我是鼓楼烟雨,我接下来的几篇博客会介绍一下mysql的原理,写博客的目的主要是为了和大家一块学习和进步,欢迎大家加我的微信讨论与交流,我的微信号是:h438109134
一.mysql的组成与结构(基于mysql5.7)
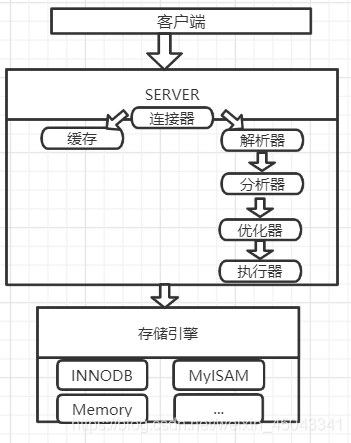
1.客户端与服务器的连接:
客户端与服务端一般通过tcp/ip连接;
通信类型:同步
连接方式:长连接(默认8小时不响应就断开连接;默认允许最大连接线程数151)
通讯方式:半双工
二.一条查询语句的执行
1.缓存:查询语句和返回值以key和value的形式存在缓存,如果sql命中缓存中的key,就直接返回查询结果;
注意:mysql5.7默认是不开启缓存的,mysql8.0更是直接把缓存去掉了.一个原因是比如说:sql中多个空格的话,key就不一致;更主要的原因是,缓存是针对与表的,如果这个表有doUpdate的操作,就会导致缓存失效;
2.解析器parser: 做词法解析和语法解析;词法解析是解析sql的每个单词,判断对错,返回一个解析树; 语法解析是解析sql的语法有没有错误,也会返回一个解析树
3.预编译:比如:看一下你的表名字段名是否存在,如果不存在就报错
4.优化器optimizer:找一个最小cost的方式来执行你的sql; 根据解析树得到一个最小的执行计划,我们的explain命令就是来看这个执行计划的;在这里会优化你关联表的方式和使用索引的方式
5.执行器调用存储引擎的接口查找数据
6.将查出来的数据放回到缓存中;
三.mysql的日志模块
mysql的数据是存在磁盘中,要先把数据加载到内存中才能对数据进行操作
因为磁盘的io读写相对与内存来说很慢,大约只有内存的1%的读写速度,所以磁盘在读取数据的时候不会用多少拿多少,而是有一个预处理的操作,每次会读取page页大小的数据到内存中,page页默认是16kb大小;
并且把每次读取的缓存到bufferpool中,读写都先记录到内存中,内存中的数据和磁盘里的数据不一致就会出现脏页,服务器空闲的时候,大量的工作线程会把脏页刷新到磁盘中,有一个刷脏的过程;
1.服务器宕机或者重启但你没有刷脏怎么办?
把内存的数据做个持久化;把数据记录到磁盘中
这里bufferpool 里的数据也会写入到redolog中 ,能够做到crash safe( acid的d持久性就是靠redolog)
redolog在mysql中分为了两块:内存和磁盘各有一块
2.为什么不直接把bufferpool里的数据写到磁盘中?
redolog是环形的物理日志(记录的不是sql,而是在哪个地方改了什么值),bufferpool里的数据会按顺序写入到redolog中,redoglog以顺序io的方式写入到磁盘,减少了寻址的过程,效率更高
redolog的结构:
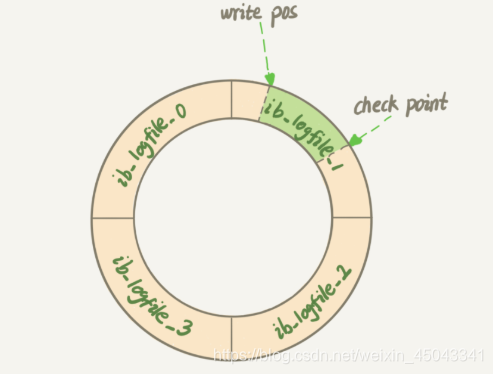
writepos 会写数据,check point会擦除旧的数据,擦除记录前要把记录更新到数据文件。
3.mysql的binlog日志
redolog是InnoDB特有的,Server有一个共有的binlog日志;
MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
binlog文件中存储的内容称之为二进制事件,简称事件。我们的每一个数据库更新操作(Insert、Update、Delete等),都会对应的一个事件。
从大的方面来说,binlog主要分为2种格式:
Statement模式:binlog中记录的就是我们执行的SQL;
Row模式:binlog记录的是每一行记录的每个字段变化前后得到值。
Mixed(即混合模式):只是结合了Statement和Row两种模式而已。
4.binlog与redolog的区别:
1.redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
2.redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑.
3.redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
四.update语句的执行过程
1.执行update table set name = “张三” where id = 1
如果id=1这行数据所在的page页存在bufferpool中,会直接返回给执行器,如果没有,就先从磁盘中读取再返回到内存中;
2.执行器执行完这条语句,调用引擎接口,引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 并将这行记录状态设置为prepare
3.修改玩了,可以提交事务了
4.把数据写入到binlog中并写入磁盘中
5.用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
五.为什么要两阶段提交:
如果写玩redolog提交后,再写binlog的话,如果redolog写完后,还没有写binlog的时候服务器宕机了,会造成数据不一致的情况,当我们用binlog来恢复数据的时候,就与原库数据不一致了;
先写binlog后写redolog
如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,但是 binlog 里面已经记录了,binlog做数据恢复的时候,恢复出来的数据与原库的值不同。
