基于短时时域处理中短时能量和过零率的语音端点检测方法
1.背景
在语音信号处理中检测出语音的端点是相当重要的。语音端点的检测是指从包含语音的一段信号中确定的起始点和结束点位置,因为在某些语音特性检测和处理中,只对有话段检测或处理。例如,在语音减噪和增强中,对有话段和无话段可能采取不同的处理方法;在语音识别和语音编码中同样有类似的处理。
处理没有噪声的情况下的语音端点检测,用短时平均能量就可以检测出语音的端点。但实际处理语音往往处于复杂的噪声环境中,这时,判别语音段的起始点和终止点的问题主要归结为区别语音和噪声的问题。
所以本项目实现的是短时平均能量和短时平均过零率的方法,同时简单介绍在低信噪比条件下端点的检测。
2.主要内容
2.1、画出“f.m4a”和“b.m4a”的语音信号波形和它的短时能量图
2.2、画出“f.m4a”和“b.m4a”的语音信号波形和它的短时平均零交叉率图
2.3、利用2.2和2.3短时能量和短时平均零交叉率进行端点检测两级判决法示意图。
3.具体实验内容
3.1短时能量
设语音波形时域信号为x(n),加窗函数w(n),分帧处理后得到的第i帧语音信号为yi(n),则yi(n)满足:
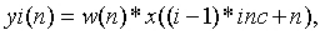
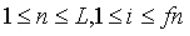
式中,w(n)为窗函数,一般为矩形窗或汉明窗;yi(n)是一帧的数值,n=1,2,…,L, i=1,2,…,fn,L为帧长;inc为帧移长度;fn为分帧后的总帧数。
计算第i帧语音信号yi(n)的短时能量公式为:
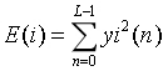
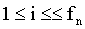
这里给出核心代码解释:
% 所用到的函数
% function frameTime=frame2time(frameNum,framelen,inc,fs)
% 分帧后计算每帧对应的时间
% frameTime=(((1:frameNum)-1)*inc+framelen/2)/fs;
% end
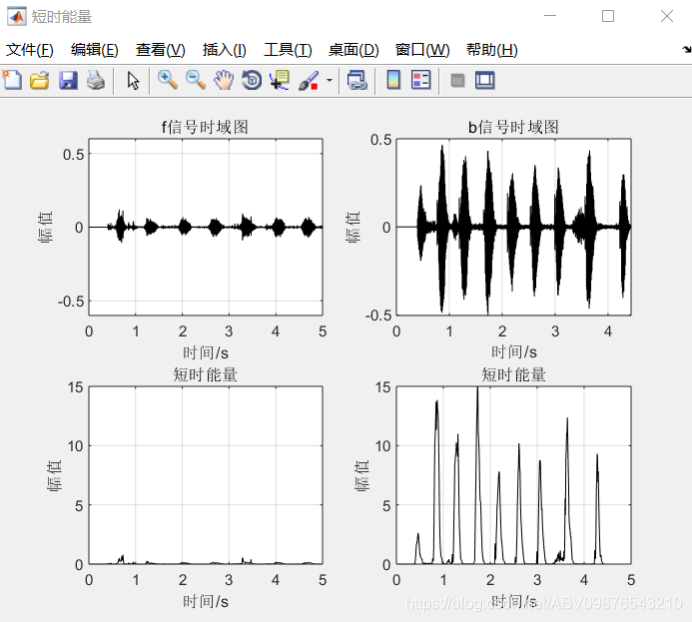
%f和b的时域图与短时能量图
clear all;
[x,fs]=audioread('..\input\语音数据\f.m4a'); %读取音频
x=x(:,1); %提取一个通道
wlen=960; %设置窗长
win=hanning(wlen); %设置海宁窗
inc=400; %设置帧移
lx=length(x);
xf=enframe(x,win,inc)'; %分帧、加海宁窗
fnx=size(xf,2); %帧数
tx=(0:lx-1)/fs;
frametimex=frame2time(fnx,wlen,inc,fs);
for i=1:fnx
xf1=xf(:,i);
xe=xf1.*xf1;
Enx(i)=sum(xe);
end
结果展示:
3.2平均幅度
语音信号的平均幅度定义为
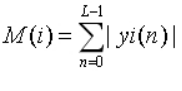
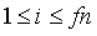
M(i)也是一帧信号能量大小的表征,它与E(i)的区别在于计算时不论采样值的大小,不会因取二次方而造成较大的差异,在某些领域中会带来一些好处。
短时能量和短时平均幅度函数的主要用途有:区分浊音段和轻音段,因为浊音时E(i)值比轻音时大得多;区分声母和韵母的分界和无话段与有话段的分界。
3.3短时平均过零率
短时平均过零率表示一帧语音中语音信号波形穿过横轴(零点)的次数。对于连续语音信号,过零即意味着时域波形通过时间轴;而对于离散信号,如果相邻的取样值改变符号,则称为过零。短时平均过零率就是样本数值改变符号的次数。
短时平均过零率为 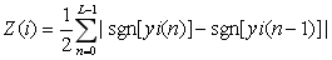
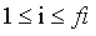
式中,sgn[]是符号函数,即
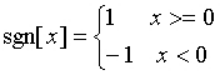
在实际计算短时平均过零率时,需要十分注意的一个问题是,如果输入信号中包含漂移,即信号在通往AD转换器前就有个直流分量,使AD转换后继续带有这个直流分量。因为直流分量的存在影响了短时平均过零率的正确估算,所以建议在语音信号处理前先消除直流分量。
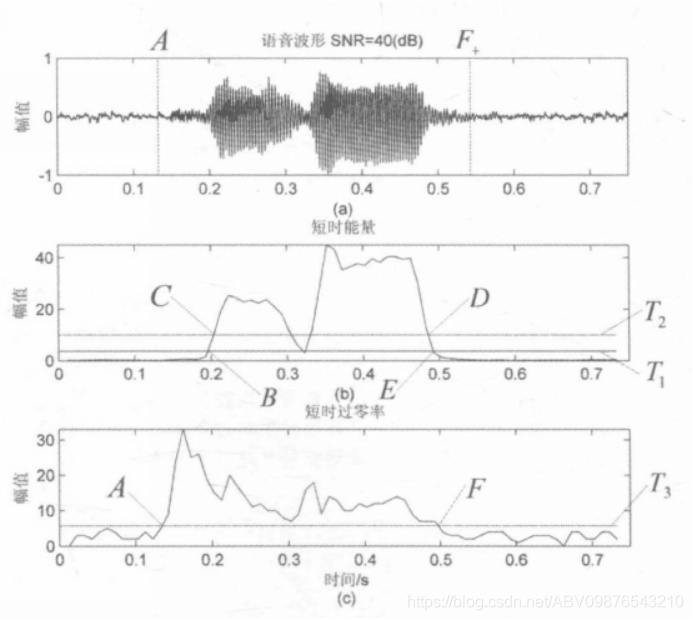
理论上短时平均过零率是按上式计算,而在MATLAB编程中,却用另一种方法 。按上述过零的描述,即离散信号相邻的取样值改变符号,那它们的乘积一定为负数,即:
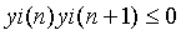
这里给出核心代码解释:
[x,fs]=audioread('G:\语音处理项目\语音处理大作业\语音数据\f.m4a');
x=x(:,1);
wlen=960;
win=hanning(wlen);
inc=400;
xx=x-mean(x);
lxx=length(xx);
txx=(0:lxx-1)/fs;
xxf=enframe(xx,win,inc)';
fnxx=size(xxf,2);
zcrx=zeros(1,fnxx);
for i=1:fnxx
xxf1=xxf(:,i);
for j=1:(wlen-1)
if xxf1(j)*xxf1(j+1)<0
zcrx(i)=zcrx(i)+1;
end
end
end
结果展示:
3.4语音端点检测原理
双门限法
双门限法最初是基于短时平均能量和短时平均过零率而提出的,其原理是汉语的韵母中 有元音,能量较大,所以可以从短时平均能量中找到韵母,而声母是辅音,它们的频率较高,相应的短时平均过零率较大,所以用这两个特点找出声母和韵母,等于找出完整的汉语音节。双门限法是使用二级判决来实现的。
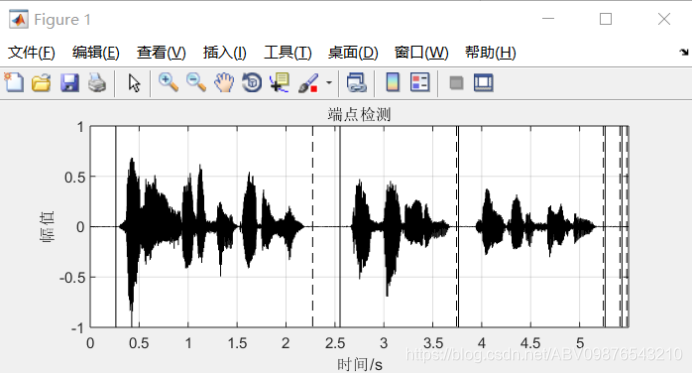
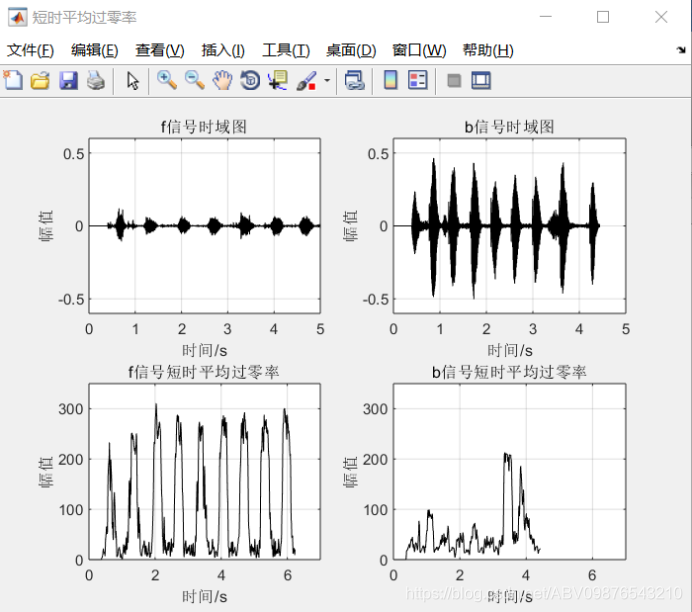
以上图为例,图(a)是语音的波形,图(b)是该语音的短时平均能量,图(c)是该语音的短时平均过零率。进行判决的具体步骤如下:
1.第一级判决
①根据在语音短时能量包络线上选取的一个较高阈值(门限)T2 (图中以虚水平线表示) 进行一次粗判,就是高于该T2阈值肯定是语音(即在CD段之间肯定是语音),而语音起止点应位于该阈值与短时能量包络交点所对应的时间点之外(即在CD段之外)。
②在平均能量上确定一个较低的阈值(门限)(图中以实水平线表示),并从C点往左、从D点往右搜索,分别找到短时能量包络与阈值T1相交的两个点B和E,于是BE段就是用双门限法根据短时能量所判定的语音段的起止点位置。
2.第二级判决
以短时平均过零率为准,从B点往左和从E点往右搜索,找到短时平均过零率低于某个阈值(门限)T3的两点A和F (图中T3以水平虚线表示),这便是语音段的起止点。
根据这两级判决,求出了语音的起始点位置A和结束点位置F。但考虑到语音发音时单 词之间的静音区会有一个最小长度表示发音间的停顿,就是在小于阈值T3满足这样一个最小长度后才判断为该语音段结束,实际上相当于延长了语音尾音的长度,如图中在语音波形图上标出语音的起止点分别为A和F+(从图中看出终止点位置为F,而实际处理中延长到 F+)。
在端点检测的具体运行中,首先是对语音分帧(实验二已做过介绍),在分帧基础上方能求出短时平均能量和短时平均过零率,然后逐帧地依阈值进行比较和判断。
这里给出几个核心函数代码:
function frameTime=frame2time(frameNum,framelen,inc,fs)
% 分帧后计算每帧对应的时间
frameTime=(((1:frameNum)-1)*inc+framelen/2)/fs;
function [voiceseg,vsl,SF,NF]=vad_ezm1(x,wlen,inc,NIS)
x=x(:); % 把x转换成列数组
maxsilence = 15; % 初始化
minlen = 5;
status = 0;
count = 0;
silence = 0;
y=enframe(x,wlen,inc)'; % 分帧
fn=size(y,2); % 帧数
amp=sum(y.^2); % 求取短时平均能量
zcr=zc2(y,fn); % 计算短时平均过零率
ampth=mean(amp(1:NIS)); % 计算初始无话段区间能量和过零率的平均值
zcrth=mean(zcr(1:NIS));
amp2=2*ampth; amp1=4*ampth; % 设置能量和过零率的阈值
zcr2=2*zcrth;
%开始端点检测
xn=1;
for n=1:fn
switch status
case {0,1} % 0 = 静音, 1 = 可能开始
if amp(n) > amp1 % 确信进入语音段
x1(xn) = max(n-count(xn)-1,1);
status = 2;
silence(xn) = 0;
count(xn) = count(xn) + 1;
elseif amp(n) > amp2 | ... % 可能处于语音段
zcr(n) > zcr2
status = 1;
count(xn) = count(xn) + 1;
else % 静音状态
status = 0;
count(xn) = 0;
x1(xn)=0;
x2(xn)=0;
end
case 2, % 2 = 语音段
if amp(n) > amp2 & ... % 保持在语音段
zcr(n) > zcr2
count(xn) = count(xn) + 1;
silence(xn) = 0;
else % 语音将结束
silence(xn) = silence(xn)+1;
if silence(xn) < maxsilence % 静音还不够长,语音尚未结束
count(xn) = count(xn) + 1;
elseif count(xn) < minlen % 语音长度太短,认为是静音或噪声
status = 0;
silence(xn) = 0;
count(xn) = 0;
else % 语音结束
status = 3;
x2(xn)=x1(xn)+count(xn);
end
end
case 3, % 语音结束,为下一个语音准备
status = 0;
xn=xn+1;
count(xn) = 0;
silence(xn)=0;
x1(xn)=0;
x2(xn)=0;
end
end
el=length(x1);
if x1(el)==0, el=el-1; end % 获得x1的实际长度
if x2(el)==0 % 如果x2最后一个值为0,对它设置为fn
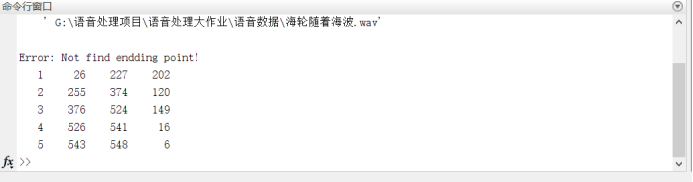
fprintf('Error: Not find endding point!\n');
x2(el)=fn;
end
SF=zeros(1,fn); % 按x1和x2,对SF和NF赋值
NF=ones(1,fn);
for i=1 : el
SF(x1(i):x2(i))=1;
NF(x1(i):x2(i))=0;
end
speechIndex=find(SF==1); % 计算voiceseg
voiceseg=findSegment(speechIndex);
vsl=length(voiceseg);
function zcr=zc2(y,fn)
if size(y,2)~=fn, y=y'; end
wlen=size(y,1); % 设置帧长
zcr=zeros(1,fn); % 初始化
delta=0.01; % 设置一个很小的阈值
for i=1:fn
yn=y(:,i); % 取来一帧
for k=1 : wlen % 中心截幅处理
if yn(k)>=delta
ym(k)=yn(k)-delta;
elseif yn(k)<-delta
ym(k)=yn(k)+delta;
else
ym(k)=0;
end
end
zcr(i)=sum(ym(1:end-1).*ym(2:end)<0); % 取得处理后的一帧数据寻找过零率
end
注:
① 输入参数:x是语音信号的序列,为了要分帧,设置帧长为wlen和帧移为inc,NIS是前导无话段的帧数。
② 在语音处理中为了能估算噪声的情况,往往在一段语音的前部有一段前导无话语段,在以后会有不少程序利用该段前导无话语段来估算噪声的特性。在实际,有时可能不知道前导无语段的帧数,但从语音信号的波形图中可以估算出前导无话段的时长IS(单位为s),有了IS就能计算出前导无语段的帧数NIS:

③ 为了保证过零率计算的稳定,排除信号可能会有的一些微小的零漂移,所以当输入加窗分帧后的语音信号xi(m)时,做中心截幅处理(或称过门限率),得
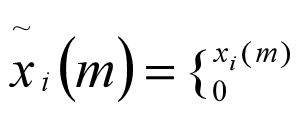
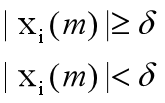
式中,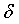 是个很小的值。
是个很小的值。
中心截幅处理后再计算每一帧的过零率: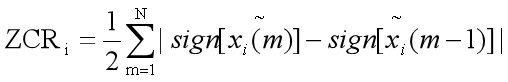
式中
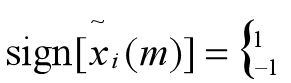
④ 先对前导无话语段计算噪声短时平均能量和短时平均过零率:

再在这两值的基础上设置能量的两个阈值amp2(T1)和amp(T2),以及过零点的阈值zcr2(T3):
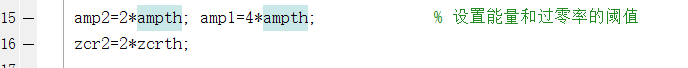
在这里阈值不是一个固定的值,将会随着前导话语段计算噪声的情况 动态地变动。有了阈值以后就能按双门限法进行检测了。
⑤ 在函数中的maxsilence(表示一段语音结束时静音区的最小长度),minlen(表示有话语段的最小长度)参数就和语速有关。所以这些参数可以改变,可以按实际情况进行调整。
结果展示:
例一:
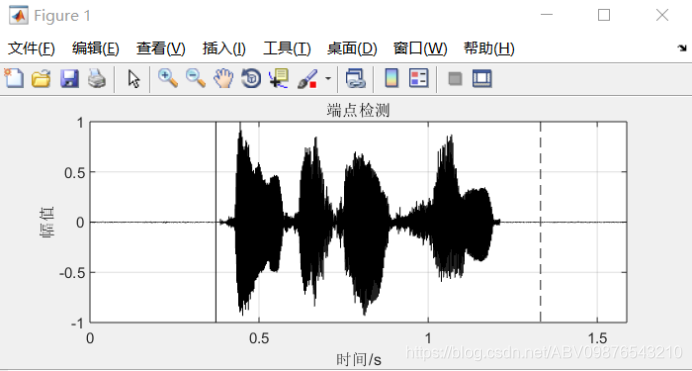

例二: