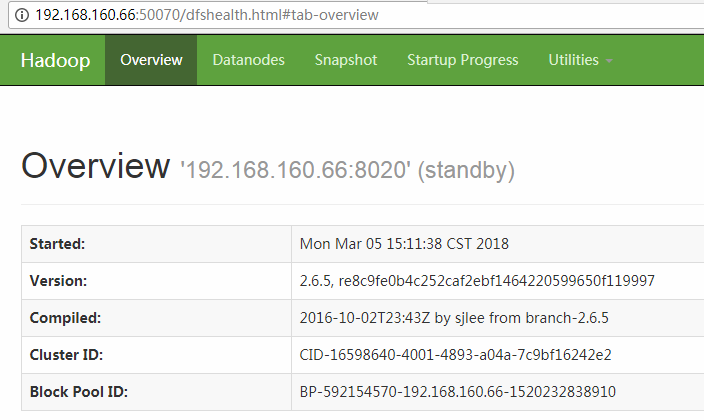
hdfs的NameNode节点用来保存元数据信息,一旦宕机,则集群不可恢复。因此需要高可用,在hadoop2.x以后,可以支持NameNode的高可用。hadoop3.x则支持一主多从。
hadoop2.x的高可用有一个缺点,就是数据节点的心跳需要向NameNode集群的每个节点发送,这样比较占用资源,因此NameNode节点并不是越多越好
一、架构
先来看一下架构图
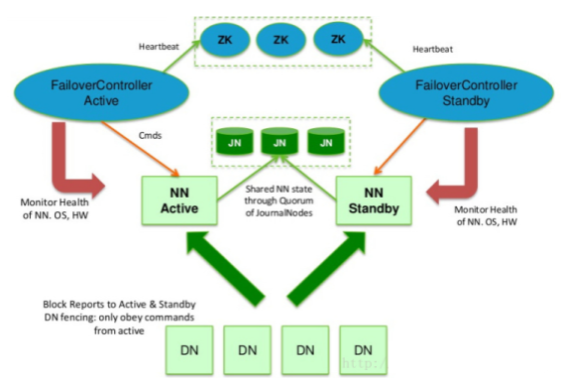
其中JN为JournalNode,共享元数据,Activie NameNode更新元数据后,存到JournalNode,Standby NameNode通过JournalNode获取到更新的元数据。
Active NameNode为主要工作的NameNode
Standby NameNode相当于备份的NameNode
DataNode向两个NameNode发送心跳,上传位置信息
FailoverController为执行元数据拷贝的线程
zk 为zookeeper集群
注意: JournalNode,Zookeeper必须为单数节点个数,从而防止脑裂
二、搭建
搭建之前,最好能先了解完全分布式的搭建,这里共同的东西就不再赘述了
这里搭建的节点分布如下

1、linux服务器时间同步
略
2、JDK的安装
略
3、ssh免密码登录配置
略
4、修改etc/hadoop/hadoop-env.sh文件
略
5、修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>192.168.160.66:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>192.168.160.88:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>192.168.160.66:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>192.168.160.88:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.160.66:8485;192.168.160.88:8485;192.168.160.166:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>6、修改core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/ha</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.160.88:2181,192.168.160.166:2181,192.168.160.188:2181</value>
</property>
</configuration>
7、删除masters文件
8、安装Zookeeper集群
9、启动zookeeper集群
10、启动JournalNode集群
11、格式化hdfs
在其中一个NameNode上运行hadoop-daemon.sh start journalnode命令
12、启动第一台nameNode
hadoop-daemon.sh start namenode
13、启动另一台nameNode
hdfs namenode -bootstrapStandby
这个时候,namenode的元数据信息同步完成
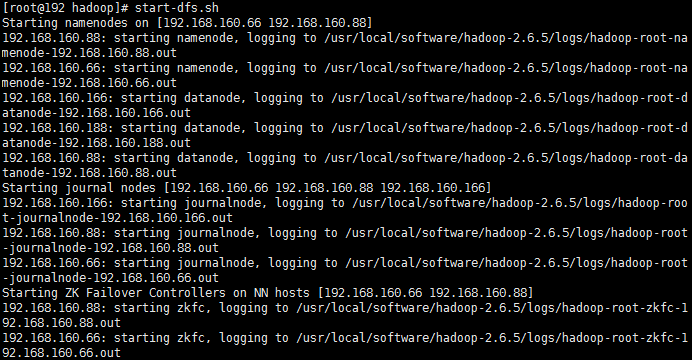
14、启动hdfs
运行start-dfs.sh命令
15、格式化zookeeper
hdfs zkfc -formatZK
16、重启hdfs并且开启选举
stop-dfs.sh && start-dfs.sh || hadoop-daemon.sh start zkfc