Map-Reduce简介
map-reduce是hadoop中第二个核心,用于对hdfs中的文件做映射-归集处理。map阶段可以将文件中的数据以行的方式读取出来处理成想要的基本数据类型或者自定义数据类型,生成key-value到文件中,reduce阶段拿到已做过分组的key-value(多值),然后可以对value循环做分组操作。灵活的使用key可以完成非常强大的功能。
适合处理离线大批量数据的场景,不过编写代码有点麻烦,后面有了hive提供的sql接口,使用hql可以像写sql一样操作数据,不用再写繁琐的mr代码。但是hive并不是万能的,面对杂乱无章的数据文件,还是需要编写特定的mr程序做数据清洗,入到hdfs后方便hive操作
MR工作流程
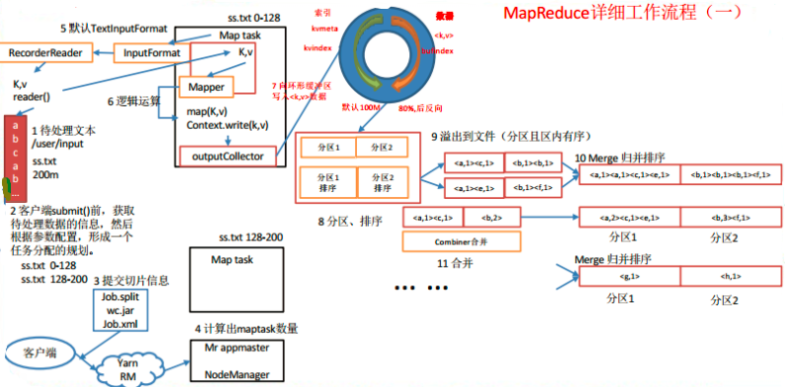
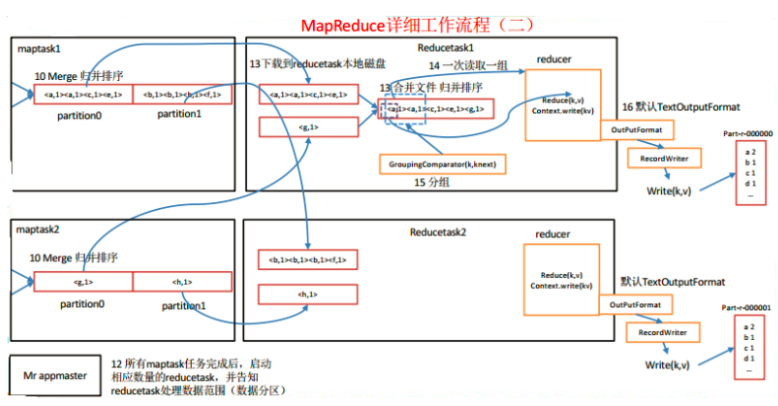
工作流程说明:
1.在HDFS中准备好要处理的文件,大小200M
2.与NameNode交互拿到文件信息,形成一个任务分配的规划
3.提交运行所需资源到HDFS中
4.与ResourceManager交互,申请mr-AppMaster,由mr-AppMaster向ResouceManage申请执行MapTask和ReduceTask,有多少个切片就有多少个MapTask,ReduceTask依赖与分区数
5.MapTask通过InputFormat->RecordReader(图中的RecorderReader是错误的)读取文件到内存。默认是TextInputFormat,也可以自定义InputFormat和RecordReader
6.由自己编写的Mapper对内存中的文件一行行的进行处理,比如将一行的数据转换为自定义的对象,然后做出value输出给ReduceTask。如果没有配置ReduceTask阶段,那么就会通过OutputCollector输出文件到hdfs中
7.有ReduceTask,Mapper会将数据送到环形缓冲区,由缓冲区决定什么时候批量将数据写入到磁盘中。默认缓冲区使用到80%,缓冲区的数据经过分区和排序就会溢出写到磁盘文件中。设计一个缓冲区在这里可以极大的提高性能
a.写内存比写磁盘快太多
b.数据批量从内存写到磁盘,可以提高数据在磁盘中存放的集中程度,不论是写还是以后的读都会很有帮助
c.如果没有达到溢出的条件,ReduceTask直接从内存中拿数据
8.对将要溢出的数据进行分区和排序
9.溢出数据写到磁盘文件中
10.对溢出的多份数据做归并和排序,形成新的文件
11.如果设置了combiner(需要自定义),则会进行工作,它的作用将前面的内容进一步做聚合,减少磁盘开销和网络传输时间
12.待MapTask结束,启动ReduceTask任务(这个不是绝对的,有配置可以干预ReduceTask启动触发条件)
13.从各个MapTask任务哪里拿到需要做Reduce的数据(内存或者文件),并做合并
