hadoop自学日记–1.单机hadoop环境搭建
前言
本人大数据小白,从头开始学大数据技术,记录学习过程,自我鞭策。
大数据特点
volume(大量的),即数据量大。variety(多样的),即数据类型多样化。velocity(时效的),数据必须能在最短时间内得出分析结果,时间太久就失去了数据的价值。
Hadoop特点
scalable(可拓展):由于Hadoop采用分布式计算和存储,当我们扩充或运算时,不需要更换整个系统,只需要增加新的数据节点服务即可。economical(经济的):由于Hadoop采用分布式计算和存储,不必使用昂贵高端的服务器,只需使用一般等级的服务器就可搭建出高性能、高容量的集群。flexible(弹性的):Hadoop存储的数据是非结构化(schema-less)的,可以存储各种形式、不同数据源的数据。reliable(可靠的):Hadoop采用分布式架构,因此即使某一台服务器硬件坏掉,甚至整个机架坏掉,HDFS仍可正常运行,因为数据还会有另外2个副本。
搭建环境
本人使用简单的windows 7笔记本,使用VirtualBox创建Centos虚拟机来安装Hadoop
VirtualBox:6.0.8 r130520 (Qt5.6.2)
CentOS:CentOS Linux release 7.6.1810 (Core)
jdk:1.8.0_202
hadoop:2.6.5
安装虚拟机基础环境
1.安装操作系统
下载centos的安装包:CentOS-7-x86_64-Minimal-1810.iso
这是centos的最小安装版,需要自行安装所需软件。
禁用防火墙:
[root@ ~]# systemctl stop firewalld
[root@ ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
2.配置网络
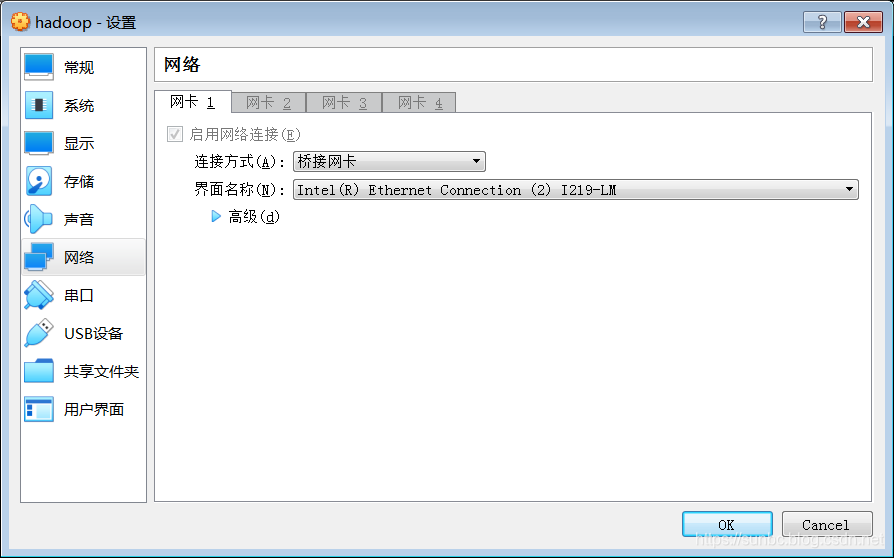
我这里希望虚拟机能访问外网,也能和宿主机相互ssh访问,所以需要配置2个网卡:
一个桥接网卡,用来连接外网和宿主机:
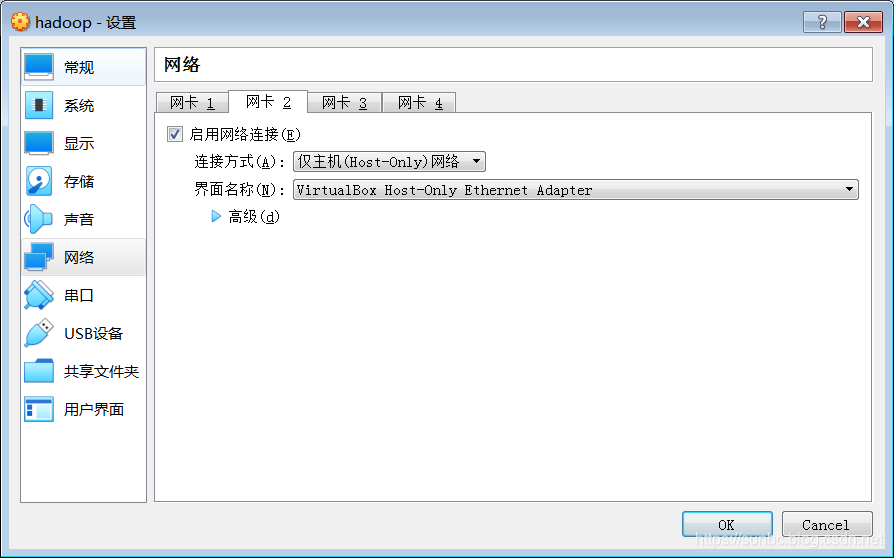
 一个Host-only网络,预备用来做虚拟机之间的通信:
一个Host-only网络,预备用来做虚拟机之间的通信:
 安装ifconfig工具,查看网络情况:
安装ifconfig工具,查看网络情况:
[root@ ~]# yum install -y net-tools wget vim
[root@ ~]# ifconfig
enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.11.91.156 netmask 255.255.255.0 broadcast 10.11.91.255
inet6 fe80::cfb8:10a7:ca04:61ea prefixlen 64 scopeid 0x20<link>
ether 08:00:27:5a:15:57 txqueuelen 1000 (Ethernet)
RX packets 517 bytes 52208 (50.9 KiB)
RX errors 0 dropped 4 overruns 0 frame 0
TX packets 58 bytes 8106 (7.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
enp0s8: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.37.102 netmask 255.255.255.0 broadcast 192.168.37.255
inet6 fe80::afe5:d7b0:66fc:a9a2 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:95:88:a2 txqueuelen 1000 (Ethernet)
RX packets 5 bytes 1456 (1.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 15 bytes 1706 (1.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
桥接网卡创造的ip为:10.11.91.156
Host-Only创造的ip微:192.168.37.102
安装jdk
hadoop是使用java开发的,所以必须先安装jdk。
这里我没有用openjdk,而使用的是oracle的官方jdk。
下载地址:jdk-8u202-linux-x64.tar.gz
该连接无法使用wget下载,需要手动下载后上传到/software路径:
[root@ ~]# cd /software/
[root@ software]# tar -zxvf jdk-8u202-linux-x64.tar.gz
配置环境变量:
[root@ software]# vim ~/.bash_profile
export JAVA_HOME=/software/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效:
[root@ software]# source ~/.bash_profile
验证:
[root@ software]# java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
ssh免密登陆
hadoop需要通过ssh与本地计算机及其他主机连接,所以必须设置ssh免密。
1.安装ssh和rsync
[root@ software]# yum install -y ssh rsync
ssh一半centos都自带了,rsync是用来做数据同步的
2.创造ssh密钥
[root@ software]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
SHA256:ya0kL/LLVZInAWM/46pyVViayUBED1ctDAmozZwKwI0 root@.
The key's randomart image is:
+---[DSA 1024]----+
|. o=*.*=.. |
|.E...=.++ . |
|.= . o.*=. |
|o = *o.B |
|.. ..S + |
|. .= * |
| ..o + |
| . .= o |
| o. +. |
+----[SHA256]-----+
3.将密钥写入许可证
[root@ software]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
4.验证
[root@ software]# ssh 10.11.91.156
The authenticity of host '10.11.91.156 (10.11.91.156)' can't be established.
ECDSA key fingerprint is SHA256:sVo82fntVBJ6mhn1+oSp+1lLVknmE7s4JcMg4MVoLO0.
ECDSA key fingerprint is MD5:89:6d:c0:42:b1:21:79:07:c4:41:19:a2:0a:45:19:43.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '10.11.91.156' (ECDSA) to the list of known hosts.
Last login: Wed Jul 17 15:06:07 2019 from 10.11.91.202
安装hadoop
直接使用清华的镜像:hadoop下载地址
我这里使用的是:hadoop-2.6.5.tar.gz
同样上传至/software目录:
[root@ software]# tar -zxvf hadoop-2.6.5.tar.gz
[root@ software]# ll ./hadoop-2.6.5/
total 108
drwxrwxr-x. 2 1000 1000 194 Oct 3 2016 bin
drwxrwxr-x. 3 1000 1000 20 Oct 3 2016 etc
drwxrwxr-x. 2 1000 1000 106 Oct 3 2016 include
drwxrwxr-x. 3 1000 1000 20 Oct 3 2016 lib
drwxrwxr-x. 2 1000 1000 239 Oct 3 2016 libexec
-rw-rw-r--. 1 1000 1000 84853 Oct 3 2016 LICENSE.txt
-rw-rw-r--. 1 1000 1000 14978 Oct 3 2016 NOTICE.txt
-rw-rw-r--. 1 1000 1000 1366 Oct 3 2016 README.txt
drwxrwxr-x. 2 1000 1000 4096 Oct 3 2016 sbin
drwxrwxr-x. 4 1000 1000 31 Oct 3 2016 share
常用目录说明如下:
| 目录 | 说明 |
|---|---|
| bin | 各项运行文件,包括hadoop、hdfs、yran等 |
| sbin | 各项shell运行文件,包括start-all.sh、stop-all.sh等 |
| etc | etc/hadoop子目录包含hadoop的配置文件,如hadoop-env.sh、core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml等 |
| lib | hadoop的函数库 |
| logs | 系统日志,记录系统运行状况 |
设置环境变量:
[root@ software]# vim ~/.bash_profile
# jdk安装路径
export JAVA_HOME=/software/jdk1.8.0_202
#hadoop安装路径
export HADOOP_HOME=/software/hadoop-2.6.5
#设置path
export PATH=$PATH:$JAVA_HOME/bin
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#hadoop其他组件环境路径
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
#链接库设置
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
使环境变量生效:
[root@ software]# source ~/.bash_profile
验证:
[root@ software]# hadoop version
Hadoop 2.6.5
Subversion https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997
Compiled by sjlee on 2016-10-02T23:43Z
Compiled with protoc 2.5.0
From source with checksum f05c9fa095a395faa9db9f7ba5d754
This command was run using /software/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5.jar
配置hadoop
1.hadoop-env.sh
hadoop-env.sh是hadoop的配置文件,需要在里面配置jdk信息,来让hadoop能找到jdk:
将${JAVA_HOME}修改为jdk所在路径:
[root@ software]# vim /software/hadoop-2.6.5/etc/hadoop/hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/software/jdk1.8.0_202
2.core-site.xml
core-site.xml是hadoop的全局配置文件,改为:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3.yarn-site.xml
yarn-site.xml是mapreduce2(yarn)的配置文件,改为:
<configuration>
<property>
<name>yarn.nodemanager.aux.services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux.services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
4.mapred-site.xml
mapred-site.xml是监控map和reduce程序的jobtracker的配置文件,需要复制其模板文件来修改:
[root@ software]# cp /software/hadoop-2.6.5/etc/hadoop/mapred-site.xml.template /software/hadoop-2.6.5/etc/hadoop/mapred-site.xml
[root@ software]# vim /software/hadoop-2.6.5/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.hdfs-site.xml
hdfs-site.xml是hdfs的配置文件,改为:
[root@ software]# vim /software/hadoop-2.6.5/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/software/hadoop-2.6.5/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>file:/software/hadoop-2.6.5/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
这里我设置blicks副本备份数为3,并配置namenode和datanode的目录。
初始化hdfs目录
创建相应目录:
[root@ software]# mkdir -p /software/hadoop-2.6.5/hadoop_data/hdfs/namenode
[root@ software]# mkdir -p /software/hadoop-2.6.5/hadoop_data/hdfs/datanode
格式化namenode:
[root@ software]# hadoop namenode -format
启动全套hadoop
可以直接使用start-all.sh直接同时启动hdfs、yarn,也可以分别启动。下面一个个的来启动:
1.启动hdfs
使用start-dfs.sh命令:
[root@ software]# start-dfs.sh
Starting namenodes on [localhost]
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:sVo82fntVBJ6mhn1+oSp+1lLVknmE7s4JcMg4MVoLO0.
ECDSA key fingerprint is MD5:89:6d:c0:42:b1:21:79:07:c4:41:19:a2:0a:45:19:43.
Are you sure you want to continue connecting (yes/no)? yes
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
localhost: starting namenode, logging to /software/hadoop-2.6.5/logs/hadoop-root-namenode-..out
localhost: starting datanode, logging to /software/hadoop-2.6.5/logs/hadoop-root-datanode-..out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:sVo82fntVBJ6mhn1+oSp+1lLVknmE7s4JcMg4MVoLO0.
ECDSA key fingerprint is MD5:89:6d:c0:42:b1:21:79:07:c4:41:19:a2:0a:45:19:43.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /software/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-..out
需要手动确认2次,使用jps查看进程是否启动:
[root@ software]# jps
14130 SecondaryNameNode
13991 DataNode
14232 Jps
13881 NameNode
启动yarn
使用start-yarn.sh命令来启动yarn:
[root@ software]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /software/hadoop-2.6.5/logs/yarn-root-resourcemanager-..out
localhost: starting nodemanager, logging to /software/hadoop-2.6.5/logs/yarn-root-nodemanager-..out
使用jps查看状态:
[root@ software]# jps
14130 SecondaryNameNode
13991 DataNode
13881 NameNode
14282 ResourceManager
14379 NodeManager
14654 Jps
可看到:
- hdfs功能:NameNode、SecondaryNameNode、DataNode已正常启动
- yarn功能:ResourceManager、NodeManager已正常启动
访问web操作界面
1.resource manager web界面
resource manager web界面可用于查看当前hadoop的状态:node节点,应用程序,进程运行状态。
从宿主机访问网址:http://10.11.91.156:8088/
界面如下图:
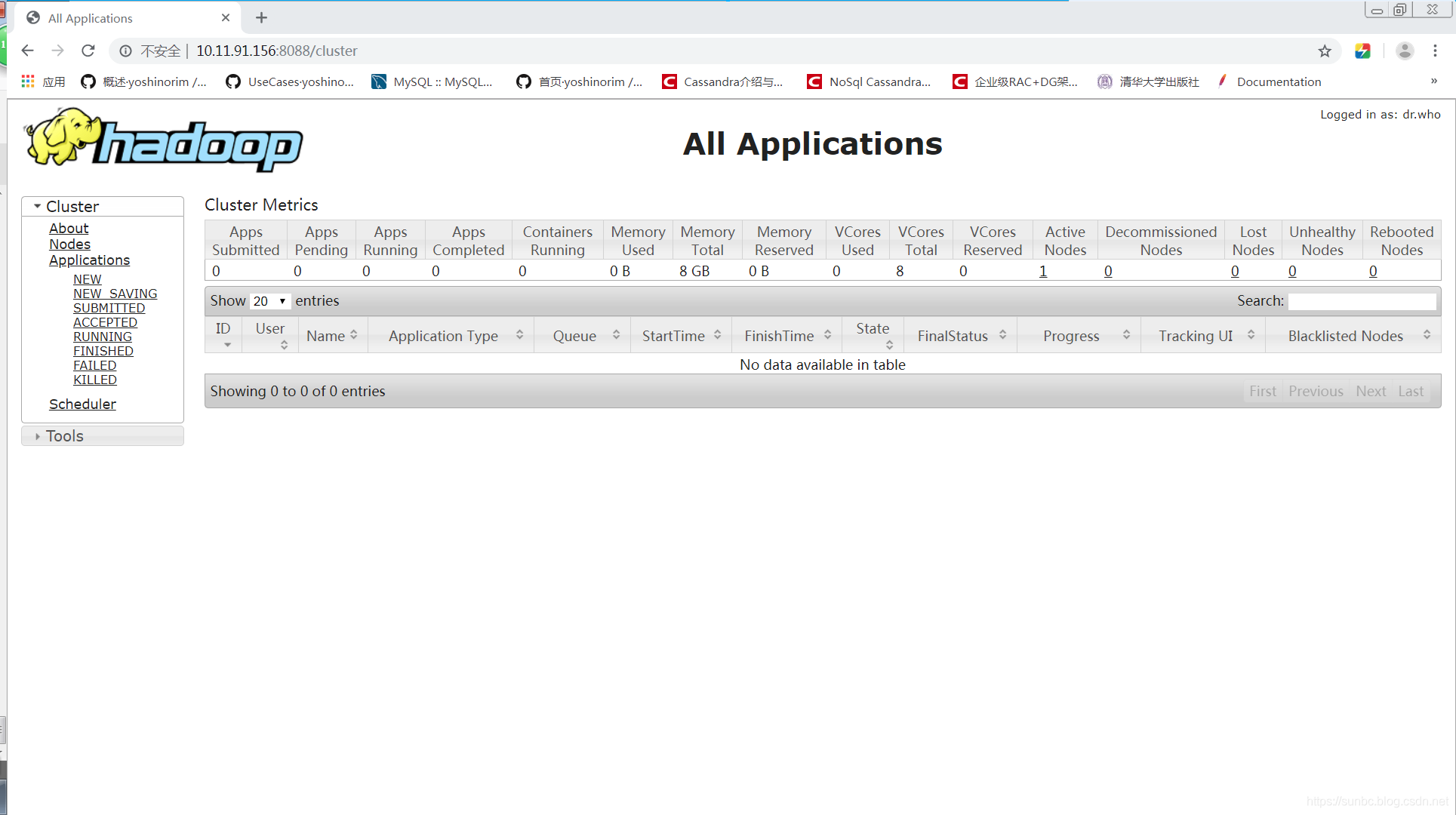 由于我安装的是单节点环境,所以只能看到一个节点。
由于我安装的是单节点环境,所以只能看到一个节点。
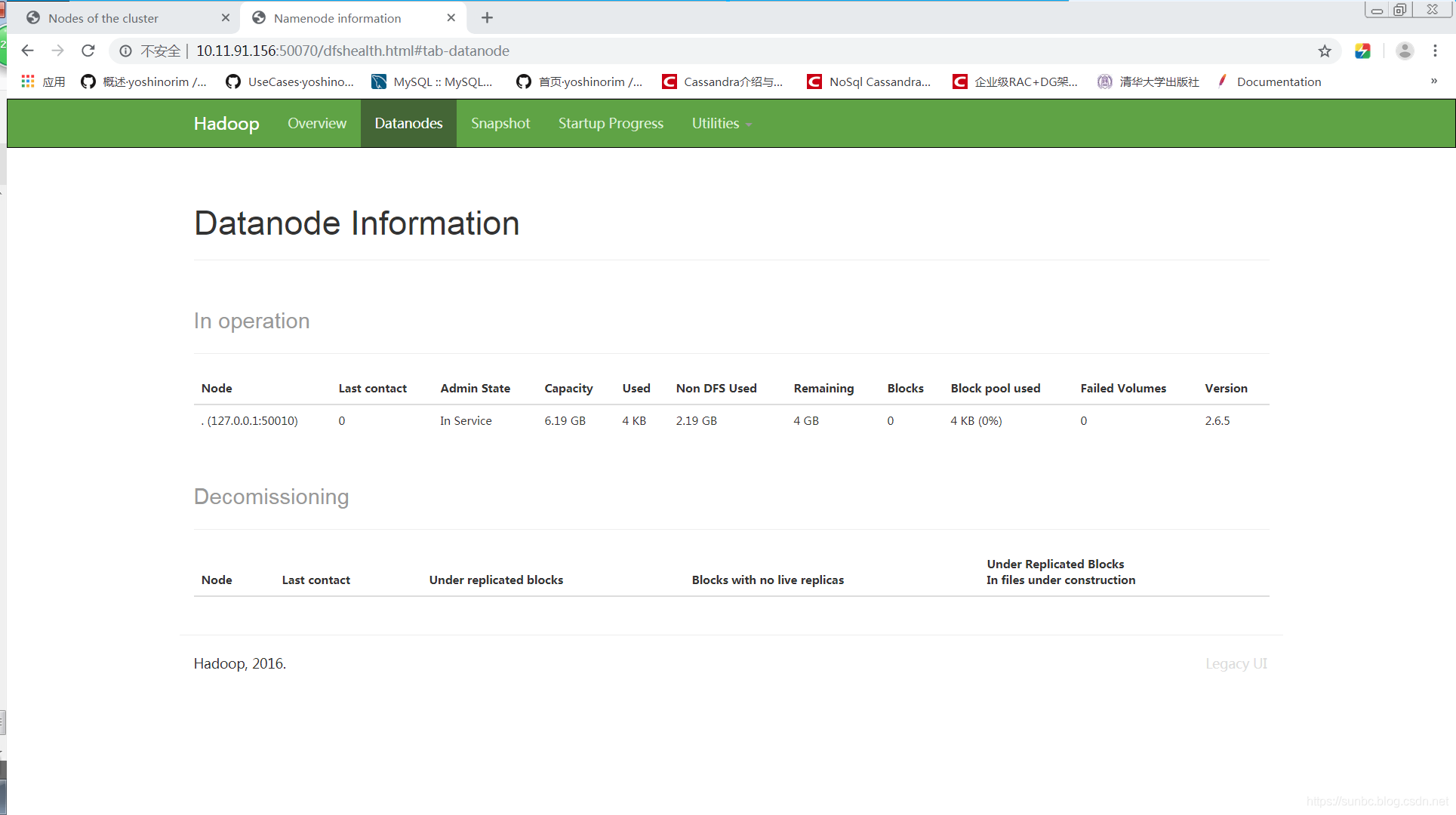
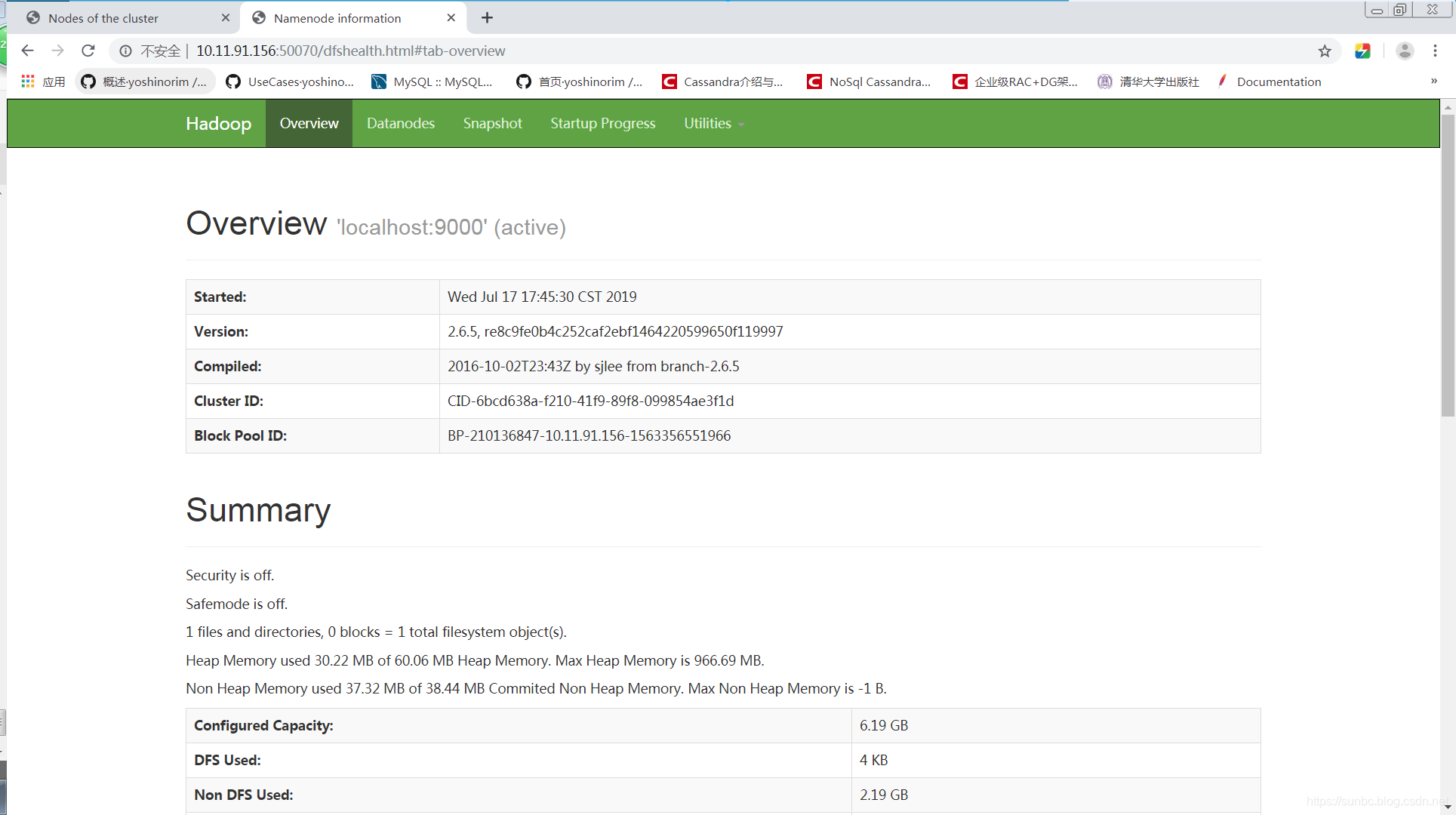
2.namenode hdfs web界面
namenode hdfs web界面可用于查看当前hdfs和datanode的运行状态。
从宿主机访问网址:http://10.11.91.156:50070/
界面如下图:
 可切换到datanodes选项,来查看datanodes状态:
可切换到datanodes选项,来查看datanodes状态: