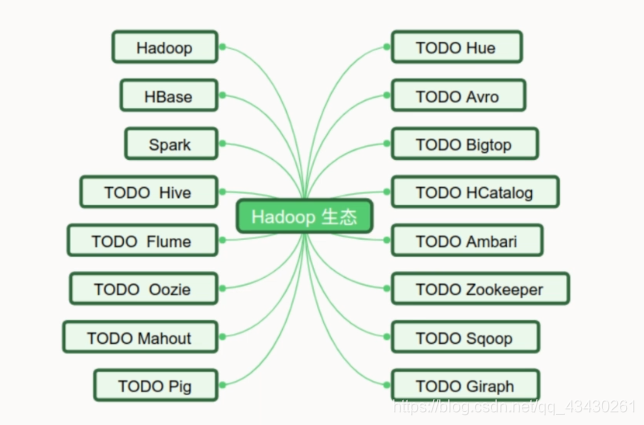
大数据系列(8)Hadoop生态简介


猜你喜欢
转载自blog.csdn.net/qq_43430261/article/details/105545115
今日推荐
周排行