14.对数据做分组(分组的字段为MapTask的输出key)----此处和图中有出入,以文字描述为准
15.读取合并后的数据,做Reduce操作----此处和图中有出入,以文字描述为准
16通过OutputFormat->RecordWriter把数据写到hdfs的文件中。默认是TextOutputFormat,可以自定义OutputFormat和RecordReader,比如根据不同的业务,将数据输出到不同的文件中。
YARN作业提交流程
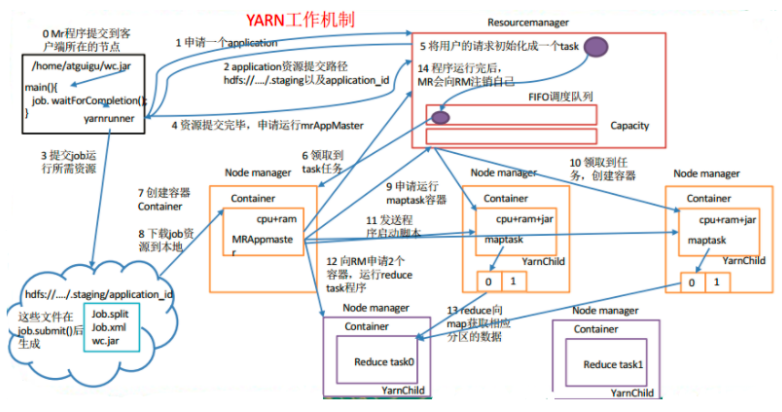
0.Mr 程序提交到客户端所在的节点。 1.Yarnrunner 向 Resourcemanager 申请一个 Application。 2.rm 将该应用程序的资源路径返回给 yarnrunner。 3.该程序将运行所需资源提交到 HDFS 上。 4.程序资源提交完毕后,申请运行 mrAppMaster。 5.RM 将用户的请求初始化成一个 task,该task会放入FIFO队列中(task是客户端提交的job,不是maptask和reducetask)。 6.其中一个 NodeManager 领取到 task 任务。 7.该 NodeManager 创建容器 Container, 并产生 MRAppmaster。 8.Container 从 HDFS 上拷贝资源到本地。 9.MRAppmaster 向 RM 申请运行 maptask 资源。 10.RM 将运行 maptask 任务分配给另外两个 NodeManager, 另两个 NodeManager 分别领取任务并创建容器。 11.MR 向两个接收到任务的 NodeManager 发送程序启动脚本, 这两个 NodeManager 分别启动 maptask, maptask 对数据分区排序。 12.MrAppMaster 等待所有 maptask 运行完毕后,向 RM 申请容器, 运行 reduce task。 13.reduce task 向 maptask 获取相应分区的数据。 14.程序运行完毕后, MR 会向 RM 申请注销自己。
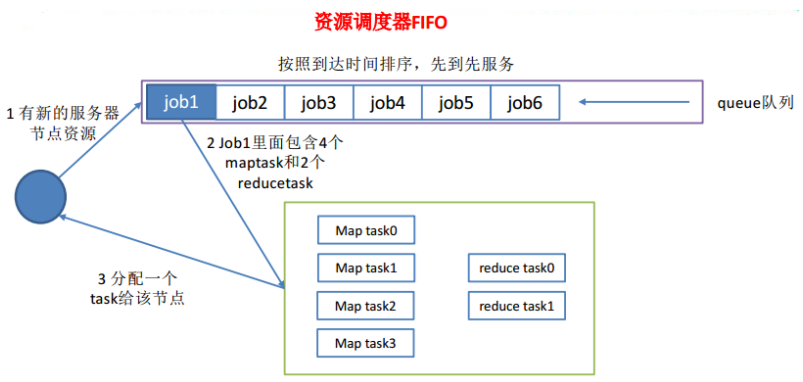
FIFO调度器
先进先出调度器先按照作业优先级高低,再按照提交时间顺序依次执行。
容量调度器

容量调度器包含多个队列,每个队列分配一定比例的硬件资源,每个队列采用FIFO策略,同一用户的作业所占资源会被限制,防止该用户独占计算资源。当一个作业提交上来时,按照如下策略进行:
1.计算每个队列中正在运行的任务数与该队列所分配资源比值,选择其中最小的队列
2.根据作业优先级和提交顺序,参考提交作业用户的资源限制重排队列内任务顺序,然后执行作业中的task
公平调度器
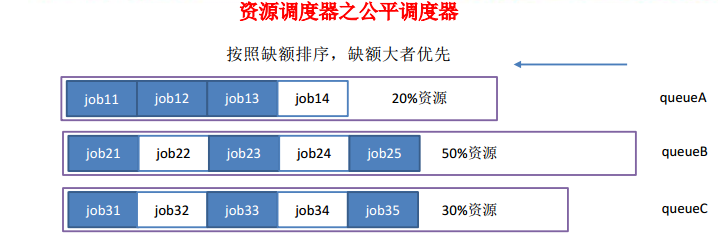
公平调度器包含多个队列,每个队列分配一定比例的硬件资源,每个队列采用缺额越大越优先执行的策略
缺额:每个作业理论上应该获得硬件资源与实际获得硬件资源的差值