什么是概率图模型
概率图模型是概率论与图论相结合的产物,为统计推理和学习提供了一个统一的灵活框架。概率图模型提供了一个描述框架,使我们能够将不同领域的知识抽象为概率模型,将各种应用中的问题都归结为计算概率模型里某些变量的概率分布,从而将知识表示和推理分离开来。
利用图模型进行实际问题求解的时候包括两步:
- 知识表示,概率图模型的表示建模;
- 将实际问题转化为一个推理的问题。
这样就把知识表示和推理分离开来了。
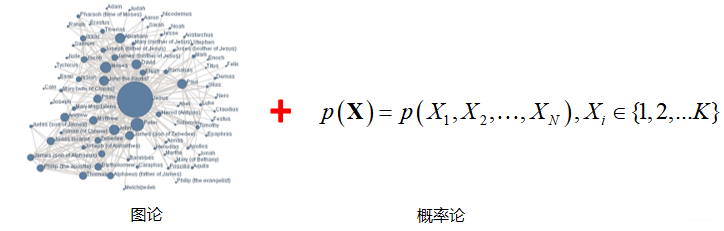
上图中的左图是一个图,图中含有节点,有边,每一个节点表示我们所研究问题的一个变量,变量之间的边表示:变量局部的依赖关系。右边所表示的是系统的联合概率分布,这个问题包含 维变量,每个变量包含 个可能的取值。概率图模型就是在这样一个图上定义一个联合概率分布,建模完成以后再在这个概率图模型上进行推理计算。从而解决一些实际的应用问题。
概率图模型用节点表示变量,节点之间的边表示局部变量间的概率依赖关系。在概率图模型的表示框架下,系统的联合概率分布表示为局部变量势函数的连乘积,该表示框架不仅避免了对复杂系统的联合概率分布直接进行建模,而且易于在图模型建模中引入先验知识。
2012年图灵奖颁给UCLA的Judea Pearl教授,奖励其在贝叶斯网络上的开创性工作,贝叶斯网络属于有向的概率图模型。消息传递是概率图模型中消息传递的一种比较创新的机制。通过消息传递可以把全局的概率推理转化为图上的局部变量之间的消息传递。能够大大降低推理的复杂度。

概率图模型统一了目前广泛应用的许多统计模型和方法。比如:
- 马尔可夫随机场 (
MRF)一种无向的概率图模型,在图像处理,统计物理学上有非常广泛的应用。 - 条件随机场(
CRF),可以应用于NLP(自然语言处理) - 隐马尔可夫模型(
HMM) - 多元高斯模型
Kalman滤波、粒子滤波、变分推理
这些不同的统计模型和方法都可以纳入到概率图模型这个统一的框架里面。也就是说上述的方法是特殊的概率图模型,都可以归纳到概率图模型的大类里面。
概率图模型举例:
贝叶斯网

贝叶斯网络(Bayesian network)又称信度网络(belief network),是Bayes方法的扩展,是目前不确定知识表达和推理领域最有效的理论模型之一。
如上图所示,每一个节点表示一个变量,变量可以是任何问题的抽象,如:测试值,观测现象,意见征询等。变量之间的边用有向的箭头连接,贝叶斯网络是一个有向无环图(Directed Acyclic Graph,DAG),所以贝叶斯网络是一种有向的概率图模型。贝叶斯网络中可以定义一个联合概率分布,具体表示为每个节点的条件概率连乘积的形式:
适用于表达和分析不确定性和概率性的事件,应用于有条件地依赖多种控制因素的决策,可以从不完全、不精确或不确定的知识或信息中做出推理。
机器学习里面有两派,一派是频率派、一派是贝叶斯派。在频率派中参数是多少就是多少,而在贝叶斯派中觉得所有的数值都是随机变量,按照某一个概率出现。图模型、无监督算法更多地关心的是参数的估计,也就是贝叶斯派的思想。
在数据科学中的核心问题就是利用已知数据建立一个模型或者说是一种分布,然后去预测一些东西。那现在的问题就是如何去建立这样一个模型。数据建模过程中的难点在于如何在数据维度分布很高的情况下获取数据之间模型的关系。
比如说你想要去建模一个明天什么天气下穿什么衣服的模型 ,它会等于明天温度为冷热的概率 和在这个温度下,穿什么衣服的条件概率 的乘积。
我们有两种办法来做一种是有向(directed graphs)的贝叶斯网络(Bayesian network),另一种是无向(undirected graphs)的马尔可夫网络(Markov network)。
- 贝叶斯网络:
- 马尔可夫网络:
Bayesian Network
一个简单的贝叶斯网络可表示为如下形式:

其联合概率分布可表示为:
对于稍微复杂一点的网络,其结构可表示为:

如果直接建模的话,七个变量直接乘在一起,建模空间比较大,而使用贝叶斯网络的话,数据的联合概率分布可表示为:
建模空间缩小了。其实上述公式也非常好理解,你只需要注意箭头指向的方向,就会很容易发现其中的规律。
举例
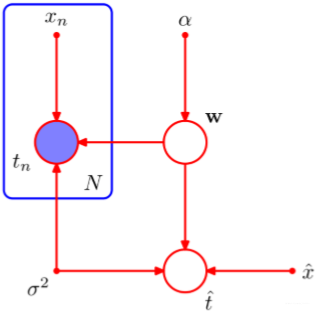
假设我们现在有一些训练数据
,
是data,t是label。假设建立一个带有参数
的模型,这个参数服从某个高斯分布。有:
给定超参数
,可以得到
,得到
之后,对于任意一个
我都能得到一个label
的概率,也就是可以通过Gaussian可以采出来一个
,并且这个高斯的分布也是不确定的。也可以表示为:
用图形化的语言可表示为如下形式:

由于 到 其实是一类性质。图形化语言可简画为如下形式:

预测的标签是一组随机变量,依据真实标签(数据),likelihood后验概率分布可以得到。其后验概率(Posterior Distribution)
可表示为:
由于 是真实标签,其概率不变,上式正比于:
也就是等于先验分布
与Data likelihood的乘积。

由此问题转变为最大化后验概率分布估计的问题:
将其展开,代入高斯函数,可以得到:
对其取log,得到:
等价于:
它与带有均方误差的回归问题是等价的。上述过程是模型的求解过程,对于新的数据,如何做推断呢?给定先验和数据的likelihood,可以得到
,之后再得到新的数据的预测标签。
Marginalize out the coefficients (也就是最开始不考虑 ):
马尔可夫随机场
马尔可夫随机场(Markov Random Field)

马尔可夫随机场是一种无向的概率图模型,这个无向的概率图模型上的联合概率分布可以表示成节点势函数和边上的势函数连乘积的形式。
马尔可夫随机场是建立在马尔可夫模型和贝叶斯理论基础之上的,它包含两层意思:一是什么是马尔可夫,二是什么是随机场。
马尔可夫性质:它指的是一个随机变量序列按时间先后关系依次排开的时候,第N+1时刻的分布特性,与N时刻以前的随机变量的取值无关。拿天气来打个比方。如果我们假定天气是马尔可夫的,其意思就是我们假设今天的天气仅仅与昨天的天气存在概率上的关联,而与前天及前天以前的天气没有关系。其它如传染病和谣言的传播规律,就是马尔可夫的。
随机场:当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。我们不妨拿种地来打个比方。其中有两个概念:位置(site),相空间(phase space)。“位置”好比是一亩亩农田;“相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
马尔可夫随机场:马尔科夫随机场是具有马尔科夫特性的随机拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
马尔可夫网络 (Markov Networks) 与贝叶斯网络的区别在于它是无向网络(Undirected network),也就是没有箭头,任何两个变量之间并没有谁导致谁这样的假设。

如上图所示A、B这两个节点会条件独立于C这样子。一个节点是由它周围的这些节点所影响的。在这种情况下,用数学形式描述两个节点
和
条件独立的话,可表示为:
马尔可夫网络( Markov Networks)举例

上图中的马尔可夫网络有四个节点{
},五个两个节点的cliques:{
},{
},{
},{
},{
}。有两个最大的cliques:{
},{
}。
其中
是Potential function势函数:
是partition function,是归一化因子
。势函数的定义可由domain knowledge来辅助定义。
基于能量的势函数
最简单的一种势函数定义:Energy Function for Potential。势函数可以被取值为负的能量函数(势能越高,能量越小)。
被称为能量函数。基于上述定义
的分布也叫做玻尔兹曼分布( Boltzmann distribution)。
因子图
将一个具有多变量的全局函数因子分解,得到几个局部函数的乘积,以此为基础得到的一个双向图叫做因子图。在概率论及其应用中, 因子图是一个在贝叶斯推理中得到广泛应用的模型。

因子图和之前两类图模型有一定的区别,因子图中包含两类节点,第一类是下图所示的圆圈节点,代表的是一个变量,第二个是下图所示的方块,代表图模型的因子。变量和因子之间的连线表示这个因子包含的变量有哪些。在因子图中因子的联合概率分布可以表示为变量的连乘积的形式。
概率图模型发展历程
-
历史上,曾经有来自不同学科的学者尝试使用图的形式表示高维分布的变量间的依赖关系 。
-
在人工智能领域,概率方法始于构造专家系统的早期尝试 。
-
到 20 世纪 80 年代末,在贝叶斯网络和一般的概率图模型中的推理取得重要进展。
1988年,人工智能领域著名学者Pearl提出了信念传播(Belief Propagation, BP)算法(与深度学习中的反向传播算法是完全不同的算法),BP算法是一种推理算法,把全局的概率推理过程转变为局部变量间的消息传递,从而大大降低了推理的复杂度。 -
BP算法引起了国际上学者的广泛关注,掀起了研究的热潮。 -
前面的BP算法是在树状的图模型上才能取得精确的结果, 在一般的有环的图模型上是近似的,而且收敛性无法得到保证,针对这个问题,
2003年,Wainwright等人提出了树重置权重信度传播(tree-reweighted belief propagation)算法,其主要思想是将一个有环概率图模型分解为若干生成树的加权和,从而将原复杂的推理问题转化为若干树状图模型的推理问题。 -
2008年,Globerson和Sontag等人提出了基于线性规划松弛和对偶分解的推理算法。这个算法的意义在于把一个推理问题转化为一个优化问题。而且之前的许多推理问题都能够纳入到这个框架里面。 -
如今,经过近
30余年的发展,概率图模型的推断和学习已广泛应用于机器学习、计算机视觉、自然语言处理、医学图像处理、计算神经学、生物信息学等研究领域,成为人工智能相关研究中不可或缺的一门技术。
概率图模型的表示、推理、学习
概率图模型理论中有三大要素,表示、推理和学习。
概率图模型的表示
概率图模型的表示刻画了模型的随机变量在变量层面的依赖关系,反映出问题的概率结构,为推理算法提供了数据结构。概率图模型的表示方法主要有贝叶斯网络、马尔科夫随机场、因子图这三大类。
概率图模型的表示主要解决的是如何在一个图上定义一个联合概率分布,他要解决的是如何把联合概率分布表示成局部因子连乘积的形式。概率图模型的表示其实也就是建模的问题;
概率图模型表示主要研究的问题是,为什么联合概率分布可以表示为局部势函数的联乘积形式(由于条件独立性,使得概率图模型的联合概率分布可以表示成局部势函数连乘积的形式,也正是这种局部势函数连乘积的形式使得概率图建模的复杂度大大地降低),如何在图模型建模中引入先验知识等。
概率图模型的推理
概率图模型的第二大部分是推理,推理是建立在概率图模型表示的基础上,也就是说图模型的结构和参数给定了,我们需要对这个图模型进行一定的推理计算,主要的推理计算有:求边缘概率、求最大后验概率状态以及求归一化因子等等。
求边缘概率是指已知联合概率分布,求部分变量的边缘概率 。
最大后验概率状态是已知联合概率分布,求这个分布中 的某个取值能够使得整个联合概率分布最大 。
归一化因子是求一个归一化因子 ,使得联合概率分布满足概率求和为1的这个约束。
概率推理相当于模型求解,在一般图模型中,概率推理是 NP 难问题。概率推理又分为精确推理和近似推理,精确推理是近似推理的基础。在实际的问题中我们很多时候采取的算法是近似推理算法。近似推理算法并不是最准确的,但是平衡了推理的准确度和时间复杂度。
概率图模型的学习
概率图模型的第三大问题就是图模型的学习,学习是给定训练数据,从训练数据中学习出图模型的结构和参数。其训练数据可表示为如下形式:
表示有 个训练样本,每个训练样本是 维的训练数据,我们要从这个训练数据中把结构和参数学习出来。所谓的结构就是图模型有哪些节点,以及哪些节点之间有边连接,这个是结构部分;参数就是边之间的连接权重,边上之间的概率依赖关系中具体的数值是多少。
概率图模型的学习可以分为参数学习和结构学习。参数学习:从已知图模型的结构中学习模型的参数(图模型中节点与节点之间的边上连接的权重)。结构学习表示的是:从数据中推断变量之间的依赖关系(有哪些节点,节点之间的依赖关系,有时候可以依据经验知识确定模型结构,比如:图像问题直接用马尔可夫随机场表示相邻像素之间的依赖关系)。
概率图模型的应用举例
概率图模型的应用非常广泛,这里举一些典型的应用案例。
图像分割
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。其输入是一张原始图像,输出是分割之后得到的图像。

- Kim, T.; Nowozin, S.; Kohli, P. & Yoo, C. Variable Grouping for Energy Minimization. CVPR, 2011
那如何对图像分割进行建模呢?一般用马尔可夫随机场,一种无向的概率图模型对这个问题进行建模。图像的每一个像素点对应图模型的一个节点。相邻像素点之间定义一条边,边上的参数表示相邻像素的相似性,一副自然图像的像素变化一般是均匀变化的,所以像素点与像素点之间存在概率依赖关系也很正常。在这个图模型上进行概率推理,推理的结果就是分割后的结果图像。
立体视觉

立体视觉的任务是,给定图像,要求输出图像中每一个像素点对应的图像深度(物体的远近关系)。同样可以用概率图模型进行建模,像素表示每一个节点,节点之间的连接边表示像素点之间的依赖关系,采用最大后验概率推理得到上述结果。结果表示为图像颜色的深浅。
- Tappen, Freeman. Comparison of graph cuts with belief propagation for stereo, using identical MRF parameters. ICCV 2003.
图像去噪
图像去噪就是剔除图像中的噪声信号。建模过程也是将一个像素点当作一个概率图模型的一个节点。相邻像素点连接的边表示相邻像素的相似性,相似度越高,概率值越大。

- Felzenszwalb P F, Huttenlocher D P. Efficient Belief Propagation for Early Vision. International Journal of Computer Vision, 2006, 70(1):41–54.
人体姿态估计
人体姿态估计是对给定的人物图像,估计其中的人处于什么姿态。

对于上述问题我们先将人体划分为各个区块,对不同区块用概率图模型建模,也就是每个区块对应一个概率图模型的节点。对于这个节点,它具有多个变量,比如矩形中心位置的坐标,矩形块的角度、长宽等等。概率图模型的边引入人体运动学的约束,然后将这种约束定义到概率图模型的边上。之后就可以进行推理求解了。
- Wang, H. & Koller, D. Multi-Level Inference by Relaxed Dual Decomposition for Human Pose Segmentation. CVPR, 2011
医学图像处理

- Jianwu Dong et al. Phase unwrapping with graph cuts optimization and dual decomposition acceleration for 3D high‐resolution MRI data. MRM 2016
医学诊断
医学诊断是模拟医生做一个概率的推断,医生判断一个患者是否得某种疾病往往是会去观察这种疾病的一些症状,然后分析这些疾病相关的症状,结合他的专家经验来下结论。下面这篇贝叶斯网络做医学诊断也是这个原理。
- D. Nikovski. Constructing Bayesian networks for medical diagnosis from incomplete and partially correct statistics. IEEE TKDE 2000.
对一些疾病会给出相关的很多变量,对这些变量构成概率图模型的节点连接关系,通过专家经验对其进行赋值,然后完成建模。建模完成之后就可以进行推理计算。
计算神经学
在计算神经学领域,研究表明,大脑具有表示和处理不确定性信息的能力。大量的生理和心理学实验发现,大脑的认知处理过程是一个概率推理过程。
Ott和 Stoop建立了二值马尔可夫随机场中信度传播算法和神经动力学模型的联系,证明了连续 Hopfield 网络的方程可以由 BP 算法的消息传递迭代方程得到。因此,马尔可夫随机场中的BP 算法可以由神经元实现,每个神经元对应于MRF 的一个节点,神经元之间的突触连接对应于节点之间的依赖关系 。这就非常巧妙地建立了概率图模型在生理学与神经元之间的联系。
- Ott T, Stoop R. The neurodynamics of belief propagation on binary Markov random fields. NIPS, 2006. 1057–1064.
现有人工智能技术(AI)分为两种主流“大脑”:
- 支持人工神经网路的深度学习加速器,基于研究“电脑”的计算机科学,让计算机运行机器学习算法;
- 支持脉冲神经网络的神经形态芯片,基于研究“人脑”的神经科学,无限模拟人类大脑。
本文为自己学习笔记,如有侵权请联系删除。
我的微信公众号名称:深度学习与先进智能决策
微信公众号ID:MultiAgent1024
公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!
