一、KNN算法
1.基本思想
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
首先选择数据集作为训练样本,这些数据集都带有标签。由于KNN算法没有训练这一过程,所以选择出的训练样本就是最终的模型。假如现在有一个新的样本x,想知道这个样本x属于哪个类别。KNN的方法就是:先求得这个样本x与所有训练样本的距离,得到最靠近x的K个样本。接着在这K个样本中,统计类别标签以及类别标签的个数,类别标签数目最多的就可以作为样本x的分类。
KNN的算法极度简单,而且效果比较好。但是也存在不少问题。
2.核心代码
这里我先创建了ml文件夹,以下所有的代码的文件都放在该目录下,同时创建__init.py__文件,里面内容为空,目的是使ml成为1个模块,使以下编写的函数模块能够被调用。
1)kNN.py
这里knn的核心代码,理解之后再使用sklearn中的成熟模块,能够有更深的理解。
import numpy as np
from math import sqrt
from collections import Counter
from .metrics import accuracy_score #这里的metrics是自己编写的模块,计算准确度的代码,'.'代表的是当前knn.py所在的目录下
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid" #这里添加断言,判断k是否是合法的
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict] #开始计算待分类样本和所有训练样本的距离
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in self._X_train]
nearest = np.argsort(distances) #对计算结果进行排序
topK_y = [self._y_train[i] for i in nearest[:self.k]] #取出排在前k的样本的标签
votes = Counter(topK_y) #统计这些标签的数目
return votes.most_common(1)[0][0] #标签数目最多的就可以作为待分类样本的标签,这里的1代表只取最多的1个,[i][0]表示标签数目第i+1多的标签是什么。[i][1]就代表的标签数目第i+1多的标签对应的数量。所以[0][0]就代表着标签数目第1多【也就是最多】的标签是什么。
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self): #即上面return self返回的内容,会通过这里进行显示
return "KNN(k=%d)" % self.k
2)metrics.py
import numpy as np
def accuarcy_score(y_true,y_predict):
assert y_true.shape[0]==y_predict.shape[0],\
"the size of y_true must be equal to the size of y_predict"
return sum(y_predict==y_true)/len(y_predict)
3.选取训练集和测试集
理解完knn的核心代码后,就进行实际应用。这里我们将使用numpy自带的鸢尾花数据集进行测试。首先需要将数据集进行乱序处理,再选取一定比例的样本作为训练集,一部分作为测试集,最后查看分类的准确度。之所以要先乱序是因为可以使数据发布更合理,防止训练样本或者测试样本倾斜的问题。
1)model_selection.py
这个模块的工作就是对数据集进行乱序排列,并选取一部分作为训练集,另一部分作为测试集。test_radio就是测试集的比重,默认是0.2。
import numpy as np
def train_test_split(X, y, test_radio=0.2, seed=None):
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_radio <= 1.0, \
"test_radio must be valid"
if seed: #指定seed可以对效果进行反复检验
np.random.seed(seed)
shuffle_indexes = np.random.permutation(len(X)) #对len(X)个数,进行乱序处理,得到乱序的排列
test_size = int(len(X) * test_radio)
test_indexes = shuffle_indexes[:test_size] #取出test_size-1个作为测试集
train_indexes = shuffle_indexes[test_size:] #剩下的作为训练集
X_train = X[train_indexes] #用fancy indexing,得到index对应的训练数据集样本
y_train = y[train_indexes] #用fancy indexing,得到index对应的训练数据集标签
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train,X_test,y_train,y_test #最后将测试集和训练集以及他们的标签全部返回,这就为knn算法准备好了数据。
4.测试代码
使用jupyter工具,对代码进行测试。在ml文件夹下创建1个Python3文件,文件名可自定义。
import numpy as np from sklearn import datasets #导入鸢尾花数据 iris = datasets.load_iris() X = iris.data y = iris.target from ml.model_selection import train_test_split #因为原始的鸢尾花数据是有序的,这里需要先乱序处理 x_train,x_test,y_train,y_test =train_test_split(X,y) from ml.kNN import KNNClassifier #ml是和测试代码同级的一个文件夹,加入一个空白的__init.py__就可以成为一个模块。 my_knn = KNNClassifier(k=3) my_knn.fit(x_train,y_train) y_predict = my_knn.predict(x_test) sum (y_predict==y_test)/len(y_predict)
5.skleran中的KNN
下面使用sklearn中的knn模块进行,同理使用jupyter工具。
from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test= train_test_split(X,y,test_size=0.3) #指定了0.3作为测试集,这里的X,y即上面的鸢尾花数据集 from sklearn.neighbors import KNeighborsClassifier knn_classifier = KNeighborsClassifier(n_neighbors=3) #3即k的值 knn_classifier.fit(x_train,y_train) knn_classifier.predict(x_test)
之前的代码就是仿造sklearn。
6sklearn中手写识别案例
下面使用numpy中的手写识别数据集,进行分类。
import numpy as np from sklearn import datasets import matplotlib import matplotlib.pyplot as plt digits = datasets.load_digits() digits.keys() #查看有几个特征值 print(digits.DESCR) #查看数据集的描述 x = digits.data #加载数据集 y = digits.target #加载标签,x有64个特征值,总共1797个样本 some_digit= x[666] #随意选取一个数据,这个数据对应的标签是0,可以通过y[666]查看到。 some_digit_image = some_digit.reshape(8,8) #转换成8*8的图像 plt.imshow(some_digit_image,cmap=matplotlib.cm.binary) #将图像绘制出 plt.show()
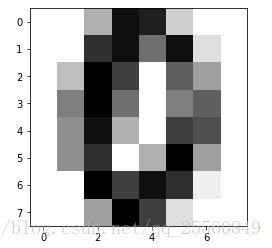
from ml.model_selection import train_test_split x_train,x_test,y_train,y_test =train_test_split(x,y,test_radio=0.3) from ml.kNN import KNNClassifier my_knn = KNNClassifier(k=10) my_knn.fit(x_train,y_train) y_predict = my_knn.predict(x_test) from ml.metrics import accuarcy_score accuarcy_score(y_predict,y_test) #或者my_knn.score(x_test,y_test) #在sklearn中也有accuarcy_score,采用from sklearn.metricsimport accuarcy_score
二、超参数
如何选择k的值?选择不同的K对最终的效果也会有影响,这里的K就是一个超参数。
超参数:在算法运行前需要决定的参数。
模型参数:算法过程中学习的参数。
KNN算法只有超参数,因为模型就是训练数据集,这个模型已经在你选择完训练数据集的时候确定了,所以没有模型参数。其实在KNN中不止一个超参数K,还有1个就是选择distance或者uniform。distance就是通过计算距离待测样本的距离值来确定最终的分类,uniform就是上面所一直在用的,统计数量来确定最终的分类。

