语法分析是编译过程的核心部分,主要任务是在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。本质是按文法的产生式,识别输入符号串是否为一个句子,即判断能否从文法开始符号出发推导出这个输入字符串。语法分析的过结果是构造语法树,按照语法树的构造过程可分为自上而下推导,自下而上规约。本章主要讨论自上而下的推导。
语法分析器的功能:语法分析是编译过程的核心部分。它的任务是在词法分析识别出单词符号串的基础上,分析并判定程序的语法结构是否符合语法规则。
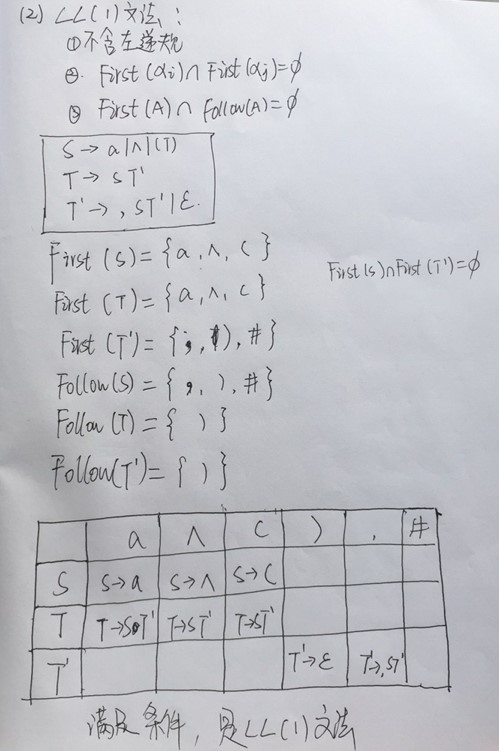
LL(1) 分析法:LL:L:left->right扫描;L:最左推导。
消除直接左递归:
设有产生式 P→Pα|β (1)
其中β不以P开头,α不为ε。那么,我们可以把P的规则改为如下的非直接左递归形式:
P→βP’
P’→αP’|ε (2)
(1)式和(2)式是等价的
消除直接左递归方法:

设有产生式 P→Pα1|Pα2|…|Pαm|β1|β2|…|βn 其中每个βi不以P开头,每个αi不为ε
消除P的直接左递归性就是把这些规则改写成:
P→β1P’|β2P’|…|βnP’
P’→α1P’| α2P’|…|αmP’| ε
按任意顺序对非终结符排序,P1,P2,P3……,然后作如下工作
FOR i=1 TO N{
FOR j=1 TO i-1{
对PiPjγ的产生式,改写成
Piδ1 γ| δ2 γ|…| δk γ
}
消除Pi的直接左递归;
}
最后,删除无用(从起始符永远不能到达)的非终结符的产生式。
消除间接左递归方法:
(1) 将间接左递归改造为直接左递归
将文法中所有如下形式的产生式:
Pi →Pjγ|β1|β2|…|βn
Pj→δ1|δ2|δ3|…|δk
改写成:
Pi →δ1γ|δ2γ|δ3γ|…|δkγ|β1|β2|…|βn
(2)消除直接左递归
P→Pα1|Pα2|...|Pαm|β1| β2|...| βn
消除P的左递归
P→ β1P'| β2P'|...| βnP'
P'→ α1 P'| α2 P'|...|αm P'| ε
(3)化简改写后的文法,即去除那些从开始符号出发却永远无法到达的非终结符的产生规则。
最终得到无左递归的文法。
2.FIRST(X)
(1)若X终结符,则FIRST(X)={X};
(2)若X为非终结符,且有X->a …的产生式,则把a加入到FIRST(X)中;
(3)若X->Y…是一个产生式,且Y为非终结符,则把FIRST (Y)-ε加入到FIRST(X)中;
(4)若X->Y1Y2Y3….YK,是产生式,Y1Y2Y3….Yi-1是非终结符,而且ε属于FIRST (Yj)(1<=j<=i-1),则把FIRST (Yj)-ε加入到FIRST(X)中;如果ε属于所有的FIRST (Yj),则ε加入到FIRST(X)中。
3.FOLLOW(X)
(1)对于文法的开始符,置#于FOLLOW(S)中;
(2)若A->αBβ, 则把FIRST (β)-ε加入到FOLLOW(B)中;
(3)若A->αB 是一个产生式,或 A->αBβ是一个产生式,而β-> ε,则把FOLLOW(A)加入到FOLLOW(B)中。
下面是这一章的习题: