Hadoop环境搭建与运维
Hadoop概述:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop单机模式和伪分布式:
1.单机模式
1.安装ssh
sudo apt-get install openssh-server
安装后可以使用如下命令登录本机
ssh localhost --会出现Are you sure want to continue contecting(yes/no)?
输入yes即可
2.对于ssh的理解
ssh分为客户端和服务端
一台计算机的时候输入的每条命令都是直接交给本机去处理
当两台计算机的时候:一台为客户端,一台为服务端,假设A为客服端,B为服务端,B的IP地址假设为17.40.61.01,当在A的计算机上执行ssh 17.40.61.01时,就实现了ssh方式登录到B的linux系统执行----A计算机操作的是
B计算机的linux操作系统
3.进行ssh无密码登录
cd ~/.ssh/
ssh-keygen -t rsa –p ‘’ //提示按ENTER就行
cat ./id_rsa.pub>>./authorized_key //加入授权
4.安装java环境
下载jdk安装包到指定文件夹
再使用sudo tar命令前先查看安装包的权限如果是无法执行对其文件权限进行修改
chown user:user jdk_____________-
配置环境变量
vim ~/.bashrc
在~/.bashrc中添加export JAVA_HOME=/opt/jdk1.8.0_171---------jdk所在路径
export PATH=$PATH:$JAVA_HOME/bin
退出 ~/.bashrc文件界面
使环境变量生效 source ~/.bashrc
检验是否设置成功 java –version
5.安装hadoop
进行权限修改 chown user:user –R /xx/Hadoop/*
sudo tar -zxf hadoop------ -C /usr/local
到hadoop中配置JAVA_HOME,文件位于hadoop2.7.6/etc/hadoop/hadoop.env.sh,将JAVA_HOME配置成JDK所在路径.
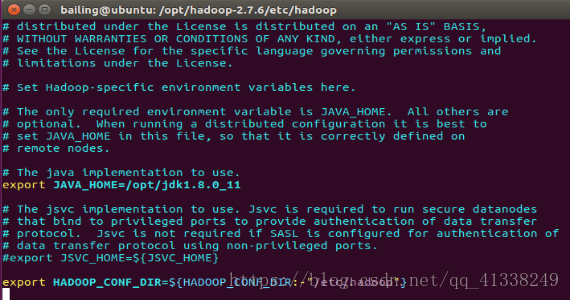
6.单机模式配置
mkdir input
cp ./etc/hadoop/*xml ./input //将配置文件复制到input目录下
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples------- jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* //查看运行结果

伪分布式模式
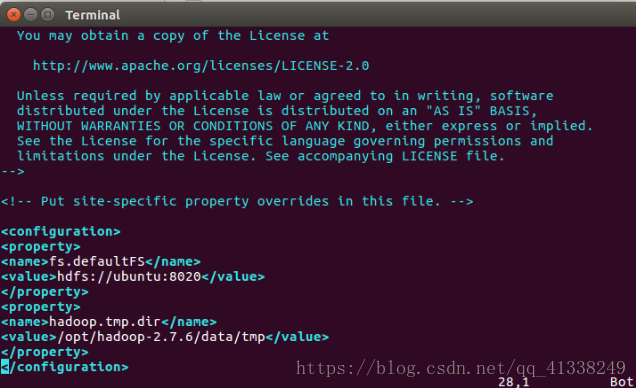
修改配置文件core-site.xml和hdfs-site.xml文件
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp</value>
</property>
</configuration>
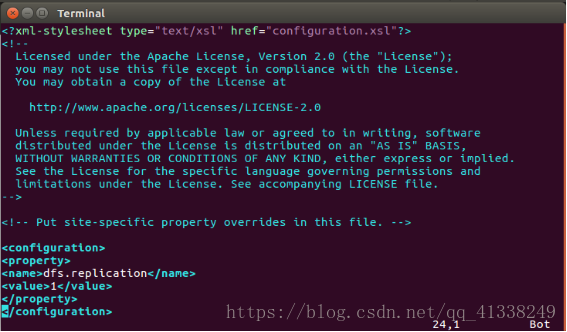
vim hdfs_site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name> dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp/data</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name </name>
<value>yarn</value>
</property>
</configuration>
vim yanr-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services </name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7..执行节点格式化和运行hadoop
返回到hadoop安装目录 cd/usr/local/hadoop-2.7.6
格式化 ./bin/hdfs namenode –format
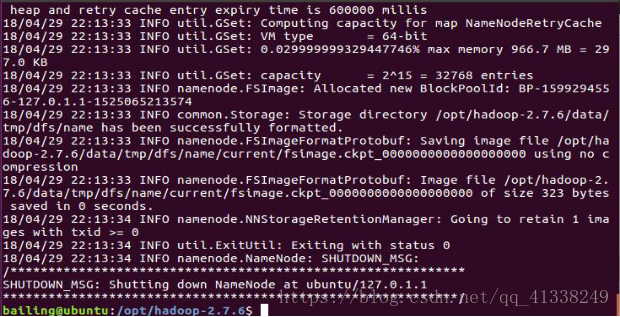
如果出现Exiting with status 1,则为错误 (通常为namenode和datanode信息存放文件 没有权限)
启动:
Start-hdfs.sh
Start-yarn.sh
或者
Start-all.sh
启动成功后jps命令则会列出进程
查看web端界面
Http://127.0.0.1:50070
Hadoop集群模式搭建
完成伪单机模式的搭建,并从这基础上进行修改
修改core-site.xml文件如下:
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp </value>
修改hdfs-site.xml如下:
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp /name</value>
<name>dfs.datanode.name.dir</name>
<value>/opt/hadoop-2.7.6/data/tmp/data</value>
<name>dfs.replication</name>
<value>1</value>
修改mapred-site.xml如下
<name>mapreduce.framework.name</name>
<value>yarn</value>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
修改yarn-site.xml如下
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<name>yarn.resourcemanager.hostname</value>
<value>Master</value>
使用scp命令将主机配置完的hadoop传送到个从机(注意路径)
Scp ./hadoop.Master.hadoop.tar.gz Salve1:/home/hadoop/
Hadoop HA模式的介绍
1.概述
在hadoop2.x版本之前,namenode只存在一个,存在单点问题(虽然hadoop1.x版本有secondarynamenode,checkpointnode,buckcupnode这些,但是单点问题无法解决),在hadoop2.x版本后引入了HA机制。hadoop2.x的HA机制官方介绍了有2种方式,一种是NFS(Network File System)方式,另外一种是QJM(Quorum Journal Manager)方式。
2 基本原理
hadoop2.x的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。两者的状态互相血环,但不会同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。active namenode和standby namenode之间通过NFS或者JN来同步数据完成日常作业。
查看集群运行状态(命令,Ui)
命令:hadoop dfsadmin -report
Ui: Master ip地址:500030
