从各个地方摘抄过来,仅当自己的学习笔记,勿怪,侵删!
概率图模型分为贝叶斯网络(Bayesian Network)和马尔可夫网络(Markov Network)两大类。贝叶斯网络可以用一个有向图结构表示, 马尔可夫网络可以表示成一个无向图的网络结构。
更详细地说,概率图模型包括了朴素贝叶斯模型、最大熵模型、隐马尔可夫模型、条件随机场、主题模型等,在机器学习的诸多场景中都有着广泛的应用。
更详细地说,概率图模型包括了朴素贝叶斯模型、最大熵模型、隐马尔可夫模型、条件随机场、主题模型等,在机器学习的诸多场景中都有着广泛的应用。
概率图模型
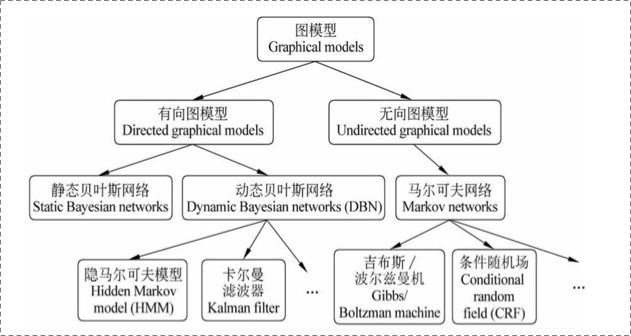
概率图模型在实际中(包括工业界)的应用非常广泛与成功。这里举几个例子。隐马尔可夫模型(HMM)是语音识别的支柱模型,高斯混合模型(GMM)及其变种K-means是数据聚类的最基本模型,条件随机场(CRF)广泛应用于自然语言处理(如词性标注,命名实体识别),Ising模型获得过诺贝尔奖,话题模型在工业界大量使用(如腾讯的推荐系统)等等
机器学习的一个核心任务是从观测到的数据中挖掘隐含的知识,而概率图模型是实现这一任务的一种很elegant,principled的手段。PGM巧妙地结合了图论和概率论。
从图论的角度,PGM是一个图,包含结点与边。结点可以分为两类:隐含结点和观测结点。边可以是有向的或者是无向的。
从概率论的角度,PGM是一个概率分布,图中的结点对应于随机变量,边对应于随机变量的dependency或者correlation关系。
给定一个实际问题,我们通常会观测到一些数据,并且希望能够挖掘出隐含在数据中的知识。怎么用PGM实现呢?我们构建一个图,用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,最后获得一个概率分布。给定概率分布之后,通过进行两个任务:inference (给定观测结点,推断隐含结点的后验分布)和learning(学习这个概率分布的参数),来获取知识。PGM的强大之处在于,不管数据和知识多复杂,我们的处理手段是一样的:建一个图,定义一个概率分布,进行inference和learning。这对于描述复杂的实际问题,构建大型的人工智能系统来说,是非常重要的。
在概率图模型中,数据(样本)由公式 建模表示:
表示节点,即随机变量(放在此处的,可以是一个token或者一个label),具体地,用
为随机变量建模,注意
现在是代表了一批随机变量(想象对应一条sequence,包含了很多的token),
为这些随机变量的分布;
表示边,即概率依赖关系。具体咋理解,还是要在后面结合HMM或CRF的graph具体解释。
概率图模型可以分为两种:有向图和无向图。
有向图 vs无向图
上图可以看到,贝叶斯网络(信念网络)都是有向的,马尔科夫网络无向。所以,贝叶斯网络适合为有单向依赖的数据建模,马尔科夫网络适合实体之间互相依赖的建模。具体地,他们的核心差异表现在如何求 ,即怎么表示
这个的联合概率。
有向图
对于有向图模型,这么求联合概率:
举个例子,对于下面的这个有向图的随机变量(注意,这个图我画的还是比较广义的):
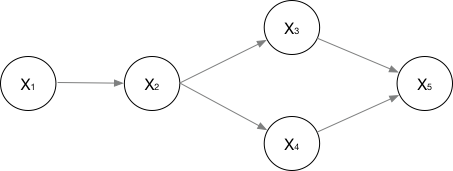
应该这样表示他们的联合概率:
应该很好理解吧。
无向图
对于无向图,我看资料一般就指马尔科夫网络(注意,这个图我画的也是比较广义的)。
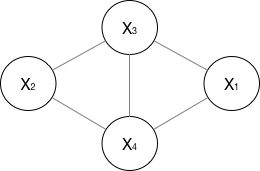
如果一个graph太大,可以用因子分解将 写为若干个联合概率的乘积。咋分解呢,将一个图分为若干个“小团”,注意每个团必须是“最大团”(就是里面任何两个点连在了一块,具体……算了不解释,就是最大连通子图),则有:
, 其中 ,公式应该不难理解吧,归一化是为了让结果算作概率。
所以像上面的无向图:
其中, 是一个最大团
上随机变量们的联合概率,一般取指数函数的:
好了,管这个东西叫做势函数。注意 是否有看到CRF的影子。
那么概率无向图的联合概率分布可以在因子分解下表示为:
注意,这里的理解还蛮重要的,注意递推过程,敲黑板,这是CRF的开端!