例如上图所示:使用普通的KNN,则蓝色获胜,但是使用距离计算,则红色获胜。
1.distance和uniform
import numpy as np
from sklearn import datasets
import matplotlib
import matplotlib.pyplot as plt
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test =train_test_split(x,y,test_size=0.3)
from sklearn.neighbors import KNeighborsClassifier
best_method = "" #初始化这3个值,用来记录当前所使用的超参数。选择不同的method和k将会得到不同的score,得分最高所对应的method和k值即最好的。
best_score=0.0
best_k = -1
for method in ["uniform","distance"]:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights=method) #传入不同参数,获得不同的score
knn_clf.fit(x_train,y_train)
score = knn_clf.score(x_test,y_test)
if score >best_score: #如果score分数比之前的score高,就更新超参数的值,并记录这个score。
best_k =k
best_score=score
best_method = method
print (best_method)
print (best_score)
print (best_k)
使用distance,k选择4,可以得到最好的效果。【因为选择样本是随机的,所有可能会有不同结果】
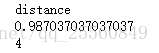
如果想指定random的随机种子,可以更改成如下代码。random_state就是随机种子。
x_train,x_test,y_train,y_test =train_test_split(x,y,test_size=0.3,random_state=66)
2.距离公式选择
对于distance也有不同的选择,选择不同的p可以定义不同距离计算公式。所以这也是一个超参数。
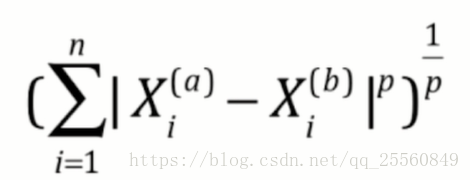
%%time
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test =train_test_split(x,y)
from sklearn.neighbors import KNeighborsClassifier
best_p =-1
best_score=0.0
best_k = -1
for k in range(1,11):
for p in range(1,6):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights="distance",p=p)
knn_clf.fit(x_train,y_train)
score = knn_clf.score(x_test,y_test)
if score >best_score:
best_k =k
best_score=score
best_p = p
print (best_p)
print (best_score)
print (best_k)
3.网格搜索grid search
对于不同的超参数,可以使用grid search 进行,最终只需传入一个grid search格式的参数即可。
import numpy as np
from sklearn import datasets
import matplotlib
import matplotlib.pyplot as plt
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test =train_test_split(x,y)
from sklearn.neighbors import KNeighborsClassifier
param_grid = [
{
'weights': ['uniform'],
'n_neighbors':[i for i in range(1,11)]
},
{
'weights': ['distance'],
'n_neighbors': [i for i in range(1,11)],
'p': [i for i in range(1,6)]
}
]
knn_clf = KNeighborsClassifier()
%%time
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_clf,param_grid)
grid_search.fit(x_train,y_train)
grid_search.best_estimator_
#grid_search.best_score_
#grid_search.best_params_
#knn_clf= grid_search.best_estimator_ #获得最佳模型。
#grid_search =GridSearchCV(knn_clf,param_grid,n_jobs=-1 verbose=2)
#n_jobs代表传入几核,-1代表全部,verbose代表运算过程中输出的信息,值越大越详细

grid_search.best_score_

grid_search.best_params_
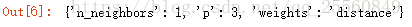
三、数据归一化
1.思想
对于不同的特征值,数据的数量级可能相差很大,这就造成特征值数据本身就比较小的数据对运算的结果几乎不起作用,为了使特征值能够有比较平等的作用效果,需要对数据进行归一化。

最值归一化适合有明显边界的数值,对于没有明显边界的数据可以使用均值方差归一化。【s代表方差】

对测试数据集怎么进行规划呢?这里需要注意的是不能对测试数据集进行单独的归一化,而要用训练数据集归一化的结果【例如得到的std或者mean】用于测试数据集的归一化。

2.采用sklearn的scalar
scalar就采用了上述的方式对测试数据集进行归一化。

import numpy as np from sklearn import datasets iris = datasets.load_iris() x = iris.data y = iris.target from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test =train_test_split(x,y,test_size=0.2,random_state=666) from sklearn.preprocessing import StandardScaler standor = StandardScaler() standor.fit(x_train) standor.mean_ standor.scale_ x_train=standor.transform(x_train) x_test = standor.transform(x_test)