import requests库和from bs4 import BeautifulSoup库
import requests
from bs4 import BeautifulSoup
requests库是用来访问网站http://
BeautifulSoup最主要的功能是从网页(html)抓取数据,然后分析数据
安装这些库,进入cmd控制台
pip install requests
pip install beautifulsoup4
如果下载的慢,可以采用清华的镜像
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple beautifulsoup4
这样库就导入成功了。前提准备已完成。
3.接下来,看代码部分,
首先我们要写个headers,headers中包含了我们的访问该网站的信息,user-agent表示我们用的处理器是什么,系统是什么等去模拟一个手动登入的状态(不然会被网站挡住的)Host表示请求的服务器网址
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'Host': 'movie.douban.com'
}
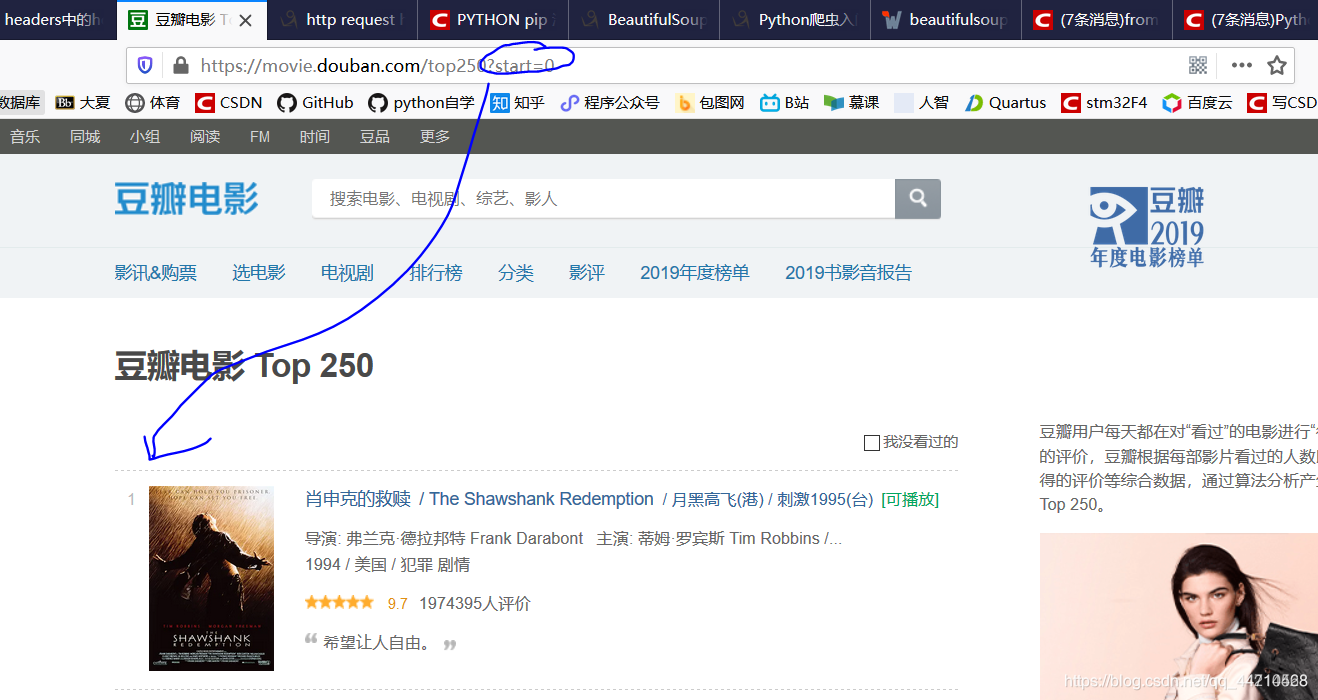
我们先看main函数:page=10,因为每个页面只能显示25部电影,所以250/25=10,然后for循环遍历访问,url的链接是重点
url = “https://movie.douban.com/top250?start=”+str(25*index)
这里要解释一下,豆瓣第1名到第25的页面是https://movie.douban.com/top250?start=0,第25名到第50名页面是https://movie.douban.com/top250?start=25,所以才是这样,然后我们通过getHTMLText(url)函数来解析html的网站,最后test(html,index)函数输出结果。
def main():
page=10
for index in range(page):
url = "https://movie.douban.com/top250?start="+str(25*index)
html = getHTMLText(url)
test(html,index)
main()
其次我们看一下getHTMLText函数:
首先调用**requests.get(url,headers,timeout)**函数,该方法会将headers和url拼接,然后发送网页请求。r.raise_for_status()是请求的状态码,r.encoding = r.apparent_encoding是将该网页的编码方式转为更准确的编码方式,之后返回解析后的文本return r.text
def getHTMLText(url):
try:
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
最后我们来看test(html,index)函数:
soup = BeautifulSoup(html,“html.parser”)用解析器来对网页解析,得到一碗soup汤。电影名字的标签在a的span class=‘title’ 中,通过find_all返回所有含标签的对象,然后对标签中去找寻span class中的string,也就是名字然后返回即可。顺便把得到的结果写在了F:\测试.txt中。
def test(html,page):
f1 = open(r'F:\测试.txt', 'a')
soup = BeautifulSoup(html,"html.parser")
alink = soup.find_all('a')
i=page*25
for index in range(len(alink)):
if alink[index].find('span',{"class":"title"})!=None:
print('第'+str(i+1)+'名'+'---'+alink[index].find('span', {"class": "title"}).string.rjust(20))
f1.write('第'+str(i+1)+'名'+'---'+alink[index].find('span', {"class": "title"}).string.rjust(20)+"\n")
i=i+1
详细代码如下:
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'Host': 'movie.douban.com'
}
def getHTMLText(url):
try:
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def test(html,page):
f1 = open(r'F:\测试.txt', 'a')
soup = BeautifulSoup(html,"html.parser")
alink = soup.find_all('a')
i=page*25
for index in range(len(alink)):
if alink[index].find('span',{"class":"title"})!=None:
print('第'+str(i+1)+'名'+'---'+alink[index].find('span', {"class": "title"}).string.rjust(20))
f1.write('第'+str(i+1)+'名'+'---'+alink[index].find('span', {"class": "title"}).string.rjust(20)+"\n")
i=i+1
def main():
page=10
for index in range(page):
url = "https://movie.douban.com/top250?start="+str(25*index)
html = getHTMLText(url)
test(html,index)
main()
