一、执行过程一句话概述
- 查询语句:权限校验–>缓存查询–>分析器–>优化器–>执行器–>权限校验–>执行器–>引擎。
- 更新语句:分析器–>权限校验–>执行器–>引擎–>redolog prepare–>binlog–>redolog commit。
二、执行过程详解
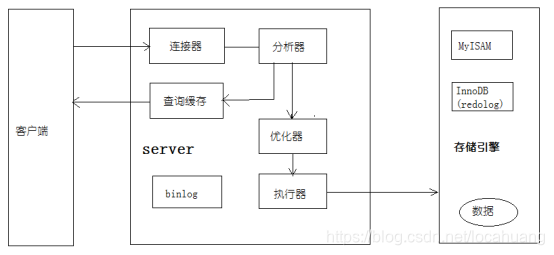
MySQL主要分为2部分:server层和存储引擎层。
- server层:
包括连接器、查询缓存、分析器、优化器、执行器,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图、函数等,以及通用的日志模块binlog。
-
连接器:身份认证和权限相关
主要负责用户登陆数据库,进行用户的身份验证,包括校验码、权限等操作。 -
查询缓存:执行查询语句的时候,会先查询缓存(MySQL8.0版本后移除)
1)该步骤不做语法分析。
2)mysql收到语句后,通过命令分发器判断是否是查询语句。
3)如果是在开启查询缓存的情况下,先查询缓存中查找该SQL是否完全匹配,缓存存放在一个引用表(Key-Value)中,通过一个哈希值引用,哈希值Key是查询预计,包含查询本身、当前要查询的数据库、客户端协议的版本等一些其他可能影响返回结果的信息,当判断缓存是否命中时,mysql不会进行解析查询语句,而是直接使用SQL语句和客户端发送够来的其他原始信息。因此任何字符上的不同,比如空格、注释等都会导致缓存的不命中,如果匹配,验证当前用户是否具备查询权限,如果权限验证通过,直接返回结果集(Value)给客户端,如果不匹配则继续向下执行。
4)新版本去除缓存的原因:查询缓存失效在实际业务场景中可能会很频繁,因为对一个表更新这个表的所有查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。 -
分析器:没有命中缓存的话,SQL语句就会经过分析器,检查语句语法是否正确。
1)提取关键字,提取查询表、字段名、查询条件等。
2)判断是否符合mysql语法。 -
优化器:按照MySQL认为最优的方案执行。
-
执行器:执行语句,然后从存储引擎返回数据。
执行前还需要判断用户权限,如果有权限就调用引擎的接口返回执行结果;如果没有权限就会返回错误信息。
- 存储引擎层:
负责数据的存储和读取,采用可以替换的插件式架构,支持MyISAM、InnoDB、Memory等多个存储引擎。从MySQL5.5.5版本开始InnoDB被当作默认存储引擎,InnoDB引擎有自己的日志模块。
三、日志模块
执行语句更新的时候需要引入日志模块。Mysql自带日志模块binlog(归档日志),所有存储引擎都可以使用;InnoDB引擎也自带日志模块redolog(重做日志)。一条更新语句流程我们可以归纳如下:
1)查询该条数据是否有缓存,如果有则用缓存。
2)拿到查询语句,调用引擎接口,写入数据,InnoDB引擎把数据保存在内存中,同时记录redolog,此时redolog进入prepare状态,然后告诉执行器,执行完成了,可以提交。
3)执行器收到通知后记录binlog,调用引擎接口提交redolog为提交状态。
4)更新完成。
问1:为什么要用两个日志模块,用一个日志模块不行吗?
最开始 MySQL 并没与 InnoDB 引擎( InnoDB 引擎是其他公司以插件形式插入 MySQL 的) ,MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
问2:如何通过redolog和binlog保证数据的一致性?
由MySQL的处理机制保证。
1)判断redolog是否完整,如果完整就立即提交。
2)如果redolog只是预提交但不是commit状态,需要判断binlog是否完整,如果完整就提交redolog,不完整就回滚事务。