Hadoop命令的基本使用
FS Shell
调用文件系统(FS)Shell命令应使用 bin/hadoop fs <args>的形式。 所有的的FS shell命令使用URI路径作为参数。URI格式是scheme://authority/path。对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。一个HDFS文件或目录比如/parent/child可以表示成hdfs://namenode:namenodeport/parent/child,或者更简单的/parent/child(假设你配置文件中的默认值是namenode:namenodeport)。大多数FS Shell命令的行为和对应的Unix Shell命令类似,不同之处会在下面介绍各命令使用详情时指出。出错信息会输出到stderr,其他信息输出到stdout。
使用方法:hadoop fs -cat URI [URI …]
将路径指定文件的内容输出到stdout。
示例:
· hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
· hadoop fs -cat file:///file3 /user/hadoop/file4
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI …] Change group association of files. With -R, make the change recursively through the directory structure. The user must be the owner of files, or else a super-user. Additional information is in the Permissions User Guide. -->
改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
使用方法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
使用方法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改变文件的拥有者。使用-R将使改变在目录结构下递归进行。命令的使用者必须是超级用户。更多的信息请参见HDFS权限用户指南。
使用方法:hadoop fs -copyFromLocal <localsrc> URI
除了限定源路径是一个本地文件外,和put命令相似。
使用方法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
除了限定目标路径是一个本地文件外,和get命令类似。
使用方法:hadoop fs -cp URI [URI …] <dest>
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
· hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
· hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -du URI [URI …]
显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -dus <args>
显示文件的大小。
使用方法:hadoop fs -expunge
清空回收站。请参考HDFS设计文档以获取更多关于回收站特性的信息。
使用方法:hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
示例:
· hadoop fs -get /user/hadoop/file localfile
· hadoop fs -get hdfs://host:port/user/hadoop/file localfile
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -getmerge <src> <localdst> [addnl]
接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl是可选的,用于指定在每个文件结尾添加一个换行符。
使用方法:hadoop fs -ls <args>
如果是文件,则按照如下格式返回文件信息:
文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
目录名 <dir> 修改日期 修改时间 权限 用户ID 组ID
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -lsr <args>
ls命令的递归版本。类似于Unix中的ls -R。
使用方法:hadoop fs -mkdir <paths>
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
示例:
· hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
· hadoop fs -mkdir hdfs://host1:port1/user/hadoop/dir hdfs://host2:port2/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
使用方法:dfs -moveFromLocal <src> <dst>
输出一个”not implemented“信息。
使用方法:hadoop fs -mv URI [URI …] <dest>
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:
· hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
· hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -put <localsrc> ... <dst>
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
· hadoop fs -put localfile /user/hadoop/hadoopfile
· hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
· hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
· hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:
· hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -rmr URI [URI …]
delete的递归版本。
示例:
· hadoop fs -rmr /user/hadoop/dir
· hadoop fs -rmr hdfs://host:port/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -setrep [-R] <path>
改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。
示例:
· hadoop fs -setrep -w 3 -R /user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -stat URI [URI …]
返回指定路径的统计信息。
示例:
· hadoop fs -stat path
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -tail [-f] URI
将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。
示例:
· hadoop fs -tail pathname
返回值:
成功返回0,失败返回-1。
使用方法:hadoop fs -test -[ezd] URI
选项:
-e 检查文件是否存在。如果存在则返回0。
-z 检查文件是否是0字节。如果是则返回0。
-d 如果路径是个目录,则返回1,否则返回0。
示例:
· hadoop fs -test -e filename
使用方法:hadoop fs -text <src>
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
使用方法:hadoop fs -touchz URI [URI …]
创建一个0字节的空文件。
示例:
· hadoop -touchz pathname
返回值:
成功返回0,失败返回-1。
Wordcount示例程序的运行和日志查看
1.Wordcount示例程序
运行 wordcount 程序
已经启动了必需的各项进程:namenode、datanode、resourcemanager、nodemanager、JobHistoryServer 等
确保当前 hdfs 不处于安全模式
hdfs dfsadmin -safemode leave
1
确保已经在 HDFS 中创建了相关目录 /data/wordcount 、/output ,以下 /tmp 及其以下目录是启动 JobHistoryServer 后系统自动生成的
上传了测试数据集 slaves
hadoop fs -put /usr/local/cluster/hadoop/etc/hadoop/slaves /data/wordcount/
进入程序所在目录,并运行程序
cd /usr/local/cluster/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.5.0-cdh5.3.2.jar wordcount /data/wordcount /output/wordcount
15/12/22 00:30:36 INFO input.FileInputFormat: Total input paths to process : 115/12/22 00:30:37 INFO mapreduce.JobSubmitter: number of splits:115/12/22 00:30:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1450714294593_000115/12/22 00:30:37 INFO impl.YarnClientImpl: Submitted application application_1450714294593_000115/12/22 00:30:37 INFO mapreduce.Job: The url to track the job: http://master5:8088/proxy/application_1450714294593_0001/15/12/22 00:30:37 INFO mapreduce.Job: Running job: job_1450714294593_000115/12/22 00:30:43 INFO mapreduce.Job: Job job_1450714294593_0001 running in uber mode : false15/12/22 00:30:43 INFO mapreduce.Job: map 0% reduce 0%15/12/22 00:30:49 INFO mapreduce.Job: map 100% reduce 0%15/12/22 00:31:04 INFO mapreduce.Job: map 100% reduce 100%15/12/22 00:31:05 INFO mapreduce.Job: Job job_1450714294593_0001 completed successfully15/12/22 00:31:05 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=48
FILE: Number of bytes written=212385
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=125
HDFS: Number of bytes written=30
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2347
Total time spent by all reduces in occupied slots (ms)=13060
Total time spent by all map tasks (ms)=2347
Total time spent by all reduce tasks (ms)=13060
Total vcore-seconds taken by all map tasks=2347
Total vcore-seconds taken by all reduce tasks=13060
Total megabyte-seconds taken by all map tasks=2403328
Total megabyte-seconds taken by all reduce tasks=13373440
Map-Reduce Framework
Map input records=3
Map output records=3
Map output bytes=36
Map output materialized bytes=48
Input split bytes=101
Combine input records=3
Combine output records=3
Reduce input groups=3
Reduce shuffle bytes=48
Reduce input records=3
Reduce output records=3
Spilled Records=6
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=98
CPU time spent (ms)=1250
Physical memory (bytes) snapshot=440475648
Virtual memory (bytes) snapshot=4203302912
Total committed heap usage (bytes)=342360064
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=24
File Output Format Counters
Bytes Written=30
2. 日志查看
通过web界面查看hadoop集群运行日志的地址:
http://hostname:8088/